Twitter AI - 2026-05-24¶
1. What People Are Talking About¶
1.1 Agent adoption is getting judged on routing, trust, and local performance 🡕¶
The biggest practical theme on May 24 was not that agents are suddenly smarter. It was that people are starting to talk about them like operating systems: who trusts them, how teams route around cost, and what real hardware can sustain them. At least five retained items pointed at the same shift.
@AlexFinn argued (646 likes, 53 replies, 32,868 views, 880 bookmarks) that Hermes Agent is “the most powerful AI tool right now,” but the replies made the real signal clearer than the video pitch. One user said adding Mempalace turned it into a persistent memory system, another said trust depends on whether it can do repeatable work “without freelancing the architecture,” and a third said Hermes only works when it gets clean context, clear boundaries, and a review gate.
@sdianahu outlined (210 likes, 20 replies, 26,056 views, 90 bookmarks) a more explicit operating playbook for AI-native startups. The thread says founders should use the best models to find model/product fit, then custom-route easier queries to smaller models so that 60-80% of production traffic becomes 10-100x cheaper, while using speculative decoding, KV-cache optimizations, and later trace distillation to hold margins.
@tmophoto reported (46 likes, 9 replies, 5,933 views, 26 bookmarks) that llama.cpp hit 99.45 tok/s on a 35B model on a dual RTX 3090 setup, versus LM Studio at 47.43 tok/s, and that MTP draft max 2 beat draft max 4. The replies turned that into a tooling comparison: one person said vLLM could go higher, while the author pushed back that GGUF incompatibility and heavyweight model downloads are still real reasons people stay on simpler local stacks.
@ClementDelangue shared (41 likes, 12 replies, 3,439 views, 8 bookmarks) a Hugging Face hardware snapshot built from 300,000 self-reported builder profiles. The page says 45% of listed rigs use NVIDIA hardware, 32% CPUs, 17% Apple Silicon, and 5% AMD, while RTX 30xx, 40xx, and 50xx cards dominate the disclosed NVIDIA mix.

The image matters because it turns “local AI is exploding” into an actual installed-base snapshot instead of a vague impression.
@iam_chonchol argued (16 likes, 8 replies, 3,143 views, 4 bookmarks) that memory, not intelligence, is the real bottleneck. The follow-up thread claimed BitCPM-CANN’s 1.58-bit ternary training approach delivers roughly 6x memory savings versus BF16, retains 93-99% of benchmark performance across 1B-8B models, and was trained natively on Huawei Ascend 910B/910C hardware.
Discussion insight: The strongest replies did not ask for better prompts. They asked for memory persistence, review gates, architecture constraints, cheaper routing, and hardware-aware deployment choices.
Comparison to prior day: The previous week’s data was dominated by compute scarcity and agent cost. May 24 moved one layer closer to operations: routing policies, inference engines, and the actual machines people are trying to run AI on.
1.2 Verification became a first-class AI problem across misinformation, evals, and security 🡕¶
The second major cluster treated verification as the real bottleneck. The common question was no longer “can the model do it?” but “how do you prove what happened, in the real environment, before damage or drift shows up?” At least six retained items supported that pattern.
@georgeviews argued (500 likes, 8 replies, 15,147 views, 31 bookmarks) that a politically charged child-safety clip had been AI-edited. The value of the post for this daily report is not the political argument itself; it is that the attached comparison frames turned it into a public verification exercise, with replies demanding action against misinformation spreaders rather than debating model capability in the abstract.
@soyouIJ summarized (9 likes, 3 replies, 92 views) WildClawBench, a benchmark of 60 human-authored, bilingual, multimodal tasks running inside real Docker environments. The paper says tasks average about 8 minutes and 20+ tool calls, the best system only reaches 62.2%, and swapping harnesses alone can shift a single model by up to 18 points.

That chart matters because it makes benchmark skepticism concrete: current frontier agents still struggle once evaluation moves into real runtimes with side effects.
