Twitter AI - 2026-05-24¶
1. 人们在讨论什么¶
1.1 智能体的采用,正在按路由、信任和本地性能来被评价 🡕¶
5 月 24 日最大的实际主题,并不是智能体突然更聪明了,而是人们开始像谈操作系统一样谈论它们:谁会信任它们、团队如何绕开成本,以及真实硬件到底能撑住什么。至少有 5 条保留样本指向同一变化。
@AlexFinn 认为 Hermes Agent 是“现在最强大的 AI 工具”(646 次点赞、53 条回复、32,868 次浏览、880 次收藏),但回复区让真正的信号比视频宣传更清晰。一位用户说,加上 Mempalace 之后,它就变成了持久记忆系统;另一位说,信任取决于它能否在“不擅自改架构”的前提下做可重复工作;第三位则说,Hermes 只有在拿到干净上下文、明确边界和复审闸口时才真的好用。
@sdianahu 整理 出一套更明确的 AI 原生初创公司运营手册(210 次点赞、20 条回复、26,056 次浏览、90 次收藏)。这条讨论串写道,创始人应该先用最好的模型找到模型 / 产品匹配,再把更简单的查询定制路由到更小的模型上,这样 60-80% 的生产流量就能便宜 10-100x;同时再用 speculative decoding、KV-cache 优化,以及后续的轨迹蒸馏来守住利润率。
@tmophoto 表示(46 次点赞、9 条回复、5,933 次浏览、26 次收藏),在双 RTX 3090 配置上运行 35B 模型时,llama.cpp 达到了 99.45 tok/s,而 LM Studio 只有 47.43 tok/s;同时 MTP draft max 2 的表现好于 draft max 4。回复区把这变成了一场工具比较:有人说 vLLM 还能跑得更高,但作者反驳说,GGUF 不兼容和沉重的模型下载,依然是人们留在更简单本地栈上的现实原因。
@ClementDelangue 分享 了一张由 300,000 份构建者自报资料汇总而成的 Hugging Face 硬件快照(41 次点赞、12 条回复、3,439 次浏览、8 次收藏)。页面写道,在列出的设备中,45% 使用 NVIDIA 硬件、32% 使用 CPU、17% 使用 Apple Silicon、5% 使用 AMD;而在披露的 NVIDIA 配置中,RTX 30xx、40xx 和 50xx 系列占主导。

这张图之所以重要,是因为它把“本地 AI 正在爆发”变成了一张真实装机快照,而不是模糊印象。
@iam_chonchol 认为(16 次点赞、8 条回复、3,143 次浏览、4 次收藏),真正的瓶颈不是智能,而是记忆。后续讨论串声称,BitCPM-CANN 的 1.58-bit 三值训练方法,相比 BF16 可带来大约 6x 的记忆节省,在 1B-8B 模型上保留 93-99% 的基准测试表现,并且是在华为 Ascend 910B/910C 硬件上原生训练出来的。
讨论要点: 最强的回复并没有要求更好的提示词,而是在要持久记忆、复审闸口、架构约束、更便宜的路由,以及能感知硬件条件的部署选择。
与前日对比: 前一周的数据主要被算力稀缺和智能体成本主导。5 月 24 日又往运营层靠近了一层:路由策略、推理引擎,以及人们真正在尝试跑 AI 的那些机器本身。
1.2 验证在错误信息、评估和安全层面都成了一等 AI 问题 🡕¶
第二大讨论簇,把验证当成真正瓶颈。共同问题已经不再是“模型能不能做到?”,而是“在损害或漂移出现之前,你如何在真实环境里证明到底发生了什么?” 至少有 6 条保留样本支撑这一模式。
@georgeviews 认为 一段带有政治争议色彩的儿童安全短片被 AI 编辑过(500 次点赞、8 条回复、15,147 次浏览、31 次收藏)。这条帖子对本日报的价值,不在政治论点本身,而在于它附带的对比帧把事情变成了一场公开验证演练;回复区要求对错误信息传播者采取行动,而不是抽象争论模型能力。
