Twitter AI - 2026-05-26¶
1. What People Are Talking About¶
1.1 Evaluation stopped being a scoreboard and became a control layer 🡕¶
Evaluation was the loudest cluster on May 26, but the center of gravity changed. Instead of asking which frontier model won a generic leaderboard, people argued about who defines the benchmark, what kind of work it covers, and whether it can safely route real production traffic. At least six retained items supported this theme.
@JayminSOfficial argued (416 likes, 590 retweets, 30 replies, 44,477 views) that benchmark leaderboards had quietly become the default operating system for model choice, while the quoted Merge Gateway launch from @shensi said teams should define their own weights, benchmarks, and evals instead of chasing the current winner. Merge's Build Your Own Router post makes that concrete: organizations can combine standard benchmarks, industry leaderboards, and custom scores, then inspect why a given model won a routing decision.
@ValsAI opened (195 likes, 12 replies, 18,199 views, 356 bookmarks) a 3-6 month fellowship for new benchmarks and eval techniques, with replies immediately pointing to unresolved gaps like voice AI and AI-driven investment metrics. The notable shift was not just another benchmark post; it was evaluation treated as a funded research category in its own right.
@cyb3rops shared (70 likes, 4 replies, 4,923 views, 47 bookmarks) a THOR finding-triage benchmark because generic LLM leaderboards did not help RuneAI decide whether a messy endpoint finding should be suppressed, reviewed, or escalated. The public benchmark site and repo say the current release covers 45 models, 10 THOR reports, and 189 expert-classified findings, with metrics for Operational Triage Score, critical misses, and false review load.
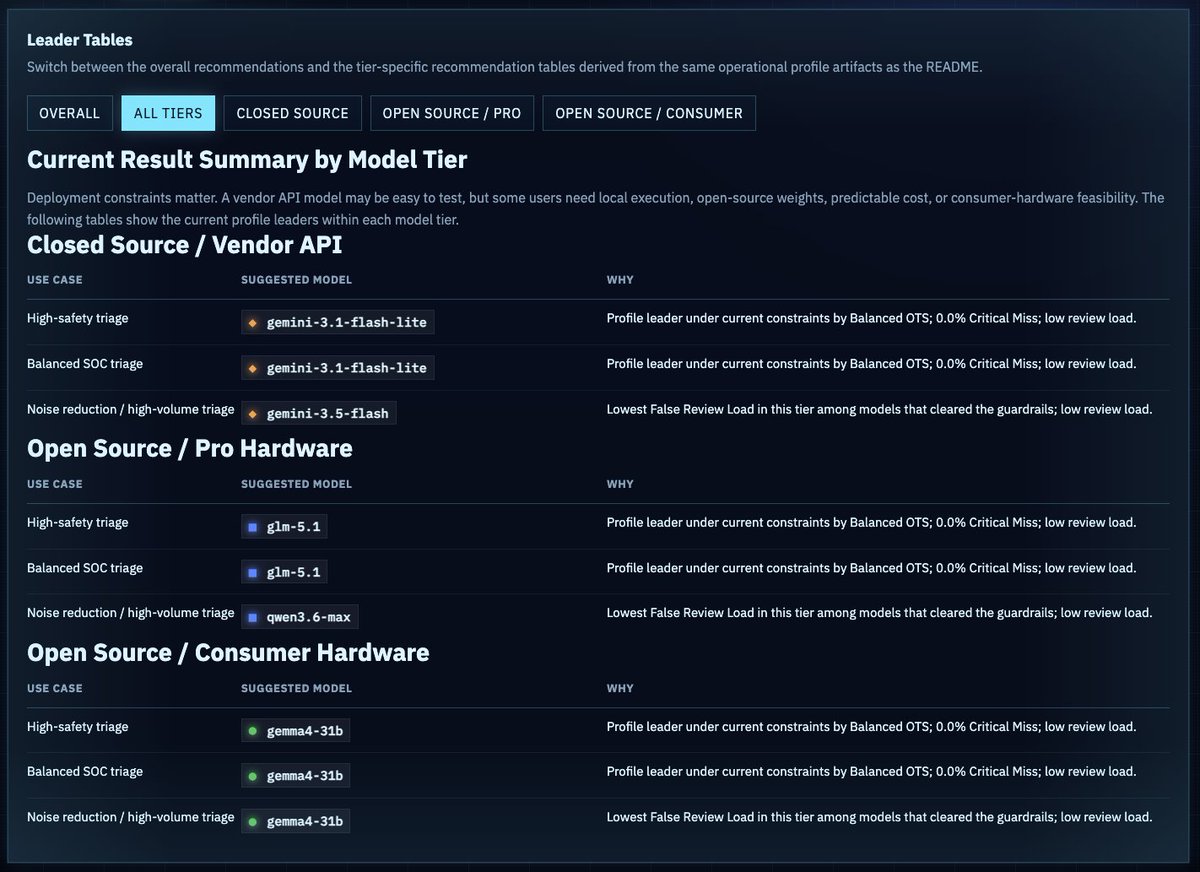
The screenshot matters because it shows evaluation output as a deployment decision table rather than one universal winner.
@DeepLearningAI noted (11 likes, 9 replies, 848 views) research from Carnegie Mellon and Stanford showing that 43 agent benchmarks and 72,342 tasks still over-weight software work relative to the broader U.S. labor market. The linked paper turns the day's benchmark skepticism into a measurable coverage problem rather than a vibe.
Discussion insight: Replies across the Merge, Vals, and local-model threads converged on the same skepticism: scores are useful only when attached to a workflow, not when treated as a universal intelligence badge.
Comparison to prior day: May 25 already pushed evaluation into realistic environments and built-in product tooling. May 26 went one step further by attacking the benchmark itself: who defines it, which work it covers, and how it actually routes production traffic.
1.2 Reliability work focused on verifiable reasoning and memory 🡕¶
A second cluster treated reliability as a structural design problem rather than a prompting problem. The common pattern was to move more work into a checkable intermediate state: fast-weight consolidation, compiler-verified proofs, or deterministic evidence compilation. Three retained items anchored this theme.
@iScienceLuvr shared (697 likes, 23 replies, 43,042 views, 568 bookmarks) the new paper "Language Models Need Sleep," and the linked arXiv abstract says the model periodically converts recent context into persistent fast weights, clears its KV cache, and uses offline recurrent passes during "sleep" to improve harder reasoning tasks. The attached first page mattered because it exposed the exact mechanism - fast weights in state-space-model blocks plus offline recurrence - rather than leaving the claim at a metaphor.

@HowToAI_ claimed (46 likes, 6 replies, 2,358 views, 38 bookmarks) that AlphaProof Nexus solved long-open math problems by pairing an LLM with the Lean proof compiler. The corresponding paper confirms the core result: the strongest agent resolved 9 of 353 open Erdos problems and proved 44 of 492 OEIS conjectures, while a simpler generation-plus-verification loop reproduced the Erdos successes but became costlier on the hardest cases.

@yoheinakajima reported (32 likes, 9 replies, 5,685 views, 30 bookmarks) that ActiveGraph held up on LongMemEval-S without graph-extracted facts or semantic-memory writing. The linked technical note says the system reached 85.6% QA accuracy and 86.2% answer-in-context at a 2,462-token budget, statistically tied with dense turn-level RAG while showing a measured retrieval-side edge.
Discussion insight: The most technical replies did not ask for better prompts. They compared the sleep paper to replay buffers, asked whether ActiveGraph relied on entity extraction, and got the answer "no extraction here" - evidence that practitioners were watching for deterministic mechanisms and hard feedback loops.
Comparison to prior day: May 25 emphasized realistic evaluation environments. May 26 added internal reliability mechanisms inside the model or harness: fast weights, proof checkers, and event-sourced evidence compilation.
1.3 Governance stayed concrete when tied to compliance and consent 🡒¶
The governance conversation stayed elevated, but the strongest posts were not abstract ethics threads. They were about who gets to supervise frontier AI, what happens when synthetic output violates consent, and whether enterprise compliance automation is finally crossing from demoable to trustworthy. Three retained items supported this theme.
@Reuters reported (19 likes, 8 replies, 11,400 views) that Anthropic co-founder Chris Olah said AI development cannot be left solely to tech companies and called for oversight from religious leaders, governments, and civil society. Even without access to the paywalled Reuters article, the tweet itself was explicit about the oversight ask and gave the encyclical discussion broader mainstream reach.
@Anime reported (30 likes, 1,723 views) that voice actor Kenjiro Tsuda sued TikTok over alleged unauthorized generative-AI use of his voice. The linked Anime News Network story grounded the claim in a live rights dispute rather than a hypothetical future risk.
@a16z argued (38 likes, 6 replies, 9,174 views, 23 bookmarks) that compliance may finally move from "good enough to pilot" to "good enough to trust," and the linked essay says frontier models now score 80-100% across LegalBench's 162 legal reasoning tasks. Its chart is important because it shows that the accuracy jump happened recently, which helps explain why compliance is returning as a startup category now rather than two years ago.

Discussion insight: The most substantive pushback came in the compliance thread, where a reply argued that "a 90% correct product is still 100% wrong" and promoted pre-settlement verification. That kept the day's governance discussion anchored in process and recourse, not just adoption optimism.
Comparison to prior day: May 25 mixed encyclical excerpts, academic-integrity data, and a synthetic-voice lawsuit. May 26 kept the same governance frame but moved it closer to enterprise software and active rights enforcement.
1.4 Builder energy stayed concentrated on workflow infrastructure 🡕¶
Builder activity remained strong, but the pattern was narrower than generic AI assistants. The highest-signal projects wrapped the missing substrate around a specific workflow: healthcare post-training, verifiable execution, or scientific evidence retrieval. Four retained items fit this shape.
@ycombinator shared (108 likes, 10 replies, 476,173 views, 85 bookmarks) BioStack, which it described as simulation environments where healthcare AI models train against messy clinical records, delayed outcomes, rewards, and benchmarks. BioStack's site adds that the company sells ML-ready healthcare datasets across EHR, labs, imaging, ECGs, notes, and outcomes, plus RL environments and multi-agent reasoning infrastructure.
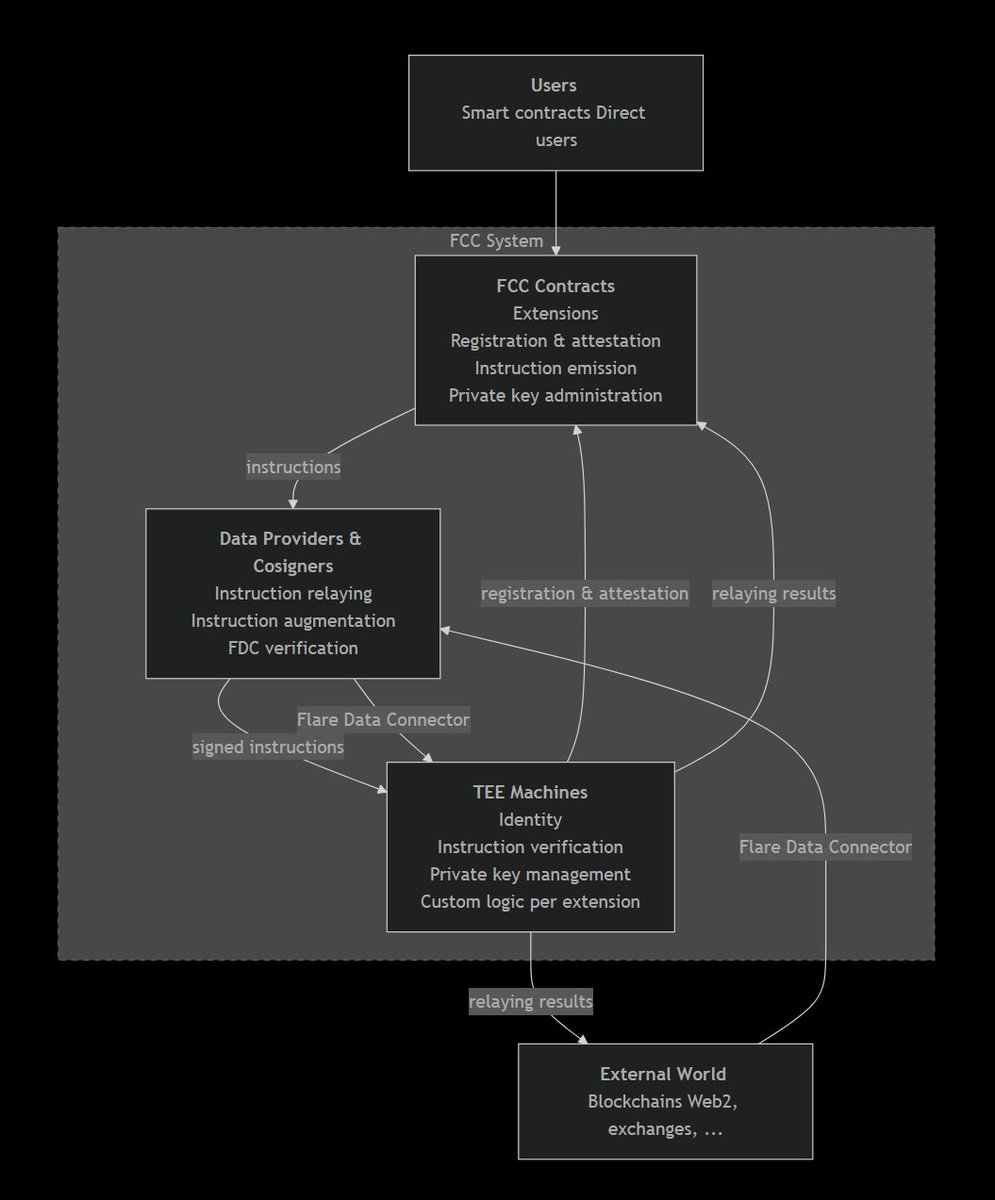
@FlareDevHub outlined (33 likes, 2 replies, 2,965 views) Flare Confidential Compute as a way to prove what model ran, keep sensitive inputs private, hold signing keys inside a TEE, and settle agent-to-agent payments on verifiable outputs. The attached workflow diagram made that proposal materially more concrete by showing confidential-compute components and payment flow instead of a generic agent-finance slogan.
@zxlzr shared (8 likes, 167 views, 4 bookmarks) InnoEval and SciAtlas as a scientific idea-evaluation stack built around deep knowledge search, multi-perspective review, and a 43-million-paper knowledge graph. The linked InnoEval paper, SciAtlas paper, and SciAtlas repo describe a retrieval substrate intended for literature review, idea grounding, trend synthesis, and evidence-grounded evaluation.
@TheAIWorld22 said (9 likes, 318 views, 5 bookmarks) ForgeTrain looked more serious than typical "AI wrote this" announcements because the benchmarks were public and the methodology was open-sourced. The public ForgeTrain repo claims the framework was authored end-to-end by an autonomous agent loop and reports 44.13% MFU on H100.
Discussion insight: Replies in this cluster kept returning to auditability, privacy, and reproducibility. The market signal was that builders can no longer ship only a demo layer; they are expected to explain where the data came from, how the workflow is checked, and whether the system can be reproduced.
Comparison to prior day: May 25 already favored workflow-native systems. May 26 pushed that same instinct deeper into substrate layers: post-training environments, confidential compute, scientific knowledge graphs, and AI-authored infrastructure.
1.5 CPUs re-emerged as a distinct agentic-AI bottleneck 🡕¶
A smaller but clear theme reframed agentic AI as a CPU story as much as a GPU story. The evidence came from NVIDIA's product push, a practitioner thread on tool-use overhead, and a sell-side note tying agentic demand to DRAM tightness. Three retained items supported the theme.
@nvidia said (70 likes, 8 replies, 5,869 views) Vera was purpose-built for agentic AI, and NVIDIA's product page says the chip has 88 Olympus cores, up to 1.2 TB/s of LPDDR5X bandwidth, and rack designs that can run more than 22,500 concurrent environments. NVