Twitter AI - 2026-05-21¶
1. What People Are Talking About¶
1.1 Benchmarks lost authority unless they map to real workflows or usable products 🡕¶
The strongest cluster treated benchmark discourse as incomplete rather than decisive. The retained posts argued that interactive evaluation needs explicit design principles, that scientific agent evaluation should use real workflows with programmatic verification, that variable reasoning time breaks single-number scorecards, and that users care more about whether AI fixes email or apps than whether it wins another leaderboard. At least four high-signal items supported this theme.
@keyang_xuan argued (27 likes, 9 replies, 2,282 views, 15 bookmarks) that interactive evaluation requires a design science, not just longer trajectories or more tool use. The thread said the evaluation problem has to specify what trajectory evidence counts and how those trajectories map to judgments like robustness, recoverability, safety, or social competence. The attached paper page makes that concrete by framing interactive evaluation as a principled paradigm with reporting standards rather than a loose benchmark label.

@sanmikoyejo said (8 likes, 405 views, 3 bookmarks) that "AI for science" benchmarks still mostly test textbook recall and pointed to Terminal-Bench Science, which is collecting real scientific workflows in containerized environments with pytest-based verification. That matters because it turns benchmark construction into a contribution process for practicing scientists instead of a closed set of toy tasks.
@haider1 reported (53 likes, 8 replies, 3,433 views, 10 bookmarks) that Noam Brown said single-number benchmarks no longer make sense for reasoning models because performance now depends on how much reasoning time the system gets. A reply sharpened the skepticism by noting that benchmark criticism sounds convenient when the same lab is winning on the hardest-to-measure models.
@boneGPT argued (76 likes, 16 replies, 3,639 views, 9 bookmarks) that teams should stop "benchmaxxing" and start "productmaxxing," using Gmail as the example: users want memories, rules, and reliable reply templates, not another fractional benchmark gain. The replies moved quickly from theory to execution gaps, complaining that phone and app assistants still fail at simple cross-app actions.
Discussion insight: The replies did not reject evaluation; they rejected evaluation that does not explain workflow quality, product usefulness, or the conditions under which a model was given extra reasoning time.
Comparison to prior day: May 20 already treated evaluation as infrastructure through METR, STAC, and context-provenance posts. May 21 pushed harder against leaderboard-style abstraction and toward workflow-grounded tasks, variable-compute evaluation, and product usefulness.
1.2 Compute access and local execution are becoming the real divider between chatbots and agents 🡕¶
The second theme was compute as access control. The evidence spanned academic institutions that cannot pool budgets, builders who want local machines instead of cloud calls, and benchmark screenshots that show what small GPUs can actually sustain. At least five retained items supported this theme.
@emollick wrote (96 likes, 19 replies, 5,902 views, 12 bookmarks) that compute scarcity will make complex agentic workflows expensive even as single-turn chatbots get cheaper. His follow-up reply said everyone may get strong free chatbots while the best agents become reserved for workloads that can afford thousands of times more tokens, framing the split as a democratization problem rather than just a pricing problem.
@MilkRoadAI said (36 likes, 6 replies, 4,427 views, 12 bookmarks) that Jensen Huang's prescription for university AI access is pooled purchasing, not more complaints about shortages. The thread argued that institutions like Stanford need centralized shared compute because individual departments cannot buy billion-dollar infrastructure one grant at a time.
@ClementDelangue said (43 likes, 5 replies, 1,964 views, 3 bookmarks) that AI builders need more local hardware and floated the idea of a Hugging Face box after AMD's Ryzen AI Halo launch. Replies immediately asked for preloaded models and clearer hardware packaging, showing that the demand is not just ideological local-first talk but product requirements.
@TheAhmadOsman showed (92 likes, 10 replies, 8,492 views, 148 bookmarks) that a local Qwen3.5-9B setup on an RTX 3070 8 GB card can reach a stable q8_0 profile at 180,224 context and 54.45 tokens per second. The screenshot turned a vague "local AI is easy" claim into concrete tradeoffs around KV cache, batch size, and failure points at the edge of VRAM.

