Twitter AI - 2026-05-23¶
1. 人们在讨论什么¶
1.1 智能体正在走出演示阶段,但前提是它们受到约束并经过评估 🡕¶
5 月 23 日最强的一组讨论,并不在于模型原始能力有多强,而在于:在人们愿意把模型放进真实工作之前,模型外围到底要补上什么——编排、工具纪律、评估、复审闭环,以及明确的约束。至少有 5 条高信号帖子从不同角度收敛到同一点。
@AlexFinn 认为(412 次点赞、45 条回复、20,751 次浏览、539 次收藏),Hermes Agent 是“现在最强大的 AI 工具”,但几乎没人真正知道怎么把它用对。这条帖子真正有价值的,不只是口号本身;回复把它变成了一个工作流信号。一条回复描述了人们如何从基础提示词,进一步走向应用构建、竞品研究、持久化个人记忆和跨设备控制;另一条则说,决定因素是信任:如果一个智能体能在“不自作主张改架构”的前提下处理可重复的工作,它才真正有用。
@amitiitbhu 分享(33 次点赞、11 次转发、753 次浏览、22 次收藏)了一篇 AI 智能体评估指南。文中把评估明确拆成结果评估、轨迹评估、工具使用评估和规划评估,并指出团队需要同时跟踪任务成功率、工具调用正确性、步骤数、成本和安全性,而不是只看最后产出的文本。
@jahirsheikh8 写道(24 次点赞、16 条回复、123 次浏览),做 AI demo 很容易,但做出用户真正信任的 AI 产品很难;他把结构化输出、RAG 调优、编排逻辑、安全护栏、成本与延迟取舍、评估流水线列为核心技能集。对 @WSJ 转发放大(8 次点赞、9 条回复、15,420 次浏览、4 次收藏)Christopher Mims 那篇关于早期智能体式 AI 构建者担心危险代码的报道的回复,也把讨论推向同一方向:评论者认为,关键变量不在于模型会不会写代码,而在于团队是否会在代码进入生产环境前,加上测试要求、评审闸口和范围限制。
讨论要点: 最明确的从业者反驳,来自 @giyu_codes 讲述(40 次点赞、5 条回复、1,463 次浏览、8 次收藏)一次失败的牙科 SaaS “AI 排班”方案。这个功能处理不了人员偏好、当天临时改期、老年客户采纳率,以及流失风险;回复则指出,很多 SMB 在需要智能体之前,先需要可靠的主记录系统和 webhook。
与前日对比: 5 月 22 日的主旋律还是智能体成本和安全。到了 5 月 23 日,讨论更贴近操作者的现实:到底是哪些技能、评估闭环和控制界面,能把一个惊艳 demo 变成真正的产品。
1.2 基础设施压力变得更“物理”了:记忆体、电力和容量取代了含糊的算力讨论 🡕¶
第二大主题延续了基础设施叙事,但比前一天更具体。头部帖子不再只是说智能体很贵,而是点名了真正承压的层:每个 CPU 的 DRAM 容量、电网级电力、数据中心容量,以及支撑长时间智能体负载所需的物理基础设施。
@LLuciano_BTC 认为(281 次点赞、21 条回复、31,612 次浏览、7 次收藏),AI 正在“被物理硬件、数据和电网饿住”,并把 Bittensor、Akash、Render、Grass、Helium、Hivemapper 等 DePIN 网络包装成替代性的供给侧基础设施。让这条帖子不至于飘起来的,是回复区:大家立刻追问,去中心化堆栈能否满足企业级延迟、可用性和 SLA 要求,以及 token 激励是否真的映射到真实需求。
