Twitter AI - 2026-05-23¶
1. What People Are Talking About¶
1.1 Agents are leaving demo-land, but only when they are constrained and evaluated 🡕¶
The strongest cluster on May 23 was not about raw model capability. It was about what has to sit around the model before people trust it in real work: orchestration, tool discipline, evaluation, review loops, and explicit constraints. At least five high-signal posts converged on the same point from different angles.
@AlexFinn argued (412 likes, 45 replies, 20,751 views, 539 bookmarks) that Hermes Agent is "the most powerful AI tool right now" but that almost nobody knows how to use it properly. The value of the post was not the slogan alone; the replies turned it into a workflow signal. One reply described people moving from basic prompting to app building, competitor research, persistent personal memory, and multi-device control, while another said trust is the deciding variable: if the agent can handle repeatable work "without freelancing the architecture," then it becomes useful.
@amitiitbhu shared (33 likes, 11 retweets, 753 views, 22 bookmarks) an AI agent evaluation guide that makes the same shift explicit. The article separates outcome evaluation, trajectory evaluation, tool-use evaluation, and planning evaluation, and says teams need to track task success, tool correctness, step counts, cost, and safety together rather than judging an agent by final text alone.
@jahirsheikh8 wrote (24 likes, 16 replies, 123 views) that shipping AI demos is easy and shipping AI products users trust is hard, listing structured outputs, RAG tuning, orchestration logic, guardrails, cost-latency tradeoffs, and evaluation pipelines as the core skill set. Replies to @WSJ amplifying (8 likes, 9 replies, 15,420 views, 4 bookmarks) a Christopher Mims story about early agentic-AI creators worrying about dangerous code pushed in the same direction: commenters argued that the key variable is not whether the model writes code, but whether teams impose test requirements, review gates, and scope limits before that code reaches production.
Discussion insight: The clearest practitioner pushback came from @giyu_codes describing (40 likes, 5 replies, 1,463 views, 8 bookmarks) a failed dental-SaaS pitch for "AI scheduling." The feature could not handle personnel preferences, day-of rescheduling, older-client adoption, or churn risk, and the replies said many SMBs still need systems of record and webhooks before they need agents.
Comparison to prior day: May 22 was dominated by agent cost and security. May 23 moved closer to operator reality: what skills, evaluation loops, and control surfaces turn an agent from an impressive demo into a product.
1.2 Infrastructure pressure got more physical: memory, power, and capacity replaced vague compute talk 🡕¶
The second major theme kept the infrastructure story alive, but in a more concrete form than the previous day. Instead of just saying agents are expensive, the leading posts named the layers under pressure: DRAM per CPU, grid-scale power, data-center capacity, and the physical infrastructure required to sustain long-running agent workloads.
@LLuciano_BTC argued (281 likes, 21 replies, 31,612 views, 7 bookmarks) that AI is "starving for physical hardware, data, and power grids" and pitched DePIN networks such as Bittensor, Akash, Render, Grass, Helium, and Hivemapper as alternative supply-side infrastructure. What kept the post grounded was the reply set: respondents immediately asked whether decentralized stacks can meet enterprise latency, uptime, and SLA requirements, and whether token incentives map to real demand.
@jukan05 said (126 likes, 12 retweets, 5 replies, 15,542 views, 31 bookmarks) that agentic AI CPU servers can require up to 4x more memory capacity than general-purpose servers. The quoted post supplied the concrete numbers underneath that claim: DRAM per server CPU core rising from roughly 4 GB toward 16 GB or even 32 GB, and Nvidia's CPU memory going from 500 GB per Grace CPU to 1.5 TB per Vera CPU in one generation.
@SmallCapSnipa posted (7 likes, 3 replies, 127 views) a Goldman Sachs chart that pushes the same story out to the end of the decade.

The chart projects that token use by AI agents will grow 24x by 2030, with enterprise and consumer agents driving most of the increase, and that the United States alone will need more than 100 GW of data-center capacity by 2030. The replies did not debate the direction; they extended it, suggesting the next version of the chart will need a separate line for physical-AI demand.
Discussion insight: The replies were less interested in abstract capex and more interested in bottlenecks: memory bandwidth ceilings, enterprise SLAs, and whether the infrastructure story can be proven in production rather than pitched in a deck.
Comparison to prior day: May 22 made the case that agents are structurally more expensive than chatbots. May 23 drilled into why: memory density, power demand, and the physical footprint of agent traffic.
