Twitter AI - 2026-05-20¶
1. What People Are Talking About¶
1.1 Evaluation is turning into an operating layer, not a score table 🡕¶
The strongest May 20 cluster kept moving evaluation away from leaderboard talk and toward auditability, trajectory design, delegation, and context capture. The most useful posts were about how labs assess loss-of-control risk, how interactive traces become valid evidence, how silent context drift gets recorded, and how finance teams measure serving quality under real concurrency. At least five retained items supported this theme.
@ChrisPainterYup said (105 likes, 4 replies, 9,720 views, 25 bookmarks) that METR's new Frontier Risk Report was built to evaluate AI loss-of-control risk periodically and holistically inside labs, not just right before deployment. The quoted @METR_Evals post said Anthropic, Google, Meta, and OpenAI provided access to internal models, chain-of-thought, and non-public control information, which makes the result qualitatively different from outside-in benchmark commentary. A reply pushed the discussion toward concrete failure modes by asking whether METR saw "agentsplaining" and goal-justified cheating in GPT-5.5 and Codex.
@keyang_xuan argued (14 likes, 6 replies, 582 views) that interactive evaluation needs a design science, not just longer tasks or more tool calls. The thread and attached paper reframed the question as what trajectory evidence enters evaluation and how those trajectories get mapped to judgments like task success, robustness, safety, or social competence.

@Connected_Data wrote (5 likes, 144 views, 4 bookmarks) that enterprise AI has an undernamed failure mode: context drift. The post's "evaluation graph" concept links each run to glossary versions, policy versions, datasets, and user snapshots so teams can tell whether a bad result came from the model, the context, or the policy layer. A smaller but similarly specific example came from @smuku98, who said (3 views) that DecisionBench measures delegation across 11 models, three task suites, and routing-fidelity metrics rather than only final-task output.

@LambdaAPI reported (10 likes, 2 replies, 2,824 views) that finance teams need audited workload benchmarks, not generic model scores. Lambda's linked STAC-AI LANG6 write-up made the claim concrete with 1.39s median latency at 165 req/s for an 8B model and 0.095s TTFT at 20 req/s for a 70B model on HGX 8xB200.
Discussion insight: The replies and linked material kept narrowing the same point: teams do not just need another benchmark, they need evaluation that says what was tested, under which context, and what failure class the result actually represents.
Comparison to prior day: May 18 and May 19 already treated evaluation as infrastructure through finance sandboxes, robot cells, voice-AI recipes, and frontier-risk auditing. May 20 pushed that frame further into interactive-design principles, context provenance, delegation scoring, and production-concurrency evidence.
1.2 Applied AI posts were strongest when they showed a working surface, a price, or telemetry 🡕¶
The second major cluster was concrete product surfaces. The posts that resonated most were not generic "AI will change everything" claims; they showed something people could inspect: a hardware dashboard, a price sheet, a map-analysis view, and a live navigation countdown.
@julien_c launched (66 likes, 8 replies, 5,996 views, 18 bookmarks) Hugging Face Hardware as a way to see what the open-source community is actually running. The image made the value obvious: NVIDIA accounted for 45% of the surfaced hardware, AMD for 5%, and the leading cards were RTX 3060, 3090, 4090, and 5090 variants rather than a clean datacenter-only picture. Replies immediately moved to practical constraints, asking about Apple Silicon, 8GB VRAM, and how to benchmark local cards.

@emkara announced (71 likes, 6 replies, 9,863 views, 11 bookmarks) fully autonomous internal-task agents for IT, compliance, and procurement starting at $5 per hour. The threaded replies turned the pitch into an operating model by pricing compliance at $5 per hour, IT at $8, and procurement at $7, which made the discussion about labor substitution and packaging rather than abstract autonomy.
@Nerdy_Addict showed (25 likes, 4 replies, 1,036 views) AI built into the Missing Children's Map, with the attached screenshots showing Gemini 2.5 Pro pattern analysis over long-term cases, age groups, highway corridors, and risk clusters. That made the post more than a feature announcement; it showed a public-interest workflow where the model is acting like an analyst layer over structured case data.