@latentspacepod highlighted (16 likes, 1 reply, 2,711 views, 4 bookmarks) a Daytona interview arguing that agents need stateful computers, not disposable code-execution boxes. The linked piece claimed ~60 ms sandbox startup, 50,000 sandboxes in ~75 seconds, and a customer running ~850,000 sandboxes a day, which makes agent-native compute look like a new infrastructure class rather than another devtools wrapper.
Discussion insight: The replies focused on packaging and access: who can get pooled compute, what local box is enough, what should ship preloaded, and what workloads break the cloud-only assumption.
Comparison to prior day: May 20's compute discussion centered on telemetry and benchmarked serving. May 21 translated that into scarcity, pooled purchasing, local boxes, and agent-native computers.
1.3 Safety and governance conversation kept moving toward controls, protocols, and public vetting ��¶
The third theme was operationalization: concrete safety tools, repo-managed decision records, national evaluation capacity, and state review before release. The strongest examples were lower-volume than the compute discourse, but they were unusually specific about what the control layer should do.
@TheTuringPost said (5 likes, 2 replies, 399 views, 3 bookmarks) that Microsoft's new RAMPART and Clarity releases are built for repeatable attack scenarios in CI and structured system design before code ships. The architecture graphic matters because it shows the full stack: tools, external data sources, LLM engine, agent adapter, pytest suite, attack and probe layers, evaluators, reporting, and the PyRIT foundation underneath.

@CSOonline reported (3 likes, 48 views, 1 bookmark) that the same Microsoft push is about making safety a continuous engineering discipline. The linked article says RAMPART turns red-team findings into CI/CD tests while Clarity writes structured assumptions and failure analysis into a .clarity-protocol/ directory that can be reviewed like code.
@washingtonpost reported (18 likes, 14 replies, 7,910 views) that the U.S. government was expected to create a system for vetting powerful new AI models before public release. @Rudra_81 argued (14 likes, 2 replies, 5,129 views, 7 bookmarks) that India needs its own AI regulation, safety institute, and evaluation capabilities rather than reacting to other countries' governance moves.
Discussion insight: The strongest disagreement was not whether controls are needed, but which institution should own them: vendors, open-source toolchains, national governments, or new public evaluation bodies.
Comparison to prior day: May 20 brought agent security closer to engineering controls. May 21 extended that into CI-tested safety stacks, repo-level decision protocols, and government vetting mechanisms.
1.4 AI economics looked less like pricing talk and more like capital allocation and workforce adaptation 🡕¶
The fourth cluster mixed capital intensity, labor interpretation, and corporate adaptation. The posts did not agree on whether AI is a bubble, but they did converge on one point: the economics are no longer legible through model pricing alone.
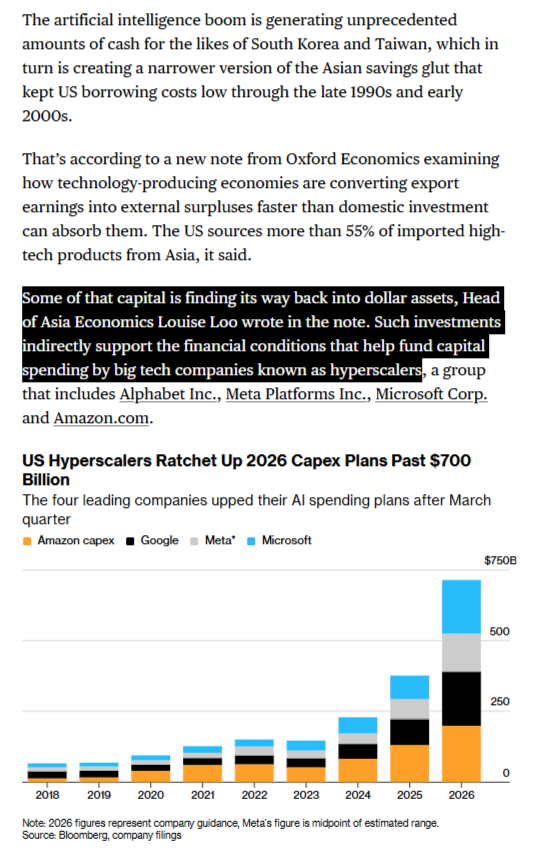
@scottlincicome shared (9 likes, 2 replies, 3,967 views) a Bloomberg note arguing that Asian export surpluses from AI hardware are feeding back into U.S. AI capex. The attached chart said the four leading hyperscalers had pushed 2026 AI capex plans above $700 billion, making the capital cycle itself part of the day's AI conversation.