1.3 Evaluation spread from leaderboard screenshots to memory, safety, and workflow tests 🡕¶
The evaluation conversation on May 23 was broader than a normal model-release day. People were still posting benchmark tables, but the strongest ones measured memory retention, workflow execution, or multi-turn safety failure rather than generic chatbot quality.
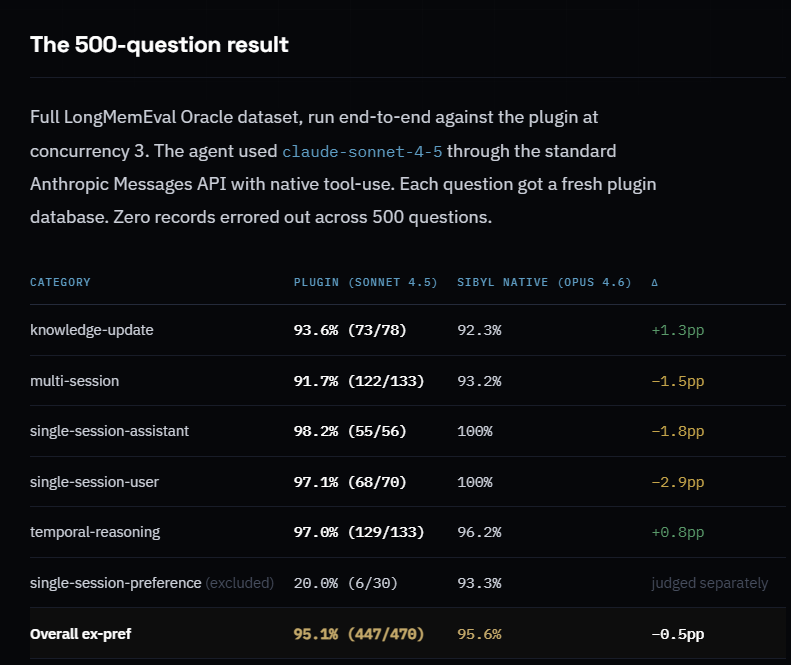
@tradingtulips claimed (32 likes, 6 replies, 600 views, 5 bookmarks) that Sibyl's new memory plugin hit 95.1% on LongMemEval using Claude Sonnet 4.5 and said raw data and logs are being prepared for a blog and paper. The attached image is the important part: it is a 500-question table broken out by knowledge updates, multi-session memory, single-session assistance, temporal reasoning, and preference handling, which is much closer to how agent memory fails in practice than a single aggregate score.
@HowToAI_ summarized (3 likes, 1 reply, 147 views, 2 bookmarks) the ScamAgents paper, which describes an autonomous multi-turn agent that keeps dialogue memory, adapts persuasion tactics mid-call, and turns scam scripts into lifelike voice calls with modern text-to-speech. The paper's central result is that prompt-level guardrails fail when harmful intent is decomposed, disguised, and delivered incrementally inside an agent framework.
@pixeluibygoogle announced (31 likes, 4 replies, 1,063 views) Gemini 3.5 Flash as a faster multimodal model for complex agentic workflows. The attached benchmark table mattered more than the marketing line because it emphasized Terminal-Bench, MCP Atlas, and other workflow-heavy evaluations rather than plain chat demos.
Discussion insight: The feed still likes benchmark screenshots, but the most credible ones now try to say something about long-horizon memory, tool-heavy workflows, or multi-turn misuse. That is a different measurement culture from simple model-vs-model bragging.
Comparison to prior day: May 21 argued that benchmarks had lost authority unless they mapped to real work. May 23 showed what replaces them: memory evals, workflow benchmarks, and agent-specific safety testing.
1.4 Sovereign and local AI stacks were pitched as procurement choices, not just ideology 🡕¶
The fourth cluster treated locality, sovereignty, and verifiability as operational buying criteria. The posts were less about abstract AI nationalism than about how a model runs, who controls it, and what proof a buyer gets back.
@staronline reported (2 likes, 3 quotes, 504 views) that Gamuda Technologies is unveiling Wira, a sovereign multimodal LLM for Malaysian enterprise and government workloads. The linked article says Wira scored 89.20% on MalayMMLU across 24,213 questions, supports more than 100 languages, can understand charts and scanned forms, and can run air-gapped on anything from a laptop to a GPU cluster. It also names three harnesses layered on top of the model - SpatialQ, Agentlinc, and Trudax - making the pitch about a full stack rather than a bare base model.