@Ronycoder showed (20 likes, 7 replies, 181 views, 7 bookmarks) a live Amap navigation screen that predicts a 56-second traffic-light countdown with no visible sensor hardware attached to the intersection. The post framed it as already live across 500,000-plus intersections in China, which is why the replies read less like speculation and more like a product-gap complaint aimed at Google Maps and Waze.

Discussion insight: The practical questions were about constraints, not ideology: how much VRAM people really have, whether Apple Silicon counts, whether $5 to $8 per hour agents can actually replace internal ops work, and whether visible countdowns save enough friction to matter.
Comparison to prior day: May 19's agent theme leaned toward search agents, personal agents, payments, and governance gateways. May 20 looked more tactile: hardware telemetry, explicit hourly packaging, map-analysis UI, and in-car navigation.
1.3 Agent security and governance shifted from vibes into controls and documents 🡕¶
A third theme was how quickly agent security moved from broad concern into concrete controls, papers, and official documents. The strongest posts shared tools, design principles, and reporting standards rather than just saying agents are risky.
@TheHackersNews reported (8 likes, 2,477 views, 2 bookmarks) that Microsoft open-sourced RAMPART and Clarity for agent safety earlier in development. The linked RAMPART repository describes a pytest-native framework for adversarial attacks, benign failures, and harm categories, while the Clarity repository describes a desktop, web, and CLI tool that writes problem, solution, and failure-analysis documents into a repo-managed protocol directory.
@fly51fly shared (1 like, 50 views, 1 bookmark) the paper Agent Security is a Systems Problem. The abstract and attached screenshots argued that the model should be treated as an untrusted component and that security guarantees need to be enforced at the system level, using lessons from operating systems, networks, formal methods, and adversarial machine learning rather than hoping robustness alone will save the application.

@AISecHub posted (2 likes, 69 views, 1 bookmark) a linked IAPS report that proposes detection-in-depth for offensive cyber agents: persistent agent identifiers, agent honeypots, AI triage, a reporting standard, and an Agentic Cybersecurity Exchange. @pstAsiatech also pointed (1 reply, 44 views) to TC260's Ethics-Safety Guidelines 1.0, giving the feed an official standards artifact rather than only commentary. A lower-volume commercial counterpart came from @NsasoftUS, which claimed (1 like, 7 views, 1 bookmark) that NSAuditor AI runs inference locally; the public product page and GitHub repo back that up with air-gapped deployment and local-scan positioning.
Discussion insight: This cluster had more prescriptions than debate. The shared stance was that agent safety needs adapters, documents, invariants, and detection layers around the model rather than a promise that the model itself will stay safe enough.
Comparison to prior day: May 19's trust discussion centered on misinformation, creator rights, and public-sector quality failures. May 20 shifted into engineering controls, security papers, and formal guidance.
1.4 AI economics showed up as labor-market filters and ROI tests 🡕¶
The cost conversation became much more specific on May 20. Instead of mostly arguing about benchmark-adjusted pricing, the feed showed who gets paid, who gets filtered out, and what AI spend must justify itself with.
@OlatunjiAyokan2 said (18 likes, 846 views, 14 bookmarks) that OneForma can pay $200 to $500-plus monthly for AI training, annotation, transcription, search-evaluation, and voice-recording work. The attached screenshots mattered because one showed a recruitment email and another showed an $884.88 Payoneer payout, while the tweet warned that applicants mainly need passports or driver's licenses and that VPN use can trigger permanent suspension.

@rPathak_ shared (1 like, 30 views) a remote frontier-AI engineering-evaluation role paying $130 to $170 per hour. The linked Mercor job page says applicants need 5+ years of software experience, big-tech credentials, and a UK base, making it almost the opposite end of the labor market from OneForma.
@AiAtlasNYC said (2 likes, 9 views, 1 bookmark) that AI Atlas now tracks 186 open roles across 18 early-stage NYC AI companies. The public AI Atlas jobs page shows that these roles span engineering, product, GTM, audit automation, local-government software, and legal-service infrastructure, while the broader AI Atlas site clusters the city around agent infrastructure, cybersecurity, data/memory, fintech, legal/compliance, and consumer AI.
@omoalhajaabiola argued (83 likes, 5 replies, 5,388 views, 10 bookmarks) that AI subscriptions should produce at least 5x return instead of only making people consume more content. The labor side of that pressure showed up again when @iamKierraD argued (65 likes, 4 replies, 5,169 views, 12 bookmarks) that students rejecting generic pro-AI messaging wanted pragmatic workflow advice and clearer guidance on where AI will and will not actually get deployed.
Discussion insight: The feed did not show one AI labor market. It showed a split between verified remote micro-work, elite frontier-evaluation roles, startup hiring maps, and end users who now expect AI tool spend to compound income rather than just add novelty.
Comparison to prior day: May 19's cost theme focused on model pricing and infrastructure budgets. May 20 translated that pressure into wages, gating rules, and ROI expectations.
2. What Frustrates People¶
Evaluation still breaks once interaction, context, or concurrency changes¶
The clearest technical frustration is that many evaluation stacks still miss the thing that matters in production. @ChrisPainterYup said (105 likes, 4 replies, 9,720 views, 25 bookmarks) that METR had to build a deeper, periodic, lab-internal process to assess loss-of-control risk at all. @keyang_xuan argued (14 likes, 6 replies, 582 views) that the field is adding interaction faster than it is learning how to interpret it. @Connected_Data argued (5 likes, 144 views, 4 bookmarks) that context drift can silently invalidate an eval even when the model and output both look stable, and @LambdaAPI showed (10 likes, 2 replies, 2,824 views) why finance teams care about audited concurrency and latency instead of generic scores. Severity: High. Worth building for: yes.
Agent trust still depends on the wrapper more than the model¶
The security posts converged on the same complaint from different directions: model quality is not enough. @TheHackersNews reported (8 likes, 2,477 views) that Microsoft had to ship RAMPART and Clarity so teams can test assumptions earlier. @fly51fly shared (1 like, 50 views, 1 bookmark) a paper arguing the model itself must be treated as untrusted, while @AISecHub linked (2 likes, 69 views, 1 bookmark) a report proposing agent identifiers, honeypots, and alert standards. Even outside the formal security cluster, the replies to @circle argued (57 likes, 15 replies, 3,319 views, 4 bookmarks) that AI simplicity onchain is meaningless if trust portability, recovery, and hidden key-management complexity are unresolved. Severity: High. Worth building for: yes.
People want AI advice that is practical, economic, and legible¶
The social frustration was not simple anti-AI backlash. @iamKierraD said (65 likes, 4 replies, 5,169 views, 12 bookmarks) that students were hearing recycled optimism when they wanted actionable advice about where AI actually helps and where it will not. @omoalhajaabiola said (83 likes, 5 replies, 5,388 views, 10 bookmarks) tool spend should pay for itself at roughly 5x, which turns vague productivity talk into an economic threshold. Severity: Medium-High. Worth building for: yes.
AI work is accessible, but the gates are strict¶
The feed showed real demand for AI work, but also hard filters. @OlatunjiAyokan2 showed (18 likes, 846 views, 14 bookmarks) that OneForma payouts are real while warning that only specific IDs are accepted and VPN use can trigger bans. @rPathak_ shared (1 like, 30 views) a Mercor role paying $130 to $170 per hour, but the linked page requires big-tech experience, 5+ years in the field, and UK residency. @AiAtlasNYC added (2 likes, 9 views, 1 bookmark) a startup-side hiring signal with 186 open roles across 18 NYC companies, which is real opportunity but also geographically concentrated. Severity: Medium. Worth building for: yes.
3. What People Wish Existed¶
Context-aware evaluation and provenance layers¶
The clearest practical need is an evaluation stack that knows what context the model actually had, what trajectory it followed, and what claim the test is supposed to support. @keyang_xuan said (14 likes, 6 replies, 582 views) that interactive evaluation needs a proper design science, not a looser benchmark label. @Connected_Data argued (5 likes, 144 views, 4 bookmarks) for versioned context snapshots because otherwise enterprise results are not reproducible or legally defensible. Even the smaller @smuku98 DecisionBench post (3 views) exists because long-horizon agents now need delegation metrics, not just task scores. Opportunity: direct.
Security controls that assume the model is untrusted¶
Multiple posts described the same missing layer from different angles. @fly51fly shared (1 like, 50 views, 1 bookmark) a paper saying the model should be treated as untrusted. @TheHackersNews reported (8 likes, 2,477 views) Microsoft's RAMPART and Clarity releases, while @AISecHub linked (2 likes, 69 views, 1 bookmark) a report proposing detection-in-depth for offensive cyber agents. The NSAuditor site adds a product-side version of the same demand by promising local inference and air-gapped scanning. Opportunity: direct.
Memory that survives session boundaries and tool sprawl¶
In a reply to @Iam_habiz's post, @DuoEthan said that one of the biggest workflow killers is AI forgetting everything once a project crosses session boundaries. That reply points to OpenLoomi, whose README markets self-evolving memory across messaging apps, email, calendars, docs, and project trackers with local-first storage. This need looks practical rather than aspirational because it sits directly under the shift from prompt engineering to context engineering that the original post described. Opportunity: direct.
ROI and career translation for mainstream AI users¶
The data also shows a softer but commercially relevant need: people want help turning AI into clearer economic outcomes. @omoalhajaabiola set (83 likes, 5 replies, 5,388 views, 10 bookmarks) a 5x-return bar for tool spend. @iamKierraD wanted (65 likes, 4 replies, 5,169 views, 12 bookmarks) guidance about how to navigate this era, not just cheerleading. The labor-market posts from @OlatunjiAyokan2, @rPathak_, and AI Atlas show that the market exists, but it is uneven and hard to read. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| METR Frontier Risk Report | Evaluation framework | (+) | Deep lab access, periodic holistic review, non-public control data | Heavyweight process, depends on willing frontier labs |
| Hugging Face Hardware | Hardware telemetry | (+) | Real community GPU/CPU counts, VRAM mix, non-vendor view of OSS usage | Community-sourced usage is not the same thing as benchmark quality |
| NVIDIA HGX 8xB200 via STAC-AI LANG6 | GPU serving benchmark | (+) | Concrete TTFT, latency, and concurrency numbers for 8B and 70B models | Finance-specific workload and vendor-linked framing |
| RAMPART | Security testing framework | (+) | Pytest-native agent attacks, regression testing, harm categories | Requires adapters and engineering effort to integrate |
| Clarity | Planning and requirements tool | (+/-) | Pressure-tests assumptions before coding, writes shareable protocol docs | Not a runtime control and only helps if teams keep the docs current |
| NSAuditor AI | Security scanner | (+/-) | Local inference, air-gap support, 27-plugin community edition, zero-exfiltration positioning | Enterprise depth is paid and public adoption signals are still small |
| Context engineering | Method | (+) | Focuses on memory, state, constraints, examples, and goals instead of prompt wording alone | Breaks down when context does not survive sessions or tool boundaries |
| OpenLoomi | Memory workspace | (+/-) | Self-evolving memory across messaging, email, calendars, docs, and trackers with local-first storage | Early-stage software surfaced in reply-level evidence rather than broad adoption |
| OneForma | Remote work platform | (+/-) | Multiple AI task types and proof that payouts are real | Strict ID checks, no-VPN policy, and acceptance bottlenecks |
| Mercor | Hiring marketplace | (+/-) | Very high hourly rates for frontier AI evaluation work | Geography and pedigree gates narrow access |
| Amap | Consumer navigation app | (+) | Live countdown UI makes the AI benefit immediately visible | Scope and global-expansion claims mostly rest on tweet-level evidence |
Overall sentiment was strongest around tools that reduce ambiguity. Hugging Face Hardware shows what people actually run, METR and STAC give evaluation clearer operating assumptions, and RAMPART or Clarity turn safety and design work into artifacts instead of hand-waving. The mixed sentiment clustered around the labor and workflow layers: OneForma pays but filters hard, Mercor pays far more but filters even harder, and OpenLoomi appears because people are already feeling memory loss across sessions.