@inferencemedia argued (1 like, 1 reply, 90 views) that 49% of failed enterprise AI pilots cite evaluation gaps, and the attached image maps 14 evaluation platforms plus eight criteria for choosing among them. @IFPRI shared (3 likes, 1 reply, 303 views) an evaluation framework for agricultural AI systems that explicitly splits evaluation into model, system, and process layers, arguing that usability, trust, and equity failures can sink a deployment even when the model looks good on paper.
@TechCrunch reported (8 likes, 3 replies, 4,060 views, 2 bookmarks) that AI security teams are already dealing with incident windows far shorter than traditional software teams are used to. The linked article says attack handoff time can collapse from 8 hours to 22 seconds, agents can surface forgotten internal repositories, and some deleted Google API keys were still observed working for up to 23 minutes.
@Pirat_Nation shared (88 likes, 13 replies, 5,334 views, 16 bookmarks) figures from Anthropic’s Project Glasswing, saying a vulnerability-finding model uncovered 23,019 issues across 1,000 open-source projects, with 6,202 rated high or critical and about 90.6% confirmed as real problems.
Discussion insight: Across these posts, the desired fix was not “better AI.” It was source comparison, runtime verification, environment-aware benchmarks, and continuous security monitoring.
Comparison to prior day: Earlier days in the week questioned benchmark legitimacy and AI safety at a policy level. May 24 made the same concern operational by tying it to deepfakes, eval procurement, vulnerability scanning, and live security response.
1.3 Builders kept shipping workflow-specific AI systems instead of generic chatbots 🡕¶
The build signal on May 24 was about packaging. The strongest artifacts were not generic assistants or base-model launches, but systems that wrap data, evaluation, and deployment around a narrow workflow. At least five items supported that theme.
@DanKornas shared (10 likes, 2 replies, 1,053 views, 6 bookmarks) FluxVLA Engine, an open-source robotics/VLA platform that keeps training, evaluation, inference, deployment, and model configuration in one place. The GitHub repo says it supports OpenVLA, LlavaVLA, GR00T, Pi0/Pi0.5, ZMQ-based remote inference, and LIBERO evaluation rather than leaving embodied-AI teams to glue the whole stack together with separate scripts.
@HuggingPapers highlighted (13 likes, 816 views, 3 bookmarks) AllenAI’s OpenVLA pegboard dataset, which URL inspection shows contains 50 episodes and 76,921 frames from three camera views with 14-D action/state control in LeRobot format. The same release wave also included a companion MolmoAct pegboard dataset with 52 episodes and 45,221 frames.
@mrasero_ pointed (2 likes, 1 reply, 663 views) to Runflow, which says it runs production AI-image workflows across 736 models, scores them with Sentinel, and can auto-regenerate failed outputs. That is a very different product shape from a plain text-to-image endpoint: it is infrastructure plus evaluation plus retry logic.
@ADesaiMD presented (2 likes, 1 reply, 48 views, 1 bookmark) OncoSphere AI as an agentic oncology workflow that reasons across guidelines, trial data, imaging, and pathology the way a tumor board does. The attached validation slide says preparation time fell 84%, which makes the project notable as workflow automation rather than chatbot summarization.
@richardokunolar showed (3 likes, 1 reply, 108 views) NaijaTax IQ from a mentorship capstone session, with a working accounting/tax UI rather than a concept thread. Even at small scale, it is another example of agentic AI being packaged around a narrow operational job.
Discussion insight: The shared pattern was stack compression: one-config robotics, reusable eval datasets, scored image pipelines, oncology workflow agents, and tax/accounting assistants. The day’s builders were packaging complete loops, not just shipping model wrappers.
Comparison to prior day: Earlier in the week, AI Twitter talked more about agent cost and security as constraints. May 24 showed what people are building once they accept those constraints: workflow-native systems with evaluation and deployment baked in.
1.4 AI access is becoming more institutional through official courses and mainstream packaging 🡕¶
The final notable theme was distribution. The May 24 feed contained a clear mix of vendor-run course catalogs, open-source builder curricula, and mass-market AI product packaging. At least four retained items supported it.