@soyouIJ 总结 了 WildClawBench(9 次点赞、3 条回复、92 次浏览),这是一套在真实 Docker 环境里运行的 60 个由人类编写、双语、多模态任务的基准测试。论文写道,这些任务平均需要约 8 分钟和 20+ 次工具调用,最好的系统也只有 62.2%,而仅仅替换运行框架,就能让同一个模型的单项成绩波动多达 18 分。

这张图之所以重要,是因为它把人们对基准测试的怀疑具体化了:一旦评估进入带副作用的真实运行时,当前前沿智能体仍然明显吃力。
@inferencemedia 认为(1 次点赞、1 条回复、90 次浏览),49% 失败的企业 AI 试点都把问题归因于评估缺口,而配图则梳理了 14 个评估平台和 8 条选型标准。@IFPRI 分享 了一套面向农业 AI 系统的 评估框架(3 次点赞、1 条回复、303 次浏览),它明确把评估拆成模型、系统和流程三层,并指出:即便模型在纸面上表现不错,可用性、信任和公平性失效依然会拖垮部署。
@TechCrunch 报道(8 次点赞、3 条回复、4,060 次浏览、2 次收藏)称,AI 安全团队已经在面对远短于传统软件团队习惯的事故窗口。链接文章写道,攻击移交时间可能从 8 小时压缩到 22 秒,智能体能暴露出被遗忘的内部仓库,而一些已删除的 Google API key 仍被观察到最多继续生效 23 分钟。
@Pirat_Nation 分享 了 Anthropic 的 Project Glasswing 数据(88 次点赞、13 条回复、5,334 次浏览、16 次收藏),称一个漏洞发现模型在 1,000 个开源项目中找出 23,019 个问题,其中 6,202 个被评为高危或严重,约 90.6% 被确认是真问题。
讨论要点: 在这些帖子里,人们想要的修复并不是“更好的 AI”,而是源头对比、运行时验证、感知环境的基准测试,以及持续安全监控。
与前日对比: 本周前几天,人们还主要从政策层面质疑基准测试合法性和 AI 安全。5 月 24 日则把同样的担忧推进到了操作层:深度伪造、评估采购、漏洞扫描,以及实时安全响应。
1.3 构建者持续在交付面向工作流的 AI 系统,而不是通用聊天机器人 🡕¶
5 月 24 日的构建信号,核心是打包。最强的工件不是通用助手或基础模型发布,而是把数据、评估和部署围绕狭窄工作流包起来的系统。至少有 5 条内容支撑这一主题。
@DanKornas 分享 了 FluxVLA Engine(10 次点赞、2 条回复、1,053 次浏览、6 次收藏),这是一个开源机器人 / VLA 平台,把训练、评估、推理、部署和模型配置放在同一个地方。GitHub 仓库写道,它支持 OpenVLA、LlavaVLA、GR00T、Pi0/Pi0.5、基于 ZMQ 的远程推理,以及 LIBERO 评估,而不是让具身 AI 团队继续用分散脚本把整套栈手工粘起来。
@HuggingPapers 重点介绍 了 AllenAI 的 OpenVLA pegboard 数据集(13 次点赞、816 次浏览、3 次收藏);从 URL 检查可以看出,这个数据集包含 50 个 episode、76,921 帧、3 个相机视角,以及采用 LeRobot 格式的 14-D 动作 / 状态控制。同一波发布里还包含配套的 MolmoAct pegboard 数据集,共 52 个 episode 和 45,221 帧。
@mrasero_ 提到 Runflow(2 次点赞、1 条回复、663 次浏览),它写道自己能在 736 个模型上运行生产级 AI 图像工作流,用 Sentinel 评分,并自动重生成失败输出。这和普通文生图接口是非常不同的产品形态:它是基础设施 + 评估 + 重试逻辑。
@ADesaiMD 展示 了 OncoSphere AI(2 次点赞、1 条回复、48 次浏览、1 次收藏),把它描述成一个像肿瘤委员会一样,综合指南、试验数据、影像和病理来做判断的智能体式肿瘤学工作流。随附验证幻灯片称,准备时间下降了 84%,这使它更像工作流自动化,而不是聊天机器人式摘要。
@richardokunolar 展示 了来自一次导师制结业项目的 NaijaTax IQ(3 次点赞、1 条回复、108 次浏览),它给出的不是概念讨论串,而是一个可运行的会计 / 税务 UI。即便规模不大,这依然是把智能体式 AI 打包到狭窄运营岗位里的又一个例子。