@jukan05 表示(126 次点赞、12 次转发、5 条回复、15,542 次浏览、31 次收藏),智能体式 AI 的 CPU 服务器所需内存容量,最高可达通用服务器的 4x。被引用的帖子也给出了支撑这个说法的具体数字:单台服务器里每个 CPU 核心的 DRAM,正从大约 4 GB 抬升到 16 GB,甚至 32 GB;Nvidia 的 CPU 内存也在一代之内,从每颗 Grace CPU 的 500 GB 提高到 Vera CPU 的 1.5 TB。
@SmallCapSnipa 贴出(7 次点赞、3 条回复、127 次浏览)了一张 Goldman Sachs 图表,讲的是同一件事,而且把时间线拉到了这个十年末。

图表预测,到 2030 年,AI 智能体的 token 用量将增长 24x,增长的大头来自企业与消费者智能体;同时,仅美国一地到 2030 年就需要超过 100 GW 的数据中心容量。回复并没有争论方向,而是继续往外推:有人认为,下一版图表还得单独画出实体 AI 需求这一条线。
讨论要点: 回复里人们真正关心的,不是抽象的资本开支,而是瓶颈本身:内存带宽上限、企业级 SLA,以及这些基础设施叙事能否在生产环境中被证明,而不是只存在于一份演示文稿里。
与前日对比: 5 月 22 日只是说明智能体在结构上比聊天机器人更贵。5 月 23 日则进一步解释了“为什么贵”——更高的内存密度、电力需求,以及智能体流量带来的物理占地。
1.3 评估已经从排行榜截图扩展到记忆、安全与工作流测试 🡕¶
5 月 23 日的评估讨论,比常见的模型发布日更广。人们依然在发基准测试表格,但最有说服力的那些,测的不再是泛化的聊天机器人质量,而是记忆保持、工作流执行,或多轮安全失效。
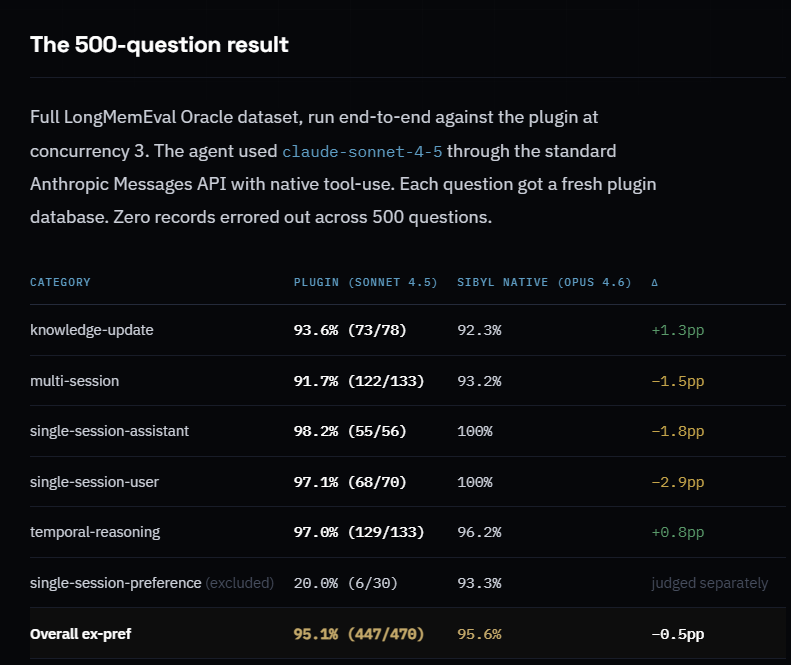
@tradingtulips 声称(32 次点赞、6 条回复、600 次浏览、5 次收藏),Sibyl 的新记忆插件在 Claude Sonnet 4.5 上,把 LongMemEval 跑到了 95.1%,原始数据和日志也正在整理,准备写博客和论文。真正重要的是配图:这是一张 500 道题的表,按知识更新、多会话记忆、单会话辅助、时间推理和偏好处理逐项拆开,比单一汇总分数更接近智能体记忆在现实里会如何失效。
@HowToAI_ 总结(3 次点赞、1 条回复、147 次浏览、2 次收藏)了 《ScamAgents》论文。论文描述了一个自主多轮智能体:它能保留对话记忆、在通话中途调整说服策略,并借助现代文本转语音,把诈骗脚本变成逼真的语音来电。论文最核心的结论是:一旦有害意图被拆解、伪装,并在智能体框架里逐轮递进地执行,提示词层面的安全护栏就会失效。
@pixeluibygoogle 宣布(31 次点赞、4 条回复、1,063 次浏览)Gemini 3.5 Flash 是一款面向复杂智能体式工作流、更快的多模态模型。真正重要的同样是配套基准测试表,而不是营销话术,因为它强调的是 Terminal-Bench、MCP Atlas 等工作流负载更重的评估,而不是普通聊天 demo。