@HowToAI_ noted (5 likes, 1 reply, 179 views, 9 bookmarks) that Anthropic now has 18 official AI courses. Inspecting the Skilljar pages confirms that the catalog spans Claude, Claude Code, API work, MCP, subagents, and Bedrock/Vertex deployment tracks rather than just a single onboarding lesson.
The screenshot matters because it turns a low-engagement tweet into clear evidence that a vendor-run Claude/Claude Code learning hub exists.
@akjsal shared (4 likes, 1 reply, 175 views, 3 bookmarks) LLM Zoomcamp 2026, a free 10-week builder course on RAG, vector search, agents, orchestration, evaluation, and monitoring that says no GPU is required and API costs can stay around $1-5. @cyrilXBT promoted (40 likes, 5 replies, 1,030 views, 29 bookmarks) a free Harvard AI curriculum on YouTube that covers prompting, GitHub Copilot, decision algorithms, deep learning, and hallucinations.
@ABC reported (14 likes, 16 replies, 18,842 views, 4 bookmarks) Google’s next wave of AI tools, and the linked AP article adds the more important details: Gemini Spark as a background agent that keeps working in the cloud, Gemini Omni for editable video generation, and SynthID/content credentials for generated media.
Discussion insight: The common move was structured onboarding: official course catalogs, reusable syllabi, and consumer-friendly wrappers around agent behavior.
Comparison to prior day: The prior week already had scattered workforce-training posts. May 24 made that more formal by combining vendor-run Claude education with free open courses and mainstream product packaging from Google.
2. What Frustrates People¶
Opaque pricing and compute economics still break trust¶
The sharpest direct complaint was about pricing honesty. @GergelyOrosz wrote (63 likes, 15 replies, 7,918 views, 16 bookmarks) that OpenArt showed one credit requirement for a 3-minute video before signup, then 10x the credits after payment, leaving him feeling “scammed” after spending $29 on weak results. That complaint lines up with the more strategic version from @sdianahu outlining (210 likes, 20 replies, 26,056 views, 90 bookmarks) why AI-native startups now need custom routing just to survive the economics of frontier models. Current coping behavior is visible in the same day’s evidence: route easier queries to smaller models, use speculative decoding and KV-cache tricks, or move toward local inference where possible. Severity: High. Worth building for: yes — transparent pricing, quality disclosure, and margin-aware routing are still missing from many AI products.
Verification gaps still block deployment and public trust¶
The broadest frustration was that AI systems remain hard to verify before they cause problems. @georgeviews argued (500 likes, 8 replies, 15,147 views, 31 bookmarks) that a quote-tweeted political clip had been AI-edited, and the evidence people focused on was the side-by-side comparison imagery rather than the rhetoric around it. @inferencemedia said (1 like, 1 reply, 90 views) that 49% of failed enterprise AI pilots cite evaluation gaps, @IFPRI shared (3 likes, 1 reply, 303 views) a model/system/process evaluation framework for field AI deployments, and @soyouIJ summarized (9 likes, 3 replies, 92 views) WildClawBench, where even the best system only reached 62.2% on long-horizon Docker tasks. @TechCrunch reported (8 likes, 3 replies, 4,060 views, 2 bookmarks) that AI security incidents are already compressing from hours to seconds, and @WSJ shared (2 likes, 3 replies, 733 views) a chart arguing that Americans’ negative feelings toward AI are rising faster than the industry itself.