讨论要点: 共同模式是栈压缩:一套配置搞定的机器人系统、可复用的评估数据集、带评分的图像流水线、肿瘤学工作流智能体,以及税务 / 会计助手。当天的构建者在打包完整闭环,而不只是发布模型外壳。
与前日对比: 本周更早的时候,AI Twitter 更常谈智能体成本和安全这些约束。到了 5 月 24 日,人们已经开始展示接受这些约束之后会构建什么:把评估和部署直接烤进产品里的工作流原生系统。
1.4 AI 获取路径正通过官方课程和大众化产品包装而变得更制度化 🡕¶
最后一个值得注意的主题是分发。5 月 24 日的时间线上,同时出现了厂商主导的课程目录、开源构建者课程,以及面向大众市场的 AI 产品包装。至少有 4 条保留样本支撑这一点。
@HowToAI_ 提到 Anthropic 现在已经有 18 门官方 AI 课程(5 次点赞、1 条回复、179 次浏览、9 次收藏)。检查 Skilljar 页面可以确认,这套目录覆盖 Claude、Claude Code、API 工作、MCP、subagents,以及 Bedrock/Vertex 部署路线,而不是只有一节入门课。
这张截图之所以重要,是因为它把一条低互动推文,变成了一个非常清晰的证据:Anthropic 确实已经有一套面向 Claude / Claude Code 的官方学习中心。
@akjsal 分享 了 LLM Zoomcamp 2026(4 次点赞、1 条回复、175 次浏览、3 次收藏),这是一套免费的 10 周构建者课程,覆盖 RAG、向量搜索、智能体、编排、评估和监控,并写明无需 GPU,API 成本也可控制在大约 $1-5。@cyrilXBT 推广 了一套 YouTube 上的免费 Harvard AI 课程(40 次点赞、5 条回复、1,030 次浏览、29 次收藏),内容覆盖提示词、GitHub Copilot、决策算法、深度学习和幻觉。
@ABC 报道 了 Google 下一波 AI 工具(14 次点赞、16 条回复、18,842 次浏览、4 次收藏),而链接的 AP 文章补上了更关键的细节:Gemini Spark 被描述成一种会在云端持续工作的后台智能体,Gemini Omni 用于可编辑视频生成,而 SynthID / 内容凭证则面向生成媒体。
讨论要点: 共同动作是结构化入门:官方课程目录、可复用教学大纲,以及围绕智能体行为做出的面向消费者的友好包装。
与前日对比: 前一周已经零散出现了劳动力培训帖子。5 月 24 日则把它进一步制度化:厂商主导的 Claude 教育、免费的开放课程,以及来自 Google 的大众化产品包装同时出现。
2. 令人困扰的问题¶
不透明的定价和算力经济学,仍在破坏信任¶
最尖锐的直接抱怨,来自定价诚实度。@GergelyOrosz 写道(63 次点赞、15 条回复、7,918 次浏览、16 次收藏),OpenArt 在注册前为 3 分钟视频显示的是一种积分需求,付款后却变成了 10 倍积分;花了 $29 得到糟糕结果后,他感觉自己“被坑了”。这条抱怨,与 @sdianahu 整理 的更战略化版本相互呼应(210 次点赞、20 条回复、26,056 次浏览、90 次收藏):AI 原生初创公司如今之所以需要自定义路由,只是为了在前沿模型的经济学下活下去。同一天的数据里已经能看到当前的绕行行为:把更简单的查询路由到更小的模型、使用 speculative decoding 和 KV-cache 技巧,或者在可能时转向本地推理。严重程度:高。值得做:是——透明定价、质量披露和具备利润率意识的路由,在很多 AI 产品里仍然缺位。
验证缺口仍在阻碍部署和公众信任¶