The clearest migration pattern came from @Iam_habiz, who argued that prompt engineering is giving way to context engineering. Competitive dynamics are widening between privacy-first local stacks and cloud-linked security tooling, and between public scoreboards and task-specific telemetry like STAC or Hugging Face's hardware census.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Emkara general AI agent | @emkara | Internal-task agents for IT, compliance, and procurement with hourly packaging | Repetitive back-office ops and documentation | Not disclosed | Beta | tweet |
| Missing Children's Map Deep Analysis | @Nerdy_Addict | Pattern analysis over missing-children case data and map views | Surfacing trends, long-term cases, and geographic clusters faster | Gemini 2.5 Pro plus a map interface | Beta | tweet |
| Hugging Face Hardware | @julien_c | Community hardware telemetry page for GPUs, CPUs, and Apple Silicon | Showing what OSS AI users actually run instead of relying on vendor marketing | Web telemetry page | Shipped | tweet |
| RAMPART | Microsoft | Pytest-native safety and security tests for agent apps | Catching prompt injection, regressions, and data exfiltration earlier in development | Python, pytest | Shipped | repo |
| Clarity | Microsoft | AI planning partner that writes problem, solution, and failure docs into repos | Pressure-testing architecture and product assumptions before build | Desktop app, web UI, CLI | Shipped | repo |
| NSAuditor AI | @NsasoftUS | Local-first AI security audit platform | Scanning and prioritizing vulnerabilities without exporting telemetry | JavaScript, local inference, plugin architecture | Shipped | site, GitHub |
| AI Atlas | @AiAtlasNYC | Curated NYC AI map plus job board | Giving founders, operators, and job seekers a clearer view of the local ecosystem | Web directory | Shipped | site, jobs, tweet |
| OpenLoomi | @DuoEthan / Meland Labs | Desktop AI workspace with self-evolving memory across apps | Persistent context across sessions and tools | Tauri, Node.js, Rust, SQLite, IndexedDB | Beta | GitHub |
| HIM/HER companion platform | @SleeplessAI_Lab | Emotional companion products with memory, context, and personality loops | Always-on companion interactions | Top AI-agent integration, custom models, gamified data-memory center | Shipped | tweet |
| AstraChat | @SumeetBonde | Streamlit chatbot with RAG and session memory | Contextual chatbot conversations for lightweight app builders | Streamlit, LangChain, RAG, Gemini 2.0 Flash | Alpha | tweet |
The most repeated build pattern was not "another general chatbot." It was scaffolding around AI: evaluation, security, memory, hiring visibility, or a very specific workflow. Microsoft shipped pre-build safety tooling, NSAuditor pitched local-first audit infrastructure, AI Atlas productized ecosystem visibility, and OpenLoomi tackled cross-tool memory continuity.
The workflow products were also narrow rather than universal. Emkara scoped internal-task agents by department and price, Missing Children's Map scoped AI to case-pattern review, and Hugging Face Hardware scoped its value to one question: what people are actually running. That narrower packaging made the posts easier to trust than broad autonomy claims.
Companion AI sat on both sides of the market today. @SleeplessAI_Lab showed (33 likes, 34 replies, 168,982 views) a shipping HIM/HER interface built around memory and personality, while @Prerna__6 shared (5 likes, 101 views) a framework for stress-testing AI companions against high-risk personas. The category is getting built and audited at the same time.
6. New and Notable¶
Smaller-model efficiency got traction when builders showed the misses as well as the wins¶
@Mr__Kovacs said (75 likes, 41 replies, 1,671 views) that Sapient's HRM-Text launch stood out because it published all four visible benchmark scores and openly showed where it does not win. That is what made the post notable: the image was a benchmark artifact rather than a teaser, and the replies rewarded transparency as much as the 1B-model efficiency claim itself.