@1CoastalJournal warned (8 likes, 3 quotes, 1,958 views) of an "AI LLM ROI Problem" and attached a slide claiming an AI segment with $3.201 billion in 2025 revenue against $12.727 billion in AI capex, or roughly $4 of capex for every $1 of AI sales. @cremieuxrecueil added (43 likes, 3 replies, 5,344 views) a labor-market correction by arguing that the decline in junior hiring may be getting conflated with work-from-home trends rather than driven by GenAI alone.
@binance said (209 likes, 93 replies, 37,801 views) that it is responding to AI-driven job-market change by training staff, sharing internal use cases, and continuing to hire across 380+ roles. The replies split between "AI is a tool that raises efficiency" and cynicism that workers are being trained to keep up with the systems replacing them.
Discussion insight: The day did not show one clean AI jobs narrative. It showed firms training and hiring, critics warning about capex burn, and others arguing that AI is being blamed for employment shifts with other causes.
Comparison to prior day: May 20 focused on wages, subscription ROI, and labor-market filters. May 21 zoomed out to hyperscaler capex loops, ROI skepticism, and how employers are restructuring around AI adoption.
2. What Frustrates People¶
Benchmark wins still do not explain whether the product is good¶
People are visibly tired of abstract benchmark talk that does not predict whether an assistant can handle a real workflow. @boneGPT argued (76 likes, 16 replies, 3,639 views, 9 bookmarks) that Gmail still lacks memories, rules, and stable reply templates despite endless benchmark chatter, @haider1 reported (53 likes, 8 replies, 3,433 views, 10 bookmarks) that reasoning models change with allotted compute, and @keyang_xuan argued (27 likes, 9 replies, 2,282 views, 15 bookmarks) that interactive evaluation becomes loose and hard to interpret without a principled mapping from trajectories to claims. Severity: High. The current workaround is to build domain-specific task sets like Terminal-Bench Science or ignore leaderboard deltas altogether.
Advanced agents look budget-gated¶
The most repeated economic frustration is that serious agents may be available only to whoever can afford long-running compute. @emollick made (96 likes, 19 replies, 5,902 views, 12 bookmarks) that split explicit, @MilkRoadAI framed (36 likes, 6 replies, 4,427 views, 12 bookmarks) university access as a pooled-budget problem, and replies to @ClementDelangue's post and @TheAhmadOsman's local benchmark post turned the discussion into VRAM ceilings, preloaded models, and what hardware counts as enough. Severity: High. People are coping with smaller local models, hand-tuned inference settings, or new agent-compute providers like Daytona.
The control layer around agents is still thin¶
The RAMPART/Clarity posts, the Washington Post vetting story, and @Rudra_81 arguing (14 likes, 2 replies, 5,129 views, 7 bookmarks) for an Indian safety institute all complain about the same gap: many organizations still lack repeatable processes for testing tool use, documenting assumptions, and reviewing powerful systems before they ship. @CSOonline reported (3 likes, 48 views, 1 bookmark) that prompt injection, unsafe tool use, privilege escalation, and unintended autonomous actions do not fit neatly into traditional app-sec workflows. Severity: High. Current coping behavior is ad hoc: CI safety tests, markdown protocol files, or calls for public vetting.