最广泛的挫败感在于,AI 系统在出问题之前依然难以验证。@georgeviews 认为 一段引用推文里的政治短片被 AI 编辑过(500 次点赞、8 条回复、15,147 次浏览、31 次收藏),而人们真正关注的证据,是并排对比图像,而不是围绕它的修辞。@inferencemedia 表示(1 次点赞、1 条回复、90 次浏览),49% 失败的企业 AI 试点都把原因归结于评估缺口;@IFPRI 分享 了一套面向实地 AI 部署的模型 / 系统 / 流程评估框架(3 次点赞、1 条回复、303 次浏览);而 @soyouIJ 总结 了 WildClawBench(9 次点赞、3 条回复、92 次浏览),其中即便最好的系统,在长周期 Docker 任务上也只有 62.2%。@TechCrunch 报道(8 次点赞、3 条回复、4,060 次浏览、2 次收藏)称,AI 安全事故窗口已经从数小时压缩到数秒;而 @WSJ 分享 了一张图(2 次点赞、3 条回复、733 次浏览),称美国人对 AI 的负面情绪上升速度,甚至快于行业本身的发展速度。
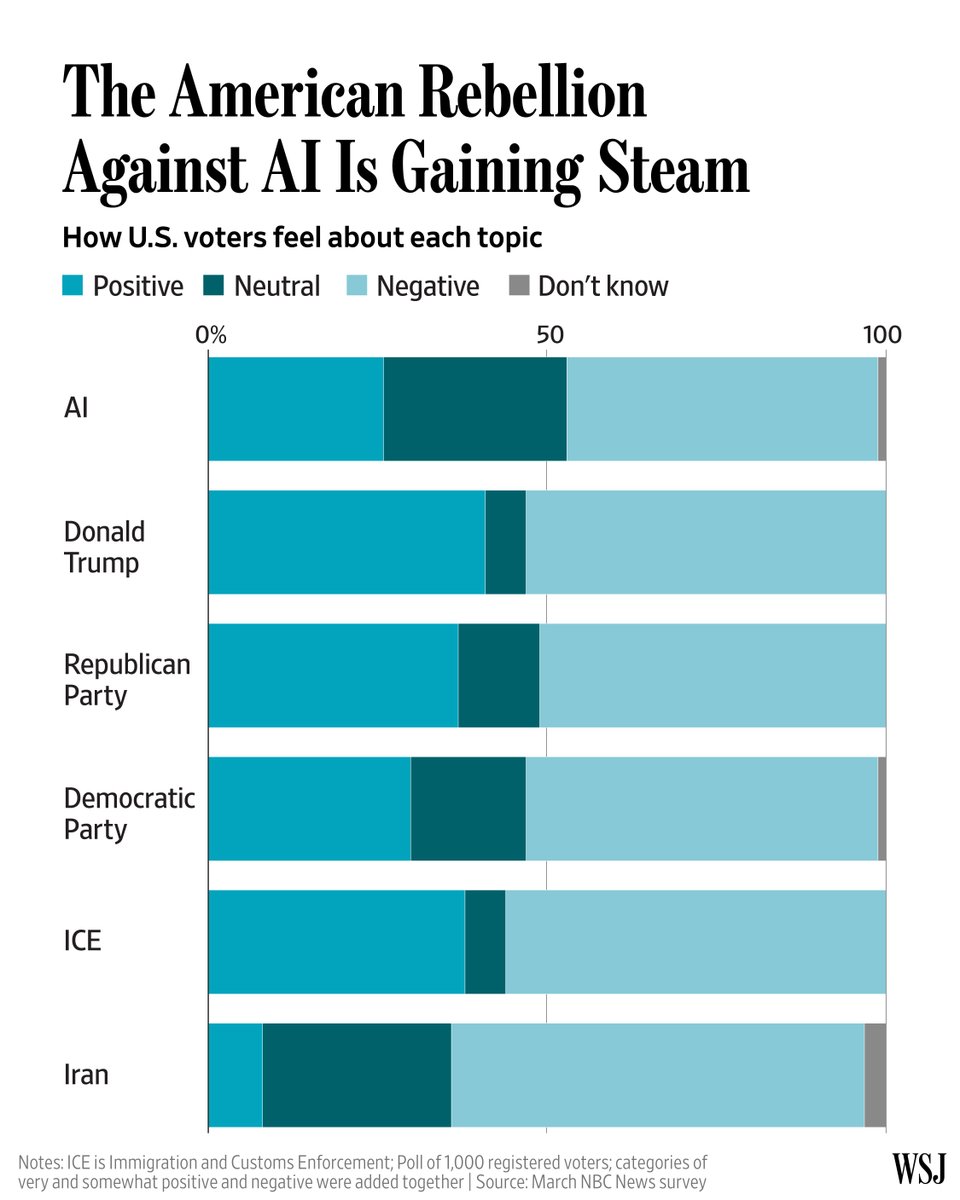
时间线里的应对方式,几乎都是额外验证:对比源视频、使用真实运行时基准测试、采购专门的评估工具,以及更紧密的安全监控。严重程度:高。值得做:是——这是当天数据里最清晰的未被满足基础设施层之一。
本地 AI 已经成真,但仍卡在记忆和配置工作上¶
关于本地 AI 的讨论很热烈,但摩擦也依然很重。@ClementDelangue 分享 了硬数据(41 次点赞、12 条回复、3,439 次浏览、8 次收藏),显示构建者确实在大规模使用 NVIDIA、CPU、Apple Silicon 和 AMD,这说明硬件基础是碎片化的,而不是有一个标准目标。@tmophoto 表示(46 次点赞、9 条回复、5,933 次浏览、26 次收藏),本地吞吐会随着推理引擎和 MTP 设置剧烈波动;而一条推荐 vLLM 的回复,很快撞上了熟悉的反对点:GGUF 不兼容,以及庞大的下载体积。@iam_chonchol 认为(16 次点赞、8 条回复、3,143 次浏览、4 次收藏),真正的瓶颈是记忆,并把 BitCPM-CANN 当成可能的答案。
严重程度:中高。当前可见的绕行方式仍然是手工调参:按个案挑选引擎、测试多个 MTP 设置,以及到处寻找更轻的低比特模型。值得做:是——能感知硬件条件的推理配置,以及更省记忆的本地栈,对操作者来说仍然过于沉重。
3. 人们期望的功能¶
可复审的智能体行为控制平面¶
最清晰的缺失层,是一个能让智能体行为在执行前、执行中和执行后都可检查的系统。@AlexFinn 提出 了 Hermes 的强大之处(646 次点赞、53 条回复、32,868 次浏览、880 次收藏),但回复区立刻把价值重心改写成记忆、复审闸口和清晰边界。@inferencemedia 表示(1 次点赞、1 条回复、90 次浏览),49% 失败的企业 AI 试点都归因于评估缺口;@soyouIJ 总结 了一套最佳配置也只有 62.2% 的基准测试;而 @TechCrunch 报道(8 次点赞、3 条回复、4,060 次浏览、2 次收藏)称,实时 AI 安全窗口已经从数小时坍缩到数秒。这是一个高紧迫性的现实需求。今天已经有基准测试套件、评估地图和安全工具等局部答案,但数据仍显示它们还是分裂栈,而不是一个统一、可复审的控制平面。机会:直接。
诚实的定价与硬件感知的部署指引¶
人们也想要那种在购买或部署之前,就能看懂运行成本和硬件匹配关系的 AI 系统。@GergelyOrosz 描述 了一次视频 AI 积分的诱导式体验(63 次点赞、15 条回复、7,918 次浏览、16 次收藏),而 @sdianahu 解释 说,严肃的 AI 初创公司如今需要显式查询路由,才能让利润率成立(210 次点赞、20 条回复、26,056 次浏览、90 次收藏)。@tmophoto 展示 了本地性能在不同推理引擎之间能有多大波动(46 次点赞、9 条回复、5,933 次浏览、26 次收藏),而 @ClementDelangue 分享 的证据则表明,并不存在一种默认的本地 AI 机器画像(41 次点赞、12 条回复、3,439 次浏览、8 次收藏)。这是一个高紧迫性的现实需求。今天已经有路由手册、硬件仪表盘,以及 BitCPM-CANN 这类低比特方向的局部答案,但时间线仍显示,手工猜测实在太多。机会:直接。
在数据、基础设施和法律上都具备主权的本地语言 AI¶
最强的地域性需求,不是抽象意义上的“本地模型”,而是一整套能反映本地语言和治理要求的完整栈。@OmarKamali 写道(18 次点赞、3 条回复、1,135 次浏览、2 次收藏),如果 AI 真要重塑摩洛哥的工作,它就必须理解摩洛哥,并建立在本地数据、语音、NLP、嵌入、评估、基础设施和法律对齐之上。@DivaJain2 认为(79 次点赞、3 条回复、2,060 次浏览、20 次收藏),中国已经从“强模型”进一步推进到了 AI 原生消费用例,而截图和回复则把 Doubao 当成了可访问 AI 产品包装的一个证明点。这项需求同时具备现实性和战略性。今天已经有本地生态努力和主权 AI 叙事等局部答案,但在代表性不足的语言里,配套栈依然不完整。机会:具竞争性。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Hermes Agent | 智能体平台 | (+/-) | 灵活的多步工作流;记忆和文档召回用例很能引起共鸣 | 信任仍取决于边界、复审闸口和可见控制 |
| Query routing + speculative decoding | 推理编排 | (+) | 能把 60-80% 的流量转到便宜得多的模型上;有助于守住利润率 | 需要自定义路由逻辑,并对查询难度有足够强的理解 |
| llama.cpp | 本地推理引擎 | (+) | 在一项双 3090 测试里,35B 模型跑到 99.45 tok/s;很适合 GGUF 式本地工作流 | 对调参高度敏感;MTP 设置会实质改变结果 |
| LM Studio | 本地推理应用 | (+/-) | 易于搭建本地工作流和做并排基准测试 | 在被引用测试里,吞吐量大约只有 llama.cpp 的一半 |
| vLLM | 推理引擎 | (+/-) | 回复证据表明,同一硬件上可能获得高得多的吞吐 | GGUF 摩擦和大型模型下载,仍让一些用户望而却步 |
| Hugging Face Hardware | 硬件可观测性 | (+) | 展示了 300,000 份构建者资料中的真实社区硬件构成 | 自报式拥有数据并不保证工作负载匹配 |
| BitCPM-CANN | 低比特建模 | (+) | 声称相对 BF16 可节省 6x 记忆,并为更轻的本地 / 边缘模型提供路径 | 仍很早期,且主要来自讨论串;绑定 Ascend/CANN 特定工具链 |
| WildClawBench | 智能体评估基准测试 | (+) | 真实 Docker 任务、混合打分、对运行框架敏感,使它比合成榜单更真实 | 最佳配置也只有 62.2%,说明问题仍未解决 |
| Glasswing / Claude Mythos Preview | AI 安全扫描 | (+) | 声称能高吞吐发现漏洞,且确认率很高 | 证据多停留在推文层面和早期访问阶段,公开技术细节有限 |
| Runflow + Sentinel | AI 图像工作流 / 评估 | (+) | 为输出打分、捕捉坏输入,并能在多模型上自动重生成失败结果 | 主要适用于图像流水线,也仍暴露在上游模型经济学之下 |
| FluxVLA Engine | 机器人 / VLA 平台 | (+) | 用一套配置打通从数据到训练、评估、推理和部署 | 需要机器人专用基础设施和偏 CUDA 的重型配置 |
| X2SAM | 多模态分割模型 | (+) | 在统一界面里融合图像与视频分割,以及文本和视觉提示 | 仍是研究阶段系统,而不是已验证的生产工具 |
看完这张表,整体模式已经很清楚:人们不再把“AI 工具”当成单一类别来谈,而是在谈具体层次——智能体外壳、路由器、推理引擎、评估基准、漏洞扫描器,以及面向工作流的平台。满意度曲线也明显分裂:当一个工具能够收窄问题并暴露运营细节时,人们最容易给出正面评价;而当定价、评估或硬件匹配仍然不透明时,负面情绪就会升高。