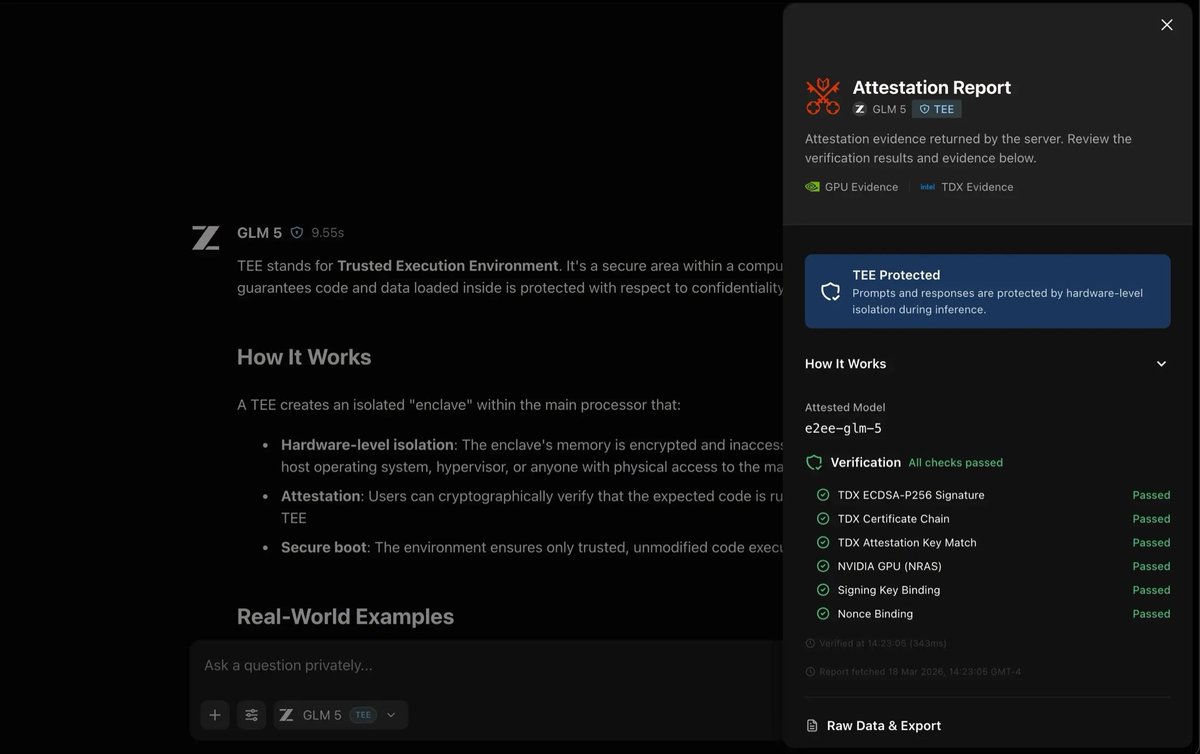
@NEARProtocol showed (43 likes, 2 replies, 14,905 views) what that trust pitch looks like operationally: a private-inference workflow where a user selects a TEE model, sends a prompt, and gets back a hardware-signed attestation report after six cryptographic checks in 343 ms.
@EuropeanPowell linked (13 likes, 10 retweets, 228 views, 3 bookmarks) a Tribune argument that the UK's AI Growth Zones are extending free-zone logic into digital infrastructure, with more than 200 site bids and weaker democratic oversight than the branding implies. Its importance for the daily feed is that it makes AI infrastructure a land-use, tax, and governance question, not only a model or chip question.
Discussion insight: The language of sovereignty on May 23 was concrete: air-gapped deployment, signed attestation, local-language capability, and location-specific infrastructure policy. The debate is moving from slogans to procurement and operating models.
Comparison to prior day: May 22's governance discussion centered on lobbying, executive orders, and safety politics. May 23 moved toward deployment design: who controls the stack, where it runs, and what institutional rules shape it.