The AI economy is sending mixed signals¶
The same day showed @binance training and hiring (209 likes, 93 replies, 37,801 views), @scottlincicome sharing (9 likes, 2 replies, 3,967 views) a hyperscaler capex surge chart, @1CoastalJournal warning (8 likes, 3 quotes, 1,958 views) that AI capex is outrunning AI revenue, and @cremieuxrecueil arguing (43 likes, 3 replies, 5,344 views) that junior hiring decline may be getting misattributed to GenAI. Severity: Medium-High. The frustration is not just fear of AI; it is that buyers, workers, and operators cannot easily tell whether they are looking at durable productivity or an expensive transition period.
3. What People Wish Existed¶
Product-grade workflow AI instead of benchmark theater¶
What people are asking for is not another benchmark winner; it is an assistant that behaves predictably inside an actual workflow. @boneGPT wanted (76 likes, 16 replies, 3,639 views, 9 bookmarks) Gmail memories, rules, and reply templates, while @haider1 amplified (53 likes, 8 replies, 3,433 views, 10 bookmarks) the point that reasoning models do not have a single stable score anyway. This is a practical and urgent need. Flash models and narrower assistants partially address it today, but the feed still treats the "obvious" email and app-control layer as unsolved. Opportunity: direct.
Shared compute pools and packaged local AI boxes¶
The compute posts describe a middle layer that still does not quite exist: something easier than DIY tuning but cheaper and more private than permanent cloud dependence. @MilkRoadAI argued (36 likes, 6 replies, 4,427 views, 12 bookmarks) for pooled institutional compute, @ClementDelangue asked (43 likes, 5 replies, 1,964 views, 3 bookmarks) whether builders want packaged local hardware, and @TheAhmadOsman showed (92 likes, 10 replies, 8,492 views, 148 bookmarks) that consumer-GPU local inference is viable but still fiddly. This is practical, urgent, and only partially addressed by local inference guides, AI PCs, and neoclouds. Opportunity: direct.
Safety and evaluation workflows that can be reviewed like code¶
The Microsoft tooling posts, the federal vetting story, and @Rudra_81 calling (14 likes, 2 replies, 5,129 views, 7 bookmarks) for domestic evaluation capacity all point to the same desire: safety work that is testable, auditable, and institutionally legible. @CSOonline reported (3 likes, 48 views, 1 bookmark) that Clarity already writes a repo-managed protocol, and @TheTuringPost showed (5 likes, 2 replies, 399 views, 3 bookmarks) the safety-testing stack around RAMPART. This is practical and urgent for labs, enterprises, and governments, but today's partial solutions are fragmented across open-source tools and policy drafts. Opportunity: direct.
Local-first copilots for sensitive personal data¶
@SimonAubury showed (3 likes, 3 replies, 100 views, 1 bookmark) a fully local stack for spending analysis built from Moneydance, DuckDB, MCP, Claude Desktop, and Ollama. That is a practical need with an emotional component: people want useful AI help without handing private financial data to an untrusted hosted model. Partial solutions exist in local models and MCP plumbing, but the current answer is still a DIY architecture diagram rather than a mainstream product. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Terminal-Bench Science | Benchmark | (+) | Real scientific workflows, containerized tasks, pytest verification | Still being assembled; only deterministic scorable tasks fit |
| Interactive evaluation design science | Evaluation method | (+) | Connects trajectories to judgments like robustness, safety, and recoverability | Framework paper, not a turnkey product |
| RAMPART | Safety testing framework | (+) | Repeatable attack and safety scenarios in CI, built on PyRIT | Requires adapters and ongoing test maintenance |
| Clarity | Governance/design tool | (+/-) | Structured assumption review and repo-managed protocol docs | Helps before build, not runtime enforcement |
| Daytona | Agent compute infrastructure | (+) | Stateful sandboxes, burst scaling, and fast startup for agents and evals | Specialized infrastructure for advanced workloads |
| llama.cpp plus local Qwen tuning | Local inference stack | (+/-) | Avoids API dependence and works on consumer GPUs | Setup complexity and hard VRAM ceilings |
| DuckDB + MCP + Claude/Ollama | Local analytics workflow | (+) | Keeps private data local and exposes a read-only query path | DIY architecture with limited mainstream packaging |
| ERA | Scientific software generation | (+) | Explores thousands of code variants and beats older baselines | Requires scorable tasks and human framing |
| Cognitive Broadband | Network operations AI | (+/-) | Concrete operator ROI claims on issue detection and customer care | Vendor-supplied evidence and telecom-specific scope |
Overall satisfaction was highest where the tool removed a concrete ambiguity. @sanmikoyejo pointed (8 likes, 405 views, 3 bookmarks) to Terminal-Bench Science because it turns "AI for science" into real workflows with programmatic verification; @TheTuringPost showed (5 likes, 2 replies, 399 views, 3 bookmarks) and @CSOonline reported (3 likes, 48 views, 1 bookmark) that RAMPART and Clarity turn safety into CI and repo-managed protocol work; @latentspacepod highlighted (16 likes, 1 reply, 2,711 views, 4 bookmarks) Daytona's stateful sandbox model; and @SimonAubury showed (3 likes, 3 replies, 100 views, 1 bookmark) how DuckDB, MCP, Claude Desktop, and Ollama can be composed into a local private-data copilot.