迁移路径同样很清楚。成本控制玩法,是在理解工作负载之后,把流量从前沿模型逐步路由到更小的模型;本地推理玩法,则是直接比较不同引擎,而不是假定存在一套默认栈——tmophoto 的讨论串及其回复,几乎就是在把 llama.cpp、LM Studio 和 vLLM 当作速度、模型格式支持和部署负担之间的取舍来讲。评估这一侧,迁移方向也已经从整洁沙箱转向原生运行时基准、工具选型评分卡,以及盯住在线系统的安全层。
@sijlalhussain 认为(10 次点赞、1 条回复、126 次浏览、2 次收藏),生成式 AI 应放在更大企业 AI 系统中的一层来看,并引用了 Gartner。

这张图之所以重要,是因为它概括了当天更广的技术结论:GenAI 并没有取代其余栈,而是在被放进更大的运营系统里。
培训内容也开始围绕这种分层视角走向标准化。Anthropic 的课程目录、LLM Zoomcamp 的教学大纲,以及 Harvard 课程,都在围绕 RAG、智能体、编排、评估、监控、MCP 和 Claude Code 这些具体工作流来组织 AI 实践,而不是继续给出模糊的“提示词技巧”。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| FluxVLA Engine | FluxVLA / limxdynamics | 用于训练、评估和部署 VLA 系统的全栈工程平台 | 取代分散在多套脚本和工具里的碎片化具身 AI 工作流 | Python, PyTorch, OpenVLA, LlavaVLA, GR00T, Pi0/Pi0.5, LIBERO, ZMQ remote inference | Beta | GitHub · 推文 |
| Runflow | Runflow team | 带评分和重生成的 AI 图像工作流与评估 API | 帮助团队让图像生成功能在生产环境里保持可靠且有利润 | 736 models, Sentinel scoring, auto-regeneration, custom open-model workflows including Qwen Edit and Flux | 已发布 | 网站 · 推文 |
| OncoSphere AI | @ADesaiMD | 综合指南、试验、影像和病理来做判断的智能体式肿瘤学工作流 | 减少肿瘤委员会式决策支持中的手工准备和流程协调 | Agentic AI, clinical guidelines, trial data, imaging, pathology | Alpha | 推文 |
| NaijaTax IQ | @richardokunolar and MC7.0 mentees | 带可运行 UI 的会计与税务助手 | 把狭窄的金融工作流打包成比通用聊天更具体的智能体界面 | Agentic AI workflow, tax/accounting interface | Alpha | 推文 |
| AllenAI pegboard VLA 数据集 | AllenAI / LeRobot | 面向 OpenVLA 和 MolmoAct 的公开 pegboard 评估数据集 | 给具身 AI 团队提供可复现的多模态基准测试数据 | Hugging Face datasets, LeRobot, 3 cameras, 14-D control/state data | 已发布 | OpenVLA 数据集 · MolmoAct 数据集 · 推文 |
| X2SAM | Sun Yat-sen University / Peng Cheng Laboratory / Meituan | 用对话式和视觉提示统一处理图像与视频的分割模型 | 避免在纯图像和纯视频工作流之间分别维护不同的分割系统 | MLLM, Mask Memory, V-VGD benchmark | Alpha | 论文 · 项目 · 推文 |
最重要的模式是,这些项目在交付的是整条闭环,而不是孤立模型。@DanKornas 分享 的 FluxVLA(10 次点赞、2 条回复、1,053 次浏览、6 次收藏)就是一套“一份配置跑通机器人系统”的栈,而仓库也用部署文档、远程推理支持和基准测试表去支撑这一点,而不只是给出概念陈述。