讨论要点: 时间线依然喜欢基准测试截图,但现在最可信的那些截图,已经在试图说明长周期记忆、重工具工作流,或多轮滥用风险。相比简单的模型对模型炫耀,这已经是另一种度量文化。
与前日对比: 5 月 21 日人们就在说,如果基准测试映射不到真实工作,它们就失去权威。5 月 23 日已经出现替代物:记忆评估、工作流基准测试,以及面向智能体的安全测试。
1.4 主权与本地 AI 堆栈被当成采购选项,而不只是意识形态 🡕¶
第四组讨论把本地性、主权和可验证性,当成运营层面的采购标准。帖子关心的,不再是抽象的 AI 民族主义,而是模型怎么运行、由谁控制,以及买方最终能拿到什么证明。
@staronline 报道(2 次点赞、3 次引用、504 次浏览),Gamuda Technologies 正在发布 Wira,这是一款面向马来西亚企业与政府工作负载的主权多模态 LLM。链接文章写道,Wira 在 24,213 道题上的 MalayMMLU 获得了 89.20%,支持 100+ 种语言,能理解图表和扫描表单,并且可以在从笔记本到 GPU 集群的各种环境里做气隙隔离部署。文章还点名了叠在模型之上的 3 个运行框架——SpatialQ、Agentlinc 和 Trudax——让它讲的是一整套堆栈,而不是一颗裸基座模型。
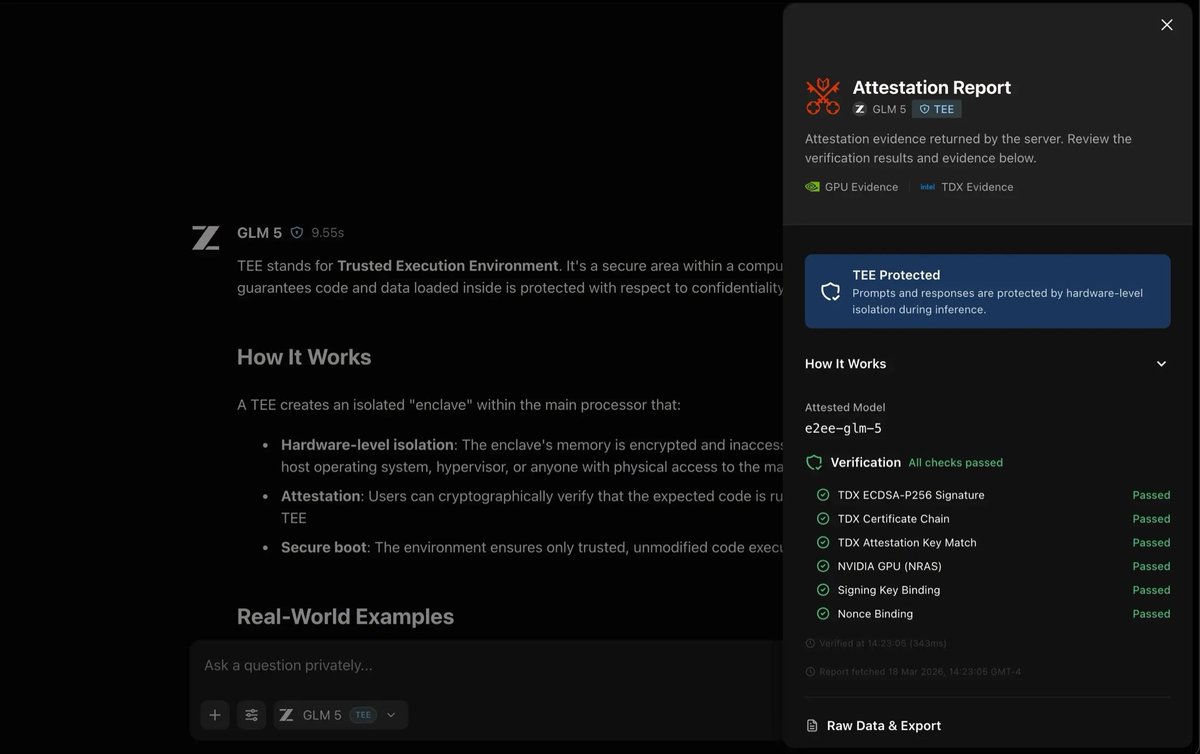
@NEARProtocol 展示(43 次点赞、2 条回复、14,905 次浏览)了这种信任叙事在运营层面的样子:用户先选择一个 TEE 模型,发出提示词,然后在 343 ms 内经 6 次密码学检查后,拿回一份硬件签名的证明报告。
@EuropeanPowell 链接(13 次点赞、10 次转发、228 次浏览、3 次收藏)了一篇 Tribune 文章,认为英国的 AI Growth Zones 正把自由区逻辑延伸到数字基础设施,而且已有 200+ 个选址申请,而民主监督却比宣传暗示的更弱。它之所以对当天时间线重要,是因为它把 AI 基础设施变成了土地利用、税收和治理问题,而不只是模型或芯片问题。
讨论要点: 5 月 23 日“主权”这套语言已经非常具体:气隙隔离部署、签名证明、本地语言能力,以及按地点划分的基础设施政策。争论正在从口号,转向采购与运营模式。
与前日对比: 5 月 22 日的治理讨论,还围绕游说、行政令和安全政治。5 月 23 日则更靠近部署设计:谁控制这套堆栈、它跑在哪里,以及制度规则如何塑造它。
2. 令人困扰的问题¶
运营异常依然会击穿大多数“AI 自动化”叙事¶
最明确的挫败感,不是抽象的反 AI 情绪,而是对那些宣称可以自治、却在第一个真实异常上就失灵的产品的愤怒。@giyu_codes 描述(40 次点赞、5 条回复、1,463 次浏览、8 次收藏)了一次牙科 SaaS 的 AI 排班推销:它处理不了人员偏好、当天日程重排、老年与年轻病人的采纳差异,也处理不了软件失误导致的流失。回复把问题归结得很基础:SMB 在需要智能体之前,先需要可靠的主记录系统和 webhook 驱动的工作流。对 @WSJ 分享(8 次点赞、9 条回复、15,420 次浏览、4 次收藏)“智能体工具生成危险代码”担忧的回复,也重复了同一主题:缺的不是更多热情,而是约束架构、评审闸口和更窄的作用范围。