2. What Frustrates People¶
Operational exceptions still break most "AI automation" claims¶
The clearest frustration was not abstract anti-AI sentiment; it was anger at products that claim autonomy but fail on the first real exception. @giyu_codes described (40 likes, 5 replies, 1,463 views, 8 bookmarks) a dental-SaaS pitch for AI scheduling that could not handle personnel preferences, day-of calendar reshuffling, adoption gaps between older and younger patients, or churn caused by software mistakes. Replies reduced the problem to basics: SMBs need reliable systems of record and webhook-driven workflows before they need agents. The same theme appeared in replies to @WSJ sharing (8 likes, 9 replies, 15,420 views, 4 bookmarks) concerns about dangerous code from agentic tools; the responses said the missing ingredient is constraint architecture, review gates, and narrow scopes, not more enthusiasm.
Severity: High. Current coping behavior is to keep humans in the loop, reject AI features that do not cover real edge cases, and fall back to workflows and webhooks instead of full agent autonomy. Worth building for: yes - especially products that surface operational exceptions before deployment and enforce action constraints by default.
Memory and power bottlenecks are becoming visible even in public AI chatter¶
Infrastructure frustration showed up as a shift from vague compute complaints to named bottlenecks. @jukan05 said (126 likes, 12 retweets, 5 replies, 15,542 views, 31 bookmarks) that agentic AI CPU servers can need up to 4x more memory than general-purpose servers, while the quoted post pushed DRAM-per-core estimates from roughly 4 GB toward 16-32 GB. @SmallCapSnipa posted (7 likes, 3 replies, 127 views) a Goldman Sachs chart projecting 24x agent token growth by 2030 and more than 100 GW of U.S. data-center demand. @LLuciano_BTC argued (281 likes, 21 replies, 31,612 views, 7 bookmarks) that AI is already bottlenecked by hardware, data, and power grids.
Severity: High. The coping strategies visible in the data are fragmented: pitch decentralized GPU markets, move toward local or air-gapped stacks, or simply accept larger hardware footprints. Worth building for: yes - memory-efficient agent stacks, capacity-planning tools, and power-aware routing all address pain that is already visible in public discussion.
Prompt-level safety filters do not survive long-running agents¶
The sharpest safety frustration came from the ScamAgents paper, amplified by @HowToAI_ summarizing (3 likes, 1 reply, 147 views, 2 bookmarks) that a multi-turn agent with dialogue memory, deceptive persuasion, and real-time text-to-speech can bypass current guardrails by decomposing malicious intent into harmless-looking steps. That result lines up with the day's broader anxiety around dangerous agent-written code: the problem is not only bad outputs, but bad sequences that look benign at each individual step. The counterexample in the same day's data came from @NEARProtocol showing (43 likes, 2 replies, 14,905 views) a hardware-signed attestation flow for private inference, which suggests that some teams are responding by adding proof and execution controls rather than trusting prompt filters alone.
Severity: High. The visible workaround is layered control: attestation, constrained runtimes, and calls for multi-turn safety auditing. Worth building for: yes - this is one of the clearest product gaps in the dataset.
Evaluation evidence is still fragmented and often self-published¶
The feed shows strong demand for evaluation, but the evidence base is scattered. @amitiitbhu shared (33 likes, 11 retweets, 753 views, 22 bookmarks) a broad guide to agent evaluation, @tradingtulips shared (32 likes, 6 replies, 600 views, 5 bookmarks) a LongMemEval table with a promised future paper, @pixeluibygoogle announced (31 likes, 4 replies, 1,063 views) Gemini 3.5 Flash with workflow benchmark charts, and Smartling's public release says its LQA Agent reaches 90% agreement with human reviewers and 99% accuracy on severe errors. Even the reply under the Smartling link immediately asked the operational question: how do you run LLM output evaluation at scale without burning too many tokens?
Severity: Medium. Teams are coping by building custom eval suites, publishing partial logs, or trusting vendor screenshots until better artifacts arrive. Worth building for: yes - especially tools that standardize agent evaluation, make evidence easier to audit, and expose cost alongside quality.
3. What People Wish Existed¶
A reviewable control plane for agents¶
What the data points to most clearly is a need for an agent stack that combines tests, constraints, cost visibility, and audit trails in one place. @amitiitbhu shared (33 likes, 11 retweets, 753 views, 22 bookmarks) a guide that splits agent evaluation into outcome, trajectory, tool-use, and planning layers; @jahirsheikh8 wrote (24 likes, 16 replies, 123 views) that production AI work now requires orchestration logic, guardrails, cost-latency tradeoffs, and evaluation pipelines; and replies to @WSJ sharing (8 likes, 9 replies, 15,420 views, 4 bookmarks) the dangerous-code story said the missing ingredient is review gates and scope limits. The ScamAgents paper raises the urgency by showing why single-step prompt safety is not enough. Practical need, high urgency. Partial answers exist in eval guides, benchmark tables, and attestation demos, but no single artifact in the day's data closes the loop. Opportunity: direct.