Runflow 在另一个市场里展现了同样的打包倾向。Runflow 网站 写得很清楚:它不是一个单纯的生成 API,而是把评分、安全护栏、重试逻辑和基础设施一起打包起来,好让图像功能扛得住生产流量和利润压力。
@ADesaiMD 展示 的 OncoSphere AI(2 次点赞、1 条回复、48 次浏览、1 次收藏),被描述成一个肿瘤委员会工作流智能体,而不是临床聊天机器人;最强的证据也来自那张幻灯片,因为它把工作流本身以及所宣称的 84% 时间缩减都展示了出来。

@richardokunolar 展示 了一个可运行的 NaijaTax IQ 界面(3 次点赞、1 条回复、108 次浏览),这是在一次智能体式 AI 导师制结业项目中做出来的。它之所以重要,是因为它显然与会计和税务运营绑定在一起,而不是泛泛宣称自己是一个通用助手。

另一个反复出现的构建模式,是“评估优先”的基础设施。AllenAI 成对发布的 pegboard 数据集,以及 X2SAM 那次高度基准测试导向的发布,都说明团队正在把数据、方法和工件一起交付;与此同时,FluxVLA 和 Runflow 也把评估直接打包进产品本体。这些构建背后的触发痛点,与报告其他地方看到的是同一个:通用 AI 界面只有在被收窄成一个带明确检查点的工作流后,才会获得信任。
6. 新动态与亮点¶
WildClawBench 让“真实智能体评估”变得具体起来¶
@soyouIJ 总结 了 WildClawBench(9 次点赞、3 条回复、92 次浏览),而这篇论文之所以值得注意,是因为它用 60 个由人类编写、双语、多模态的 Docker 任务,替代了那些抽象的合成评估讨论;这些任务平均需要约 8 分钟和 20+ 次工具调用。最佳配置也只有 62.2%,而仅仅更换运行框架,就能让表现波动多达 18 分。这使它成为本数据集中最清晰的公共工件之一,说明前沿智能体评估在多大程度上仍取决于运行时外壳,而不只是基础模型。
Anthropic 把 Claude 学习栈正式化了¶
@HowToAI_ 重点介绍 了 Anthropic 的课程目录(5 次点赞、1 条回复、179 次浏览、9 次收藏),而 URL 检查确认,其中已经有 Claude、Claude Code、MCP、subagents、API 工作,以及云部署的官方路线。这件事之所以重要,是因为它把不久前还零散存在的部落知识,变成了厂商支持的课程体系。虽然这条推文本身互动不高,但它对 Claude 生态将走向何处,给出了一个有分量的信号。
Google 继续把主动式智能体推向大众化产品包装¶
@ABC 报道 了 Google 的下一波 AI 发布(14 次点赞、16 条回复、18,842 次浏览、4 次收藏),而真正让它显得重要的,是检查过后的 AP 文章:Gemini Spark 被包装成一种会在云端持续工作的后台智能体,Gemini Omni 则推动可编辑视频生成,而 SynthID 继续把内容凭证往前推。这件事与其说是一项模型升级,不如说是在为主动式 AI 系统做面向消费者的大众包装。
研究发布持续拓宽可用的多模态栈¶
@jiqizhixin 分享 了 X2SAM(9 次点赞、1 条回复、897 次浏览、4 次收藏);其 论文 与 项目页 把它描述成一个统一的图像 / 视频分割模型,支持对话式与视觉提示、Mask Memory 模块,以及新的 V-VGD 基准测试。@SciFi 则发布 了 《LLM-Metrics》论文(2 次点赞、1 条回复、117 次浏览、1 次收藏),它研究的是:LLM 对论文的记忆是否能映射论文影响力。把这两者放在一起看,当天的研究信号已经明显不止于文本聊天,而是在向分割、基准测试,乃至测量本身外扩。
7. 机会在哪里¶