严重程度:高。当前的应对方式是让人继续留在回路中,拒绝那些覆盖不了真实边界情况的 AI 功能,并优先退回工作流和 webhook,而不是完整的智能体自治。值得做,尤其是那些能在部署前暴露运营异常、并默认强制执行动作约束的产品。
即使在公开 AI 讨论里,记忆体和电力瓶颈也开始变得清晰可见¶
基础设施层面的挫败感,表现为讨论从含糊的“算力不够”转向点名具体瓶颈。@jukan05 表示(126 次点赞、12 次转发、5 条回复、15,542 次浏览、31 次收藏),智能体式 AI 的 CPU 服务器所需内存最高可达通用服务器的 4x,被引用的帖子则把单核 DRAM 估算从大约 4 GB 推到了 16-32 GB。@SmallCapSnipa 贴出(7 次点赞、3 条回复、127 次浏览)一张 Goldman Sachs 图表,预测到 2030 年智能体 token 增长 24x,美国数据中心需求将超过 100 GW。@LLuciano_BTC 认为(281 次点赞、21 条回复、31,612 次浏览、7 次收藏),AI 已经被硬件、数据和电网卡住了。
严重程度:高。数据里能看到的应对策略仍然很分散:推销去中心化 GPU 市场、转向本地或气隙隔离堆栈,或者干脆接受更大的硬件占地。值得做——无论是更省内存的智能体堆栈、容量规划工具,还是考虑电力约束的路由系统,这些都在回应公开讨论里已经显现的痛点。
提示词层面的安全过滤扛不住长时运行的智能体¶
当天最尖锐的安全挫败感,来自 《ScamAgents》论文。@HowToAI_ 总结(3 次点赞、1 条回复、147 次浏览、2 次收藏)称,一个具备对话记忆、欺骗式说服和实时文本转语音的多轮智能体,可以通过把恶意意图拆成看似无害的步骤,绕过现有护栏。这也呼应了当天围绕“智能体写出危险代码”的更广泛焦虑:问题不只是坏输出,而是每一步看起来都无害、连起来却有害的坏序列。同一天数据里一个反向例子来自 @NEARProtocol 展示(43 次点赞、2 条回复、14,905 次浏览)的私有推理硬件签名证明流程,它说明有些团队的应对方式,已经不是单纯相信提示词过滤,而是再叠一层证明与执行控制。
严重程度:高。当前可见的权宜方案是分层控制:证明、受约束的运行时,以及对多轮安全审计的呼声。值得做——这是整个数据集里最清晰的产品缺口之一。
评估证据仍然碎片化,而且往往由发布方自己提供¶
时间线明确显示出人们对评估的强需求,但证据基础依然分散。@amitiitbhu 分享(33 次点赞、11 次转发、753 次浏览、22 次收藏)了一份广义的智能体评估指南,@tradingtulips 分享(32 次点赞、6 条回复、600 次浏览、5 次收藏)了一张 LongMemEval 表,并承诺后续会有论文,@pixeluibygoogle 宣布(31 次点赞、4 条回复、1,063 次浏览)Gemini 3.5 Flash 时配了工作流基准测试图表,而 Smartling 的公开发布则称,其 LQA Agent 与人工审校的一致率达到 90%,在严重错误上内部测试准确率达到 99%。就连 Smartling 链接下的一条回复,也立刻问到了落地问题:如何在不烧掉太多 token 的前提下,规模化评估 LLM 输出?