Mixed sentiment clustered around tools that still need heavy interpretation or tuning. @TheAhmadOsman showed (92 likes, 10 replies, 8,492 views, 148 bookmarks) that local inference can work well on an 8 GB GPU, but the same image also shows unstable near-limit profiles. @nokianetworks linked (2 likes, 106 views, 1 bookmark) a Cognitive Broadband page claiming 50%+ first-contact resolution, sub-five-minute incident qualification, and 40% proactive issue detection, but the evidence is still vendor-framed. The main migration pattern was away from single-score leaderboards and localhost assumptions toward workflow-specific benchmarks, stateful agent computers, CI safety tests, and local/on-prem data paths.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Terminal-Bench Science | @sanmikoyejo / Harbor | Benchmark for real scientific workflows contributed by researchers | Closes the gap between textbook recall and actual lab tasks | Harbor Task Format, containers, pytest verification | Beta | site, GitHub, tweet |
| Daytona | @daytonaio via @latentspacepod | Agent-native computers and stateful sandboxes for AI agents | Gives agents persistent, scalable machines instead of disposable code runners | Bare metal, stateful snapshots, custom scheduler, CLI/API | Shipped | site, article, tweet |
| RAMPART | Microsoft | Continuous safety testing for agentic AI | Turns prompt injection and unsafe-tool findings into repeatable tests | Python, pytest, PyRIT | Shipped | repo, tweet |
| Clarity | Microsoft | Structured design and failure-analysis protocol for agent systems | Makes assumptions and decision tradeoffs reviewable like code | Desktop app, web UI, coding-agent integration, markdown protocol | Shipped | repo, article |
| Local personal-finance AI stack | @SimonAubury | Local spending analysis over Moneydance data via DuckDB and MCP | Answers private-finance questions without sending raw data to an untrusted hosted model | CPython 3.14 + uv, DuckDB, MCP, Claude Desktop, Ollama qwen3.5 | Alpha | tweet |
| ERA | Google Research / Harvard SEAS | AI system that writes expert-level empirical software | Collapses months of code search and tuning for scientific tasks | Gemini, tree search | Alpha | article, tweet |
The repeated build pattern was infrastructure around AI, not another generic assistant. Terminal-Bench Science defines harder workflow tasks, Daytona supplies the computer substrate for agents, Microsoft ships safety scaffolding in RAMPART and Clarity, and @SimonAubury showed (3 likes, 3 replies, 100 views, 1 bookmark) what a one-user local-first stack looks like in practice.

The AI-for-science cluster was especially notable because builders are working on both sides of the loop at once. Terminal-Bench Science asks scientists to contribute deterministic workflows that expose current agent failures, while ERA uses Gemini and tree search to search over thousands of code variants and beat top pandemic-era hospitalization baselines. Together, they make science one of the clearest places where evaluation, infrastructure, and automated coding are converging.