[+++] 可复审的智能体运营 — 多个板块都在同时指向这里。@AlexFinn 抛出了 信任问题(646 次点赞、53 条回复、32,868 次浏览、880 次收藏),@inferencemedia 点出了 评估缺口(1 次点赞、1 条回复、90 次浏览),WildClawBench 展示了真实运行时下偏低的成功上限,而 @TechCrunch 报道 了实时 AI 安全窗口的压缩(8 次点赞、3 条回复、4,060 次浏览、2 次收藏)。同一种需求同时出现在智能体 UX、基准测试、安全和企业部署里,因此这个机会很强。
[++] 本地 AI 部署与优化工具 — Hugging Face 硬件页面、@tmophoto 的 基准测试讨论串(46 次点赞、9 条回复、5,933 次浏览、26 次收藏)、BitCPM-CANN 的记忆节省说法,以及 @sdianahu 的 路由手册(210 次点赞、20 条回复、26,056 次浏览、90 次收藏),都指向同一个缺口。构建者需要有人帮助他们把工作负载匹配到合适的硬件、引擎和模型大小,而不是所有事情都靠手工调参。
[++] 工作流原生的垂直智能体 — @ADesaiMD 展示 了一个肿瘤学工作流智能体(2 次点赞、1 条回复、48 次浏览、1 次收藏),@richardokunolar 展示 了一个税务 / 会计 UI(3 次点赞、1 条回复、108 次浏览),Runflow 把生产级图像评估打包进了产品,而 FluxVLA 则把具身 AI 部署打包起来。这个信号属于中等强度:胜出的模式不是通用聊天,而是内建评估和工作流逻辑的狭窄系统。
[+] 本地语言的主权 AI 栈 — @OmarKamali 明确写出 了摩洛哥缺失的那些层(18 次点赞、3 条回复、1,135 次浏览、2 次收藏),而 @DivaJain2 则指向 中国的 AI 原生消费级产品包装(79 次点赞、3 条回复、2,060 次浏览、20 次收藏)。这个信号还在涌现期,而不是主导主题,但在本数据集中,它是少数把语言、基础设施、法律和产品分发当成同一栈来讨论的地方。
8. 要点总结¶
- 人们对智能体仍然有热情,但前提是工作流必须受到约束。 @AlexFinn 展示(646 次点赞、53 条回复、32,868 次浏览、880 次收藏)了最高互动的智能体讨论串如何迅速转向记忆持久性、干净上下文和复审闸口,而 @sdianahu 整理 了在找到 PMF 之后该如何做路由和蒸馏(210 次点赞、20 条回复、26,056 次浏览、90 次收藏)。
- 验证仍然是最难补齐的基础设施缺口。 @georgeviews 标记 出一段疑似经 AI 编辑的错误信息视频(500 次点赞、8 条回复、15,147 次浏览、31 次收藏),WildClawBench 展示了真实运行时下偏低的成功上限,而 @TechCrunch 报道 了实时安全失效(8 次点赞、3 条回复、4,060 次浏览、2 次收藏);这些都指向同一个“如何证明”的问题。
- 本地 AI 已不再小众,但对操作者来说仍然太重。 Hugging Face 硬件页面 展示了多种硬件类型上的广泛采用,而 @tmophoto 测到 了不同引擎之间巨大的吞吐差异(46 次点赞、9 条回复、5,933 次浏览、26 次收藏);与此同时,@iam_chonchol 认为(16 次点赞、8 条回复、3,143 次浏览、4 次收藏),记忆依然是核心瓶颈。
- 最强的构建模式,是工作流打包,而不是再做一个聊天机器人。 @DanKornas 分享 了 FluxVLA(10 次点赞、2 条回复、1,053 次浏览、6 次收藏),@ADesaiMD 展示 了 OncoSphere AI(2 次点赞、1 条回复、48 次浏览、1 次收藏),而 Runflow 则把评估和部署一起围绕具体工作打包。
- AI 入门正在一边走向官方化与制度化,一边扩展消费者产品包装。 @HowToAI_ 重点介绍 了 Anthropic 的课程目录(5 次点赞、1 条回复、179 次浏览、9 次收藏),LLM Zoomcamp 提供了一套免费的构建者大纲,而 @ABC 报道 了 Google 对 Gemini Spark / Omni 的推出(14 次点赞、16 条回复、18,842 次浏览、4 次收藏)。