严重程度:中。团队现在的应对方式,是自建评估套件、发布部分日志,或者在更好的证据到来前先相信厂商截图。值得做——尤其是那些能把智能体评估标准化、让证据更易审计,并把成本与质量一起展示的工具。
3. 人们期望的功能¶
一个可供审查的智能体控制平面¶
数据最清楚指向的需求,是一套把测试、约束、成本可见性和审计轨迹放在同一处的智能体堆栈。@amitiitbhu 分享(33 次点赞、11 次转发、753 次浏览、22 次收藏)了一份把智能体评估拆成结果、轨迹、工具使用和规划四层的指南;@jahirsheikh8 写道(24 次点赞、16 条回复、123 次浏览),生产级 AI 工作如今需要编排逻辑、安全护栏、成本/延迟取舍和评估流水线;而对 @WSJ 分享(8 次点赞、9 条回复、15,420 次浏览、4 次收藏)危险代码报道的回复,则说缺的正是评审闸口和范围限制。《ScamAgents》论文 又进一步提高了紧迫性,因为它说明单步提示词安全远远不够。这是一个务实且紧迫的需求。评估指南、基准测试表和证明 demo 都算部分答案,但当天数据里没有一个单一工件能把闭环真正补齐。机会:直接。
在宣称自治之前,先能处理运营异常的自动化¶
@giyu_codes 描述(40 次点赞、5 条回复、1,463 次浏览、8 次收藏)了一个非常具体的失败模式:一个“AI 排班”功能应付不了取消、员工偏好、不同年龄层的采纳差异,也应付不了错误引发的流失。站在乐观叙事另一端,对 @AlexFinn 推广(412 次点赞、45 条回复、20,751 次浏览、539 次收藏)Hermes Agent 的回复,仍然盯着“信任”这件事:这个智能体能不能在“不自作主张改架构”的前提下,稳稳接住重复性工作。这个需求既务实又眼前:人们需要的是懂异常处理的软件,而不是只会跑顺风顺水路径的自动化。当前的部分解法,是自定义工作流、webhook 和人工复审。机会:直接。
可验证的私有化与主权 AI,而不只是“本地优先”的营销话术¶
当天所有关于本地性的信号,实际上都在问同一件事:控制权加上证明。@staronline 报道(2 次点赞、3 次引用、504 次浏览),Wira 可以在从笔记本到 GPU 集群的环境里做气隙隔离运行,同时处理马来语和 100+ 其他语言。@NEARProtocol 展示(43 次点赞、2 条回复、14,905 次浏览)了一份面向私有推理的硬件签名证明报告,而 @EuropeanPowell 链接(13 次点赞、10 次转发、228 次浏览、3 次收藏)的一篇文章则认为,AI Growth Zones 正把部署地理位置变成治理议题。对政府和受监管企业来说,这是一项务实需求;对买方情绪来说,它同样重要,因为他们想知道是谁在控制自己的堆栈。现在的部分解法已存在,但分散在模型供应商、基础设施层和公共政策之中。机会:竞争激烈。
能规模化扩展、又不会让复审成本失控的多语言质量保障¶
Smartling 的发布,指向了一个非常具体的未满足需求:企业希望要到 AI 翻译的速度,但不想放弃 QA 的严谨度。Smartling 公告 称,LQA Agent 使用 MQM 评分,可以全自动运行,也可以只把高风险内容路由给人工;在内部测试里,它与人工审校的一致率达到 90%,在严重错误上的准确率达到 99%。最说明问题的,是共享链接下那条非常务实的追问:怎样才能在不消耗过多 token 的前提下,规模化评估 LLM 输出?这是一个直接的运营需求,目前已有翻译记忆、人工审校和内部基准测试这些部分答案。机会:竞争激烈。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Hermes Agent | 智能体平台 | (+) | 围绕多步骤工作流自动化、个人记忆、研究与跨设备控制的关注度很高 | 信任和操作者纪律仍然是主要障碍 |
| AI 智能体评估指南 | 评估方法 | (+) | 把结果、轨迹、工具使用和规划评估分开;把成本和安全也纳入一级指标 | 这是教育框架,不是运行时控制层 |