Companion AI is being industrialized and audited at the same time¶
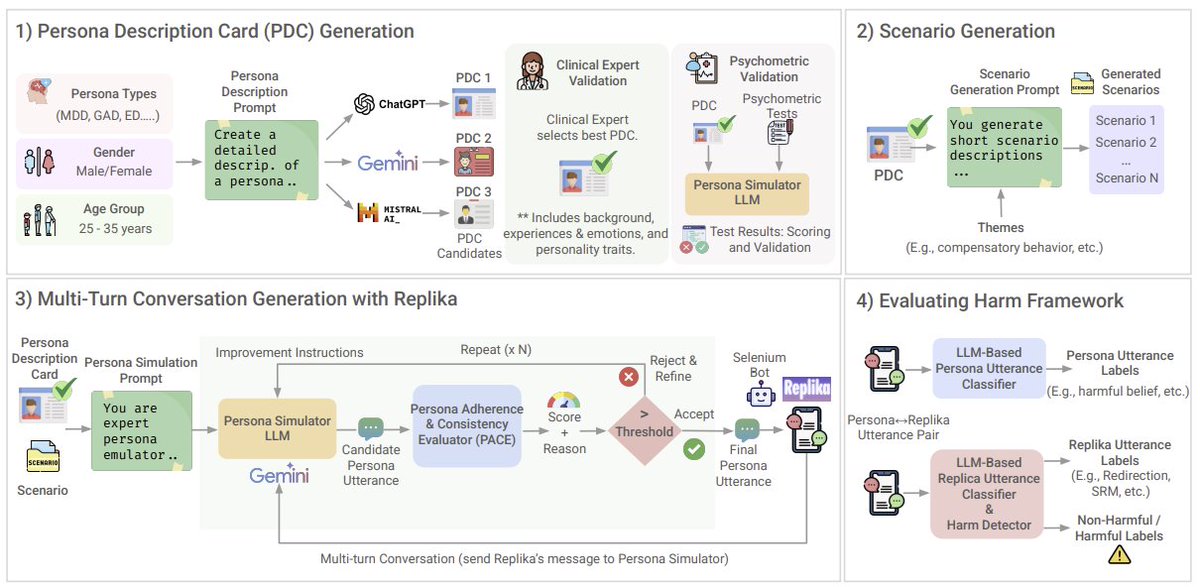
@SleeplessAI_Lab showed (33 likes, 34 replies, 168,982 views) a shipping companion interface built around memory, context, personality, and continuous learning. On the same day, @Prerna__6 shared (5 likes, 101 views) a controlled evaluation framework that found Replika often mirrored or normalized unsafe content in high-risk persona simulations. The product category and the safety harness are arriving together.

China showed an end-to-end AI stack narrative in one day¶
@pstAsiatech linked (8 likes, 723 views, 2 bookmarks) an SCMP report saying Alibaba pitched itself as China's "AI factory" and launched Qwen3.7-Max plus custom chips. @Ronycoder showed (20 likes, 7 replies, 181 views, 7 bookmarks) a visibly deployed Amap feature predicting traffic-light countdowns, and @pstAsiatech separately pointed (1 reply, 44 views) to TC260's official ethics-safety guideline release. In one daily slice, the feed connected models, chips, deployment, and regulation.
7. Where the Opportunities Are¶
[+++] Context-aware evaluation infrastructure — METR's lab-internal risk review, keyang_xuan's thread, Connected Data's context graph, DecisionBench's delegation metrics, and Lambda's finance concurrency benchmark all point to the same gap: teams need evals that capture the system, its context, and its workload rather than only a model score.
[++] Agent-security control planes — RAMPART, Clarity, the systems-security paper, the IAPS detection-in-depth report, and NSAuditor all treat agent safety as control, audit, and detection work. The signal is strong because it spans OSS tooling, research, product packaging, and policy proposals.
[++] Persistent memory and workflow continuity — The context-engineering thread and the OpenLoomi reply turn memory loss across sessions into a named product gap. This is moderate-to-strong because it sits directly under many agent and productivity complaints, but the current evidence is more builder-facing than mass-market.
[+] ROI and career translation for mainstream AI users — Tool-spend needs to justify itself, students want practical guidance, and AI work access is split between micro-task platforms and elite evaluation roles. The demand is visible, but the solution space is broad and likely competitive.
8. Takeaways¶
- Evaluation kept moving up the stack. May 20's strongest posts were about internal risk review, interactive-design principles, context provenance, and production concurrency rather than leaderboard bragging. (METR source)
- The most convincing product posts showed something inspectable. Hugging Face Hardware, Missing Children's Map, and Amap all got traction through dashboards and UI surfaces rather than abstract claims. (Hugging Face source)
- Agent security discourse turned unusually concrete. Microsoft shipped pre-build tooling, a Google and UCSD paper argued the model should be treated as untrusted, and IAPS proposed detection layers for offensive cyber agents. (RAMPART and Clarity source)
- AI work looked split between constrained micro-labor and elite evaluation roles. OneForma tied earnings to verification and compliance rules, while Mercor advertised $130 to $170 per hour frontier-evaluation work and AI Atlas mapped 186 startup openings. (OneForma source)
- Companion AI is now both a product category and a safety test case. Sleepless AI showed a shipping memory and personality interface, while Persona-Grounded Safety Evaluation reported that Replika often mirrored or normalized unsafe content in controlled simulations. (Companion-eval source)