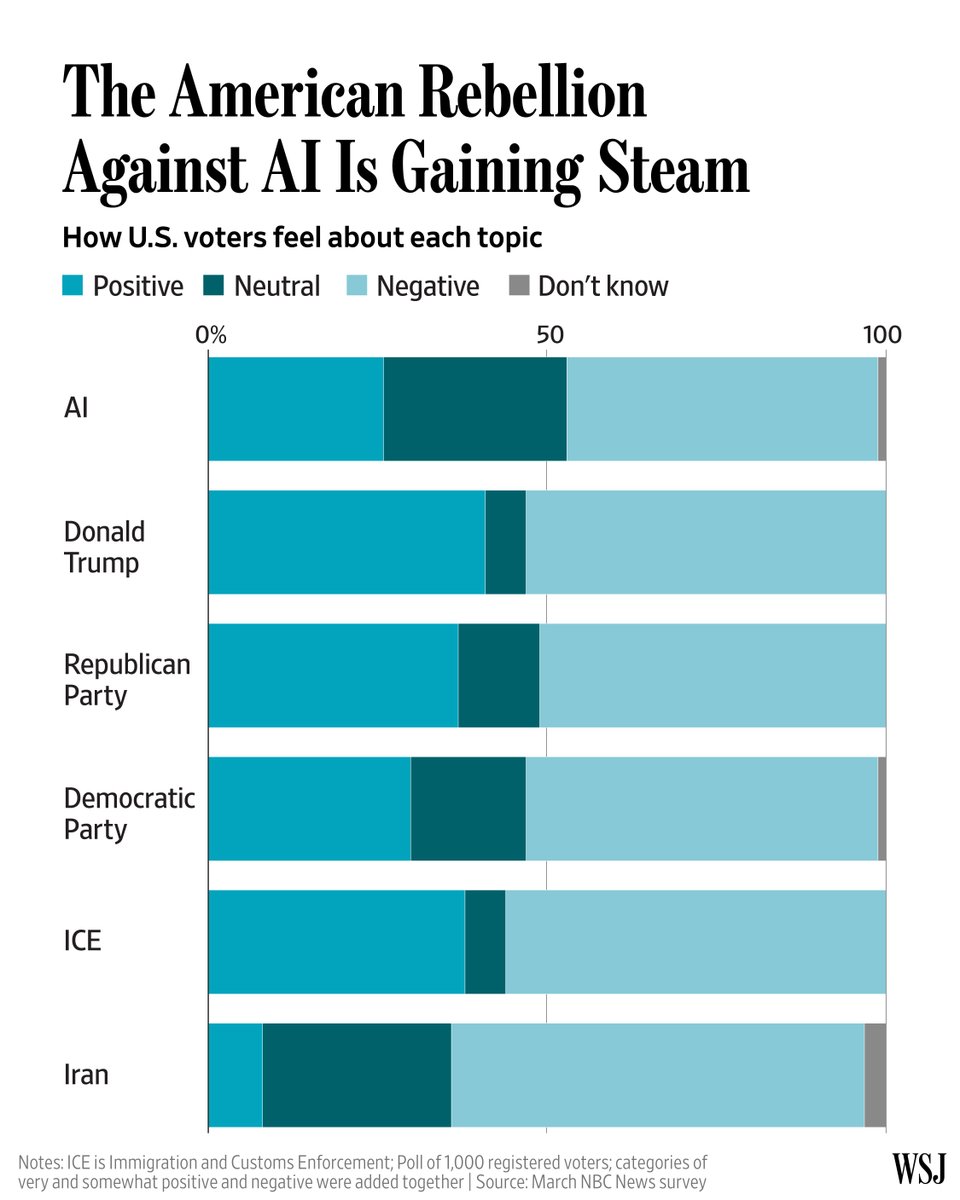
The coping strategies in the feed are all forms of extra verification: compare source footage, use real-runtime benchmarks, buy dedicated evaluation tooling, and run tighter security monitoring. Severity: High. Worth building for: yes — this is one of the clearest unmet infrastructure layers in the day’s data.
Local AI is real, but still bottlenecked by memory and configuration work¶
The local-AI conversation was enthusiastic, but still full of friction. @ClementDelangue shared (41 likes, 12 replies, 3,439 views, 8 bookmarks) hard numbers showing that builders are using NVIDIA, CPUs, Apple Silicon, and AMD in meaningful volumes, which implies a fragmented hardware base rather than one standard target. @tmophoto reported (46 likes, 9 replies, 5,933 views, 26 bookmarks) that local throughput swings dramatically based on inference engine and MTP settings, while a reply recommending vLLM ran into a familiar objection: GGUF incompatibility and huge downloads. @iam_chonchol argued (16 likes, 8 replies, 3,143 views, 4 bookmarks) that memory is the real bottleneck and pointed to BitCPM-CANN as a possible answer.
Severity: Medium-High. The visible workaround is manual tuning: pick engines case by case, test multiple MTP settings, and hunt for lighter low-bit models. Worth building for: yes — hardware-aware inference setup and memory-efficient local stacks are still too operator-heavy.
3. What People Wish Existed¶
A reviewable control plane for agent behavior¶
The clearest missing layer is a system that makes agent behavior inspectable before, during, and after execution. @AlexFinn argued (646 likes, 53 replies, 32,868 views, 880 bookmarks) that Hermes is powerful, but the replies immediately reframed value around memory, review gates, and clean boundaries. @inferencemedia said (1 like, 1 reply, 90 views) that 49% of failed enterprise AI pilots cite evaluation gaps, @soyouIJ summarized (9 likes, 3 replies, 92 views) a benchmark where the best setup only reached 62.2%, and @TechCrunch reported (8 likes, 3 replies, 4,060 views, 2 bookmarks) that live AI security windows are already collapsing from hours to seconds. This is a practical need with high urgency. Partial answers exist in benchmark suites, evaluation maps, and security tooling, but the data still shows a fragmented stack rather than one reviewable control plane. Opportunity: direct.
Honest pricing and hardware-aware deployment guidance¶
People also want AI systems whose operating costs and hardware fit are understandable before they buy or deploy them. @GergelyOrosz described (63 likes, 15 replies, 7,918 views, 16 bookmarks) a bait-and-switch experience in video AI credits, while @sdianahu explained (210 likes, 20 replies, 26,056 views, 90 bookmarks) that serious AI startups now need explicit query routers just to make margins work. @tmophoto showed (46 likes, 9 replies, 5,933 views, 26 bookmarks) how much local performance can swing between inference engines, and @ClementDelangue shared (41 likes, 12 replies, 3,439 views, 8 bookmarks) evidence that there is no single default local-AI machine profile. This is a practical need with high urgency. Partial answers exist in routing playbooks, hardware dashboards, and low-bit work such as BitCPM-CANN, but the feed still shows too much manual guesswork. Opportunity: direct.
Local-language AI that is sovereign in data, infrastructure, and law¶
The strongest geography-specific need was not for “a local model” in the abstract, but for a full stack that reflects local language and governance. @OmarKamali wrote (18 likes, 3 replies, 1,135 views, 2 bookmarks) that if AI is going to reshape work in Morocco, it has to understand Morocco and be built on local data, speech, NLP, embeddings, evaluation, infrastructure, and legal alignment. @DivaJain2 argued (79 likes, 3 replies, 2,060 views, 20 bookmarks) that China is already pushing beyond strong models into AI-native consumer use cases, and the screenshots plus replies pointed to Doubao as a proof point for accessible AI packaging. This need is both practical and strategic. Partial answers exist in local ecosystem efforts and sovereign-AI rhetoric, but the supporting stack is still incomplete in underrepresented languages. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Hermes Agent | Agent platform | (+/-) | Flexible multi-step workflows; memory and docs-recall use cases resonated | Trust depends on boundaries, review gates, and visible controls |
| Query routing + speculative decoding | Inference orchestration | (+) | Can move 60-80% of traffic to much cheaper models; protects margins | Requires custom routing logic and a strong understanding of query difficulty |
| llama.cpp | Local inference engine | (+) | Hit 99.45 tok/s on a 35B model in one dual-3090 test; strong for GGUF-style local work | Highly tuning-sensitive; MTP settings materially change results |
| LM Studio | Local inference app | (+/-) | Easy local workflow and side-by-side benchmarking | Roughly half the throughput of llama.cpp in the cited test |
| vLLM | Inference engine | (+/-) | Reply evidence suggests much higher throughput is possible on the same hardware | GGUF friction and large model downloads keep some users away |
| Hugging Face Hardware | Hardware observability | (+) | Exposes real community hardware mix across 300,000 builder profiles | Self-reported ownership data does not guarantee workload fit |
| BitCPM-CANN | Low-bit modeling | (+) | Claims 6x memory savings versus BF16 and a path toward lighter local/edge models | Still early and thread-reported; tied to Ascend/CANN-specific tooling |
| WildClawBench | Agent evaluation benchmark | (+) | Real Docker tasks, hybrid grading, and harness sensitivity make it more realistic than synthetic leaderboards | Even the top setup only reached 62.2%, showing the problem remains unsolved |
| Glasswing / Claude Mythos Preview | AI security scanning | (+) | Claimed high-volume vulnerability discovery with strong confirmation rates | Evidence is mostly tweet-level and early-access; open technical detail is limited |
| Runflow + Sentinel | AI image workflow/evaluation | (+) | Scores outputs, catches bad inputs, and auto-regenerates failed generations across many models | Specific to image pipelines and still exposed to upstream model economics |
| FluxVLA Engine | Robotics/VLA platform | (+) | One-config path from data to training, evaluation, inference, and deployment | Demands robotics-specific infrastructure and CUDA-heavy setup |
| X2SAM | Multimodal segmentation model | (+) | Unifies image and video segmentation with text and visual prompts in one interface | Still a research-stage system rather than a proven production tool |
Below the table, the overall pattern is clear: people are no longer talking about “AI tooling” as one category. They are talking about concrete layers — agent shells, routers, inference engines, eval benchmarks, vuln scanners, and workflow-specific platforms. The satisfaction curve is split. People sound most positive when a tool narrows the problem and exposes operational detail, and most negative when pricing, evaluation, or hardware fit remains opaque.
Migration patterns were also visible. The cost-control playbook is to route from frontier models toward smaller ones once a workload is understood. The local-inference playbook is to compare engines directly rather than assume one default stack; the cited tmophoto thread and replies effectively framed llama.cpp, LM Studio, and vLLM as tradeoffs between speed, model format support, and setup burden. On the evaluation side, the shift is away from tidy sandboxes and toward native-runtime benchmarks, tool-selection scorecards, and security layers that watch live systems.
@sijlalhussain argued (10 likes, 1 reply, 126 views, 2 bookmarks) that generative AI should be treated as one layer inside a much larger enterprise AI system, citing Gartner.

That image matters because it captures the day’s broader technology takeaway: GenAI is not replacing the rest of the stack; it is being slotted into a wider operational system.
Training content is starting to standardize around that layered view. Anthropic’s course catalog, LLM Zoomcamp’s syllabus, and the Harvard curriculum all organize AI practice around concrete workflows such as RAG, agents, orchestration, evaluation, monitoring, MCP, and Claude Code rather than around vague “prompting tips.”