| Sibyl memory plugin | 智能体记忆 | (+/-) | 有 500 题 LongMemEval 表,并兼容 Hermes、Claude Code 和 Codex | 基准测试由发布方自己提供,而且承诺中的论文/日志当时尚未公开 |
| Smartling LQA Agent | 本地化 QA | (+) | 提供基于 MQM 的评分、人工复审路由、与人工审校 90% 一致率,以及严重错误 99% 准确率 | 只覆盖本地化场景,且仍依赖 Smartling 的内部测量堆栈 |
| Gemini 3.5 Flash | LLM | (+) | 围绕 Terminal-Bench、MCP Atlas、多模态、速度和智能体式工作流来定位 | 当天数据里的证据仍然停留在发布初期,基准测试色彩过重 |
| Wira | 主权 LLM | (+) | MalayMMLU 达到 89.20%、支持 100+ 语言、支持图表/表单理解,并可从笔记本到 GPU 集群做气隙隔离部署 | 聚焦区域场景,时间线里也缺少独立使用数据 |
| NEAR private inference | 私有推理 / TEE | (+) | 硬件签名证明流程在 343 ms 内经 6 项检查后返回结果 | 平台专属实现,除 demo 外没有更多采用证据 |
| KaliGPT (HackerX v1.3) | 安全 CLI 智能体 | (+) | 公开的 Python 仓库、247 stars、56 forks、支持 Gemini/Ollama/OpenRouter/OpenAI 后端,并原生适配终端工作流 | 明确标注为活跃开发中,且仅聚焦道德黑客场景 |
| Allen AI pegboard dataset | 数据集 / 机器人评估 | (+) | 提供 76k 帧、3 个相机视角、14-DOF 控制的双臂数据集,用于开放 VLA 评估 | 只覆盖单一任务族,范围比通用机器人基准测试更窄 |
| LLM-Metrics | 研究评估方法 | (+/-) | 基于模型记忆,在 549 篇论文和 17 个模型上给出独立于引用量的影响力代理指标 | 相关程度不高,只能补充而不能替代传统研究指标 |
整体工具模式已经很清晰:人们在给模型外面叠上记忆、评估、信任或领域专用的运行框架,而不再把底座模型本身当成产品。最明显的迁移,是从单模型、单提示词设置,转向多层系统——后台做模型选择、显式评估闭环、证明流程,或任务专用数据集。只要堆栈能缩小作用范围、让行为可测,满意度就高;一旦论据只剩厂商截图或首发日基准测试卡片,信心就会下降。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| HackerX (KaliGPT v1.3) | SudoHopeX | 面向道德黑客与网络安全工作流的 Linux CLI 智能体 | 给安全从业者一个领域专用智能体,而不是在通用聊天工具里临时提示词拼凑 | Python、Gemini、Ollama、OpenRouter、OpenAI | Beta | 推文 · 仓库 |
| Smartling AI release | Smartling | 基于 MQM 的 LQA Agent,外加 Auto Select LLM、Style Rules、Language Adaptation、Instant AI Translation 和 AI Image Translation | 帮助企业在不丢掉 QA、一致性和人工复审控制的前提下,规模化处理多语言内容 | MQM、LLMs、基于 translation memory 的 RAG、sync API | 已发布 | 推文 · 发布 |
| Wira | Gamuda Technologies | 面向马来西亚企业与政府工作负载的主权多模态 LLM 与运行框架堆栈 | 为受监管或离线环境提供本地语言、可气隙隔离的 AI 部署 | 专有多模态 LLM、SpatialQ、Agentlinc、Trudax、主权云 | Beta | 推文 · 文章 |