Automation that handles operational exceptions before it claims autonomy¶
@giyu_codes described (40 likes, 5 replies, 1,463 views, 8 bookmarks) a concrete failure mode: an "AI scheduling" feature that could not cope with cancellations, staff preferences, age-based adoption issues, or churn from mistakes. At the opposite end of the optimism spectrum, replies to @AlexFinn promoting (412 likes, 45 replies, 20,751 views, 539 bookmarks) Hermes Agent were still fixated on trust - whether the agent can handle repetitive work without "freelancing the architecture." The need is practical and immediate: software that understands exception handling, not just happy-path automation. Current partial solutions are custom workflows, webhooks, and human review. Opportunity: direct.
Private and sovereign AI that is verifiable, not just local-first branding¶
The day's locality signals all ask for the same thing: control plus proof. @staronline reported (2 likes, 3 quotes, 504 views) that Wira can run air-gapped from laptop scale to GPU clusters while handling Malay and 100+ other languages. @NEARProtocol showed (43 likes, 2 replies, 14,905 views) a hardware-signed attestation report for private inference, and @EuropeanPowell linked (13 likes, 10 retweets, 228 views, 3 bookmarks) an article arguing that AI Growth Zones are turning deployment geography into a governance issue. This need is practical for governments and regulated enterprises, and emotional for buyers who want to know who controls their stack. Partial solutions exist, but they are fragmented across model vendors, infrastructure layers, and public policy. Opportunity: competitive.
Multilingual quality assurance that scales without exploding review cost¶
The Smartling release points at a very specific unmet need: enterprises want AI translation speed without giving up QA rigor. The Smartling announcement says LQA Agent uses MQM scoring, can run fully automatically or route only risky content to humans, and reached 90% agreement with human reviewers plus 99% accuracy on severe errors in internal testing. The most revealing response was the practical question under the shared link: how do you evaluate LLM output at scale without burning through too many tokens? This is a direct operational need with existing partial answers in translation memory, human review, and internal benchmarking. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Hermes Agent | Agent platform | (+) | High interest around multi-step workflow automation, personal memory, research, and cross-device control | Trust and operator discipline are still the main blockers |
| AI Agent Evaluation guide | Evaluation method | (+) | Separates outcome, trajectory, tool-use, and planning evaluation; makes cost and safety first-class metrics | Educational framework, not a runtime control layer |
| Sibyl memory plugin | Agent memory | (+/-) | 500-question LongMemEval table and compatibility with Hermes, Claude Code, and Codex | Benchmark is self-published and the promised paper/logs were not yet public |
| Smartling LQA Agent | Localization QA | (+) | MQM-based scoring, human-review routing, 90% agreement with human reviewers, 99% severe-error accuracy in internal testing | Localization-specific and still depends on Smartling's internal measurement stack |
| Gemini 3.5 Flash | LLM | (+) | Positioned around Terminal-Bench, MCP Atlas, multimodality, speed, and agentic workflows | Evidence in the day's data is still launch-stage and benchmark-heavy |
| Wira | Sovereign LLM | (+) | 89.20% on MalayMMLU, 100+ languages, charts/forms support, air-gapped deployment from laptop to GPU cluster | Region-specific focus and limited independent usage data in the feed |
| NEAR private inference | Private inference / TEE | (+) | Hardware-signed attestation flow with six checks passed in 343 ms | Platform-specific implementation and no adoption evidence beyond the demo |
| KaliGPT (HackerX v1.3) | Security CLI agent | (+) | Public Python repo, 247 stars, 56 forks, Gemini/Ollama/OpenRouter/OpenAI backends, terminal-native workflows | Active-development warning and narrow ethical-hacking focus |
| Allen AI pegboard dataset | Dataset / robotics eval | (+) | 76k-frame bimanual dataset with 3 camera views and 14-DOF control for open VLA evaluation | Single task family, so coverage is narrower than a general robotics benchmark |
| LLM-Metrics | Research evaluation method | (+/-) | Citation-independent impact proxy from model memory across 549 papers and 17 models | Correlation is modest, so it complements rather than replaces standard research metrics |