6. New and Notable¶
AI-for-science got a benchmark layer and a solver layer on the same day¶
@sanmikoyejo said (8 likes, 405 views, 3 bookmarks) that Terminal-Bench Science is looking for real scientific workflows instead of textbook recall tasks, and the project page says it is targeting 100+ natural-science tasks with deterministic verification. On the same date, @TechXplore_com reported (7 likes, 2 replies, 1,692 views, 4 bookmarks) that Google's ERA system searched over thousands of code variants and produced 14 COVID-19 hospitalization models that beat top pandemic-era baselines. One project is defining harder tasks; the other is already automating the search for better solutions.
Governance capacity is becoming something people map, not just proclaim¶
@CecilYongo shared (10 likes, 2 replies, 410 views) a matrix covering 22 Global South policy instruments across human-rights impact assessments, AI safety evaluation and testing, and third-party evaluation ecosystems. Combined with @washingtonpost reporting and @Rudra_81 arguing, the notable signal is that evaluation capacity itself is becoming a public-policy object rather than a lab-only concern.

Local-first AI stopped looking like hobbyist nostalgia¶
@TheAhmadOsman published (92 likes, 10 replies, 8,492 views, 148 bookmarks) a concrete consumer-GPU benchmark table, @SimonAubury diagrammed (3 likes, 3 replies, 100 views, 1 bookmark) a full local private-data copilot stack, and @ClementDelangue asked (43 likes, 5 replies, 1,964 views, 3 bookmarks) for packaged local hardware for builders. That combination makes local-first AI look more like a packaging and product problem than an ideological one.
7. Where the Opportunities Are¶
[+++] Workflow-grounded evaluation and provenance layers — Evidence from @keyang_xuan's thread, @sanmikoyejo's Terminal-Bench Science post, @haider1's Noam Brown clip, and @boneGPT's productmaxxing post all point to the same gap: teams need evaluations that connect trajectories, reasoning budgets, and product outcomes instead of relying on a single final score.
[+++] Compute-access products for serious agents — Evidence from @emollick's compute-scarcity post, @MilkRoadAI's Jensen thread, @ClementDelangue's local hardware post, @TheAhmadOsman's benchmark screenshot, and the Daytona discussion all suggest a strong market for pooled compute, local AI appliances, and agent-native computers.
[++] Agent safety control planes and public evaluation capacity — @TheTuringPost's RAMPART explainer, @CSOonline's article post, @washingtonpost's vetting report, @Rudra_81's India thread, and @CecilYongo's policy matrix show demand for repeatable tests, decision logs, and third-party or state review infrastructure.
[++] Local-first private AI workflows — @SimonAubury's local finance stack, @TheAhmadOsman's consumer-GPU benchmark, and @ClementDelangue's local builder-hardware post point to a direct market for assistants that keep sensitive data, logs, and media on local or on-prem systems while still feeling easy to use.
8. Takeaways¶
- Benchmark talk kept losing credibility unless it connected to a workflow. The day's strongest evaluation posts were about trajectory design, reasoning-budget dependence, and obvious product gaps like email memory rather than abstract benchmark wins. (source)
- Compute scarcity is becoming the line between mass chatbots and premium agents. The most explicit framing came from @emollick, who said compute-heavy agents may remain reserved for the best-funded use cases even if strong chatbots get cheap. (source)
- The response to compute scarcity is splitting between shared infrastructure and local hardware. Jensen-style pooled compute, Hugging Face-style local boxes, and consumer-GPU benchmark tables are all answers to the same access problem. (source)
- Safety work is becoming procedural. Microsoft's RAMPART and Clarity releases, plus federal and national evaluation proposals, show a move toward repeatable tests, protocol files, and public vetting rather than informal review. (source)
- AI-for-science is getting operational on both the benchmark side and the solver side. Terminal-Bench Science is defining harder real workflows while ERA is already searching over scientific code fast enough to beat older baselines. (source)
- Capital intensity became part of the mainstream AI conversation. Bloomberg's hyperscaler chart and the "AI Capex Furnace" warning both pushed AI economics away from model pricing and toward capex sustainability. (source)