| Allen AI pegboard dataset | Allen AI | 用于 VLA 评估的开放双臂机器人操作数据集 | 给机器人团队提供公开数据来评测实体 AI 控制,而不只依赖私有实验室任务 | Hugging Face、LeRobot、3-camera 采集、14-DOF 控制 | 已发布 | 推文 · 数据集 |
| Sibyl memory plugin | @sibylcap | 可插拔的记忆层,适配 Hermes、Claude Code 和 Codex | 面向智能体工作流中的长周期记忆与上下文持久化 | Claude Sonnet 4.5、LongMemEval、可插拔记忆中间件 | Alpha | 推文 |
Smartling 的发布之所以值得注意,是因为它不只是又一个模型封装层。它把评估、路由和适配绑在同一个运营界面里:基于 MQM 的质量评分、自动选模、针对 US-to-UK English 这类变体的语言适配,以及会重建带翻译文本视觉资产的图像翻译。这正是企业 AI 产品如何围绕工作流控制,而不是单次前沿模型调用来构建的一个好例子。

Wira 突出的地方在于,文章描写的是一整套端到端主权堆栈,而不是一次爱国主义式品牌包装。这个模型被描述为本地可控、可用于离线环境,并且配套了面向地理空间推理、知识工作和仪表盘分析的专用运行框架。它真正售卖的,不只是 MalayMMLU 的准确率,而是机构可以在不依赖外国数据中心的情况下运行整套堆栈这一主张。
KaliGPT 也展示了当天构建者活动里的另一种模式:边界明确、用途受限的领域专用智能体。这个仓库并不试图做一个“万能助手”。它是一个面向道德黑客和网络安全的 CLI 产品,支持明确的提供商切换,也清楚标了“活跃开发中”的免责声明。正因为范围更窄,用户更容易看清它到底要做什么,也更容易判断它在真实使用里会怎么运作。
当天反复出现的构建模式,并不是“再发一个新的底座模型”。而是:加记忆、加 QA、加证明、加本地化部署,或者加领域专用工具链。构建者正在同时向堆栈上下游移动——从实体 AI 的数据集,到企业运行框架和领域专用智能体——但共同主线都是控制权。
6. 新动态与亮点¶
ScamAgent 把对提示词注入的焦虑变成了一整条多轮诈骗流水线¶
@HowToAI_ 总结(3 次点赞、1 条回复、147 次浏览、2 次收藏)了一篇重要性远高于互动量的论文:ScamAgents。论文指出,一个自主智能体可以保留对话记忆、调整说服策略,并借助文本转语音把诈骗脚本变成逼真的语音来电;而当前护栏之所以失效,是因为恶意意图会被拆分并伪装,分散到多轮交互之中。

LLM-Metrics 提出从模型记忆推断研究影响力的评分方法¶
@SciFi 链接(2 次点赞、1 条回复、100 次浏览、1 次收藏)了 《LLM-Metrics》论文。这篇论文尝试从大语言模型“记住了什么”来推断研究影响力。作者评估了 17 个模型上的 549 篇计算机科学论文,发现与引用量存在正向关联,但幅度不高(rho = 0.1495);其中作者识别探针效果最强,而一个 3B 的 Llama 模型甚至超过了许多更大的模型。即便这种方法最终仍是小众方向,它也说明评估正在走向引用量和基准测试榜单之外的新表面。
《Under Training》把模型机制包装成一款交互式浏览器游戏¶
@om_patel5 分享(102 次点赞、9 条回复、13,604 次浏览、86 次收藏)了一款名为 “Under Training” 的浏览器游戏,玩家会像大语言模型一样经历原始数据摄入、训练、推理和实时评估。回复很快不再只是玩梗,而是进一步追问:这款游戏能否诚实地呈现上下文窗口滑脱、过拟合和灾难性遗忘?这让它不只是一张 meme,而是 AI 素养本身正在变成产品表面的信号。
AI Growth Zones 把 AI 基础设施变成了分区与治理故事¶
@EuropeanPowell 链接(13 次点赞、10 次转发、228 次浏览、3 次收藏)了一篇 Tribune 文章,认为英国的 AI Growth Zones 正把自由区逻辑延伸到数字领域。文章称,这项政策已吸引 200+ 个地点申请,并把 AI 纳入更广泛的 Industrial Strategy Zones 框架。无论是否认同文章的政治立场,它都提醒人们:AI 部署如今也已经是规划、税收和地方治理议题。