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| FluxVLA Engine | FluxVLA / limxdynamics | Full-stack engineering platform for training, evaluating, and deploying VLA systems | Replaces fragmented embodied-AI workflows spread across multiple scripts and tools | Python, PyTorch, OpenVLA, LlavaVLA, GR00T, Pi0/Pi0.5, LIBERO, ZMQ remote inference | Beta | GitHub · tweet |
| Runflow | Runflow team | AI-image workflow and evaluation API with scoring and regeneration | Helps teams keep image-generation features reliable and profitable in production | 736 models, Sentinel scoring, auto-regeneration, custom open-model workflows including Qwen Edit and Flux | Shipped | site · tweet |
| OncoSphere AI | @ADesaiMD | Agentic oncology workflow that reasons across guidelines, trials, imaging, and pathology | Reduces manual prep and workflow coordination for tumor-board style decision support | Agentic AI, clinical guidelines, trial data, imaging, pathology | Alpha | tweet |
| NaijaTax IQ | @richardokunolar and MC7.0 mentees | Accounting and tax assistant with a working UI | Packages narrow finance workflows into a more concrete agent surface than generic chat | Agentic AI workflow, tax/accounting interface | Alpha | tweet |
| AllenAI pegboard VLA datasets | AllenAI / LeRobot | Public OpenVLA and MolmoAct pegboard evaluation datasets | Gives embodied-AI teams reproducible multimodal benchmark data | Hugging Face datasets, LeRobot, 3 cameras, 14-D control/state data | Shipped | OpenVLA dataset · MolmoAct dataset · tweet |
| X2SAM | Sun Yat-sen University / Peng Cheng Laboratory / Meituan | Unified segmentation model for images and videos using conversational and visual prompts | Avoids having separate segmentation systems for image-only and video-only workflows | MLLM, Mask Memory, V-VGD benchmark | Alpha | paper · project · tweet |
The most important pattern is that the projects are shipping whole loops, not isolated models. @DanKornas shared (10 likes, 2 replies, 1,053 views, 6 bookmarks) FluxVLA as a one-config robotics stack, and the repository backs that up with deployment docs, remote inference support, and benchmark tables instead of just a concept statement.

Runflow shows the same packaging instinct in a different market. The Runflow site says the product is not just a generation API; it combines scoring, guardrails, retry logic, and infrastructure so that image features survive production traffic and margin pressure.
@ADesaiMD presented (2 likes, 1 reply, 48 views, 1 bookmark) OncoSphere AI as a tumor-board workflow agent rather than a clinical chatbot, and the slide is the strongest evidence because it shows the workflow and a claimed 84% time reduction.

@richardokunolar showed (3 likes, 1 reply, 108 views) a working NaijaTax IQ interface during an agentic-AI mentorship capstone, which matters because it is visibly tied to accounting and tax operations rather than a broad assistant claim.

The other repeated build pattern is evaluation-first infrastructure. AllenAI’s paired pegboard datasets and X2SAM’s benchmark-heavy release both show teams shipping data, methods, and artifacts together, while FluxVLA and Runflow package evaluation into the product itself. The trigger pain point behind many of these builds is the same one visible elsewhere in the report: generic AI interfaces are not trusted until they are narrowed into a workflow with explicit checks.
6. New and Notable¶
WildClawBench made “real agent evaluation” concrete¶
@soyouIJ summarized (9 likes, 3 replies, 92 views) WildClawBench, and the paper is notable because it replaces synthetic eval talk with 60 human-authored, bilingual, multimodal Docker tasks that average about 8 minutes and 20+ tool calls. The best setup only reached 62.2%, and harness choice alone could move performance by up to 18 points. That makes it one of the clearest public artifacts in this dataset showing how much frontier-agent evaluation still depends on the runtime wrapper, not just the base model.
Anthropic formalized the Claude learning stack¶
@HowToAI_ highlighted (5 likes, 1 reply, 179 views, 9 bookmarks) Anthropic’s course catalog, and URL inspection confirmed official tracks for Claude, Claude Code, MCP, subagents, API work, and cloud deployments. That matters because it turns what was recently scattered tribal knowledge into vendor-supported curriculum. It is a small tweet, but a meaningful signal about where the Claude ecosystem is heading.
Google kept pushing proactive agents toward mainstream packaging¶
@ABC reported (14 likes, 16 replies, 18,842 views, 4 bookmarks) Google’s next AI launch wave, and the inspected AP article is what makes it notable: Gemini Spark is framed as a background agent that keeps working in the cloud, while Gemini Omni pushes editable video generation and SynthID extends content credentials. The story is less about one model upgrade than about consumer packaging for proactive AI systems.
Research releases kept widening the usable multimodal stack¶
@jiqizhixin shared (9 likes, 1 reply, 897 views, 4 bookmarks) X2SAM, whose paper and project page describe a unified image-and-video segmentation model with conversational and visual prompts, a Mask Memory module, and a new V-VGD benchmark. @SciFi posted (2 likes, 1 reply, 117 views, 1 bookmark) the LLM-Metrics paper, which tests whether LLM memory of research papers correlates with research impact. Together, they show the day’s research signal widening beyond text chat into segmentation, benchmarking, and measurement itself.
7. Where the Opportunities Are¶
[+++] Reviewable agent operations — Multiple sections point here at once: @AlexFinn surfaced (646 likes, 53 replies, 32,868 views, 880 bookmarks) the trust problem, @inferencemedia called out (1 like, 1 reply, 90 views) evaluation gaps, WildClawBench showed low real-runtime success ceilings, and @TechCrunch reported (8 likes, 3 replies, 4,060 views, 2 bookmarks) live AI-security compression. The opportunity is strong because the same need shows up in agent UX, benchmarking, security, and enterprise deployment.
[++] Local-AI deployment and optimization tooling — The Hugging Face hardware page, @tmophoto benchmark thread (46 likes, 9 replies, 5,933 views, 26 bookmarks), BitCPM-CANN memory claims, and @sdianahu routing playbook (210 likes, 20 replies, 26,056 views, 90 bookmarks) all point to the same gap: builders need help matching workloads to hardware, engines, and model sizes without hand-tuning everything themselves.
[++] Workflow-native vertical agents — @ADesaiMD presented (2 likes, 1 reply, 48 views, 1 bookmark) an oncology workflow agent, @richardokunolar showed (3 likes, 1 reply, 108 views) a tax/accounting UI, Runflow packages production image evaluation, and FluxVLA packages embodied-AI deployment. The moderate signal is that the winning pattern is not generic chat, but narrow systems with evaluation and workflow logic built in.
[+] Local-language sovereign AI stacks — @OmarKamali spelled out (18 likes, 3 replies, 1,135 views, 2 bookmarks) the missing layers for Morocco, while @DivaJain2 pointed to (79 likes, 3 replies, 2,060 views, 20 bookmarks) China’s AI-native consumer packaging. The signal is emerging rather than dominant, but it is one of the few places in the dataset where language, infrastructure, law, and product distribution are discussed as one stack.
8. Takeaways¶
- Agent enthusiasm is surviving, but only when the workflow is constrained. @AlexFinn showed (646 likes, 53 replies, 32,868 views, 880 bookmarks) that the highest-engagement agent thread quickly became a discussion about memory persistence, clean context, and review gates, while @sdianahu outlined (210 likes, 20 replies, 26,056 views, 90 bookmarks) routing and distillation once PMF is found.
- Verification is still the hardest infrastructure gap. @georgeviews flagged (500 likes, 8 replies, 15,147 views, 31 bookmarks) an alleged AI-edited misinformation clip, WildClawBench showed low real-runtime success ceilings, and @TechCrunch reported (8 likes, 3 replies, 4,060 views, 2 bookmarks) live security failures, all pointing to the same proof problem.
- Local AI is no longer niche, but it is still too operator-heavy. The Hugging Face hardware page shows broad adoption across many hardware types, while @tmophoto measured (46 likes, 9 replies, 5,933 views, 26 bookmarks) large engine-to-engine throughput swings and @iam_chonchol argued (16 likes, 8 replies, 3,143 views, 4 bookmarks) that memory remains the core bottleneck.
- The strongest build pattern is workflow packaging, not another chatbot. @DanKornas shared (10 likes, 2 replies, 1,053 views, 6 bookmarks) FluxVLA, @ADesaiMD presented (2 likes, 1 reply, 48 views, 1 bookmark) OncoSphere AI, and Runflow packaged evaluation and deployment around specific jobs to be done.
- AI onboarding is becoming official and institutional at the same time that consumer packaging expands. @HowToAI_ highlighted (5 likes, 1 reply, 179 views, 9 bookmarks) Anthropic’s course catalog, LLM Zoomcamp offers a free builder syllabus, and @ABC reported (14 likes, 16 replies, 18,842 views, 4 bookmarks) Google’s Gemini Spark/Omni rollout.