The overall tool pattern was clear: people are wrapping models with memory, evaluation, trust, or domain-specific harnesses rather than treating the base model as the product. The most visible migration is from single-model, single-prompt setups toward multi-layer systems - model selection in the background, explicit eval loops, attestation, or task-specific datasets. Satisfaction is highest where the stack narrows scope and makes behavior measurable; confidence drops when claims depend on vendor screenshots or launch-day benchmark cards alone.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| HackerX (KaliGPT v1.3) | SudoHopeX | Linux CLI agent for ethical hacking and cybersecurity workflows | Gives security practitioners a domain-specific agent instead of ad hoc prompting inside generic chat tools | Python, Gemini, Ollama, OpenRouter, OpenAI | Beta | post · repo |
| Smartling AI release | Smartling | MQM-based LQA Agent plus Auto Select LLM, Style Rules, Language Adaptation, Instant AI Translation, and AI Image Translation | Helps enterprises scale multilingual content without losing QA, consistency, or human review controls | MQM, LLMs, RAG over translation memory, sync API | Shipped | post · release |
| Wira | Gamuda Technologies | Sovereign multimodal LLM and harness stack for Malaysian enterprise and government workloads | Offers local-language, air-gapped AI deployment for regulated or disconnected environments | Proprietary multimodal LLM, SpatialQ, Agentlinc, Trudax, sovereign cloud | Beta | post · article |
| Allen AI pegboard dataset | Allen AI | Open bimanual robot manipulation dataset for VLA evaluation | Gives robotics teams public data for benchmarking physical-AI control instead of relying only on private lab tasks | Hugging Face, LeRobot, 3-camera capture, 14-DOF control | Shipped | post · dataset |
| Sibyl memory plugin | @sibylcap | Pluggable memory layer for Hermes, Claude Code, and Codex | Targets long-horizon memory and context persistence for agent workflows | Claude Sonnet 4.5, LongMemEval, pluggable memory middleware | Alpha | post |
Smartling's release is notable because it is not just another model wrapper. The release bundles evaluation, routing, and adaptation into the same operational surface: MQM-based quality scoring, automatic model selection, language adaptation across variants such as US-to-UK English, and image translation that rebuilds visual assets with translated text. That is a good example of how enterprise AI products are being built around workflow controls rather than around a single frontier-model call.

Wira stands out because the article describes an end-to-end sovereign stack rather than a patriotic branding exercise. The model is presented as locally controlled, usable in disconnected environments, and paired with specific harnesses for geospatial reasoning, knowledge work, and dashboard analysis. The core sell is not only accuracy on MalayMMLU, but the claim that agencies can run the stack without dependence on a foreign data center.
KaliGPT shows another pattern in the day's builder activity: domain-specific agents with bounded use cases. The repo is not trying to be a universal assistant. It is a CLI product for ethical hacking and cybersecurity, with explicit provider switching and an active-development disclaimer. That narrower scope makes it easier to inspect what the tool is supposed to do and how a user would actually operate it.
The repeated build pattern across the day was not "launch a new base model." It was: add memory, add QA, add attestation, add localized deployment, or add domain-specific tooling. Builders are moving up and down the stack at once - from datasets for physical AI to enterprise harnesses and domain-specific agents - but the common thread is control.
6. New and Notable¶
ScamAgent turns prompt-injection anxiety into a full multi-turn scam pipeline¶
@HowToAI_ summarized (3 likes, 1 reply, 147 views, 2 bookmarks) a paper that is more important than its engagement count suggests: ScamAgents. The paper says an autonomous agent can maintain dialogue memory, adapt persuasion tactics, and turn scam scripts into lifelike voice calls with text-to-speech, while current guardrails fail because malicious intent is decomposed and disguised across turns.

LLM-Metrics proposes research impact scoring from model memory¶
@SciFi linked (2 likes, 1 reply, 100 views, 1 bookmark) the LLM-Metrics paper, which tries to infer research impact from what large language models appear to remember. The authors evaluated 549 computer science papers across 17 models and found a positive but modest correlation with citation counts (rho = 0.1495), with author-recognition probes strongest and a 3B Llama model outperforming many larger models. Even if the method stays niche, it is a notable example of evaluation moving into new surfaces beyond citations or benchmark leaderboards.
Under Training packages model mechanics as an interactive browser game¶
@om_patel5 shared (102 likes, 9 replies, 13,604 views, 86 bookmarks) a browser game called "Under Training" where the player goes through raw data ingestion, training, inference, and live evaluation as if they were a large language model. The replies pushed past the joke and asked whether the game can honestly represent context-window slippage, overfitting, and catastrophic forgetting. That makes it more than a meme: it is a sign that AI literacy itself is turning into a product surface.
AI Growth Zones make AI infrastructure a zoning and governance story¶
@EuropeanPowell linked (13 likes, 10 retweets, 228 views, 3 bookmarks) a Tribune article arguing that the UK's AI Growth Zones extend free-zone logic into the digital sphere. The article says the policy has attracted more than 200 site bids and folds AI into a broader Industrial Strategy Zones framework. Whether one agrees with the article's politics or not, it is a useful reminder that AI deployment is now also a planning, tax, and local-governance issue.
7. Where the Opportunities Are¶
[+++] Agent control planes for real workflows - The strongest evidence on May 23 said the hard part is no longer generating an answer. It is constraining action, evaluating trajectories, tracking cost, and reviewing outputs before they hit production. Evidence comes from Hermes workflow enthusiasm, the Outcome School evaluation guide, Jahir Sheikh's production-systems checklist, the dental scheduling failure case, the WSJ dangerous-code thread, and the ScamAgents paper.
[++] Memory, evaluation, and QA layers for long-running agents - The Sibyl LongMemEval table, Gemini 3.5 Flash workflow benchmarks, LLM-Metrics paper, and Smartling's MQM-based LQA release all point to the same gap: people need better ways to measure memory, tool use, and quality over time. The opportunity is moderate because multiple partial solutions already exist, but none dominate across domains.
[++] Sovereign and attested AI deployment stacks - Wira, NEAR private inference, and the AI Growth Zones article all show that buyers increasingly care about locality, governance, and proof. This is more than on-device enthusiasm; it is a stack opportunity around air-gapped deployment, signed attestation, and procurement-friendly infrastructure narratives.
[++] Domain-specific AI harnesses instead of general-purpose wrappers - KaliGPT, Smartling's translation stack, and Wira's named harnesses all package AI around bounded use cases rather than around generic model access. The dental-SaaS story strengthens the case: narrow, inspectable tools may win where broad autonomy claims fail.
[+] Multilingual AI quality infrastructure - Smartling's release is a direct signal that multilingual QA, adaptation, and style control are becoming their own product layer. The reply asking how to run LLM evaluation at scale without wasting tokens suggests there is still room for competitors or supporting tools.
[+] Physical-AI data and open VLA evaluation - Allen AI's pegboard dataset is a small but credible sign that physical-AI builders want more public data and benchmarks. It is still early relative to software-agent tooling, but the opportunity is emerging where datasets, eval harnesses, and control stacks meet.
8. Takeaways¶
- The center of gravity moved from models to control planes. The most important question in the feed was no longer "which model wins," but what orchestration, evaluation, and review structure makes an agent safe and useful in production. (Hermes; AI agent evaluation guide; Jahir Sheikh)
- Infrastructure talk got more physical. Public discussion moved from generic compute scarcity to DRAM-per-core, power demand, and data-center capacity, with one Goldman Sachs chart projecting 24x agent-token growth and more than 100 GW of U.S. data-center demand by 2030. (jukan05; Goldman Sachs chart; LLuciano_BTC)
- Prompt-era safety assumptions look too weak for multi-turn agents. ScamAgents is the starkest evidence in the day's data that malicious intent can be hidden across turns and still survive current guardrails. (ScamAgents paper; tweet summary)
- Trust is being sold through locality and proof. Wira's air-gapped sovereign stack and NEAR's signed attestation flow show that buyers increasingly want to know where the model runs and how that claim is verified. (Wira article; NEAR private inference)
- Builders are shipping around workflows, QA, and domain scope rather than launching naked model wrappers. Smartling wrapped translation in evaluation and routing, KaliGPT wrapped model access in a security-focused CLI, and Allen AI shipped a task-specific physical-AI dataset instead of another general benchmark. (Smartling release; KaliGPT; Allen AI dataset)
- Evaluation is fragmenting into specialized surfaces. The day's strongest measurement artifacts tracked memory behavior, workflow-heavy agent benchmarks, and even research impact via model memory, which suggests that generic leaderboard culture will keep losing share to narrower, more operational metrics. (Sibyl memory plugin; Gemini 3.5 Flash; LLM-Metrics)