7. 机会在哪里¶
[+++] 面向真实工作流的智能体控制平面 - 5 月 23 日最强的证据表明,难点已经不再是生成一个答案,而是如何约束动作、评估轨迹、跟踪成本,并在输出进入生产环境前做完复审。证据来自 Hermes 的工作流热度、Outcome School 的评估指南、Jahir Sheikh 的生产系统清单、牙科排班失败案例、WSJ 的危险代码讨论串,以及《ScamAgents》论文。
[++] 面向长时运行智能体的记忆、评估与 QA 层 - Sibyl 的 LongMemEval 表、Gemini 3.5 Flash 的工作流基准测试、LLM-Metrics 论文,以及 Smartling 基于 MQM 的 LQA 发布,都在指向同一个缺口:人们需要更好的方式,去衡量随时间变化的记忆、工具使用和质量。这个机会是中等强度,因为已经有多种部分解法存在,但还没有任何一个方案能跨领域占据主导。
[++] 主权化、可证明的 AI 部署堆栈 - Wira、NEAR 的私有推理,以及 AI Growth Zones 这篇文章,都说明买方越来越在意本地性、治理和可证明性。这已经不只是“端侧部署很酷”的热情,而是围绕气隙隔离部署、签名证明,以及更利于采购的基础设施叙事的一整套堆栈机会。
[++] 用领域专用 AI 运行框架替代通用封装层 - KaliGPT、Smartling 的翻译堆栈,以及 Wira 点名的运行框架,都在把 AI 包装进有边界的具体用例,而不是只围绕通用模型访问来做产品。牙科 SaaS 的故事进一步强化了这一点:当广义自治承诺失灵时,范围更窄、更可检查的工具可能反而会赢。
[+] 多语言 AI 质量基础设施 - Smartling 的发布是一个直接信号:多语言 QA、适配和风格控制,正在变成独立的产品层。那条追问“如何在不浪费 token 的情况下规模化做 LLM 评估”的回复,说明这里依然有留给竞品或配套工具的空间。
[+] 实体 AI 数据与开放 VLA 评估 - Allen AI 的 pegboard 数据集,是一个小但可信的信号:实体 AI 构建者想要更多公开数据和基准测试。相较软件智能体工具链,这个方向仍然更早期,但在数据集、评估运行框架和控制堆栈交汇处,机会已经开始浮现。
8. 要点总结¶
- 重心已经从模型转向控制平面。 时间线里最重要的问题,不再是“哪个模型赢了”,而是哪种编排、评估和复审结构,能让智能体在生产环境中既安全又有用。(Hermes; AI 智能体评估指南; Jahir Sheikh)
- 基础设施讨论变得更“物理”了。 公开讨论已经从泛泛的算力稀缺,转向单核 DRAM、电力需求和数据中心容量;其中一张 Goldman Sachs 图表预测,到 2030 年智能体 token 增长 24x,美国数据中心需求将超过 100 GW。(jukan05; Goldman Sachs 图表; LLuciano_BTC)
- 面对多轮智能体,提示词时代的安全假设显得过于脆弱。 ScamAgents 是当天数据里最鲜明的证据:恶意意图可以在多轮之间被隐藏,却仍然穿透当前护栏。(《ScamAgents》论文; 推文摘要)
- 信任正靠本地性和证明来售卖。 Wira 的气隙隔离主权堆栈,以及 NEAR 的签名证明流程,都说明买方越来越想知道模型跑在哪里,以及这件事如何被验证。(Wira 文章; NEAR 私有推理)
- 构建者正在围绕工作流、QA 和领域边界发货,而不是推出裸模型封装层。 Smartling 把翻译包进评估和路由,KaliGPT 把模型访问包进安全导向 CLI,Allen AI 则发布了一个任务专用的实体 AI 数据集,而不是再做一个通用基准测试。(Smartling 发布; KaliGPT; Allen AI 数据集)
- 评估正在裂变成更专门的表面。 当天最强的测量工件,跟踪的是记忆行为、重工作流的智能体基准测试,甚至是通过模型记忆估算研究影响力;这说明泛化排行榜文化会继续把份额让给更窄、但更偏运营的指标。(Sibyl memory plugin; Gemini 3.5 Flash; LLM-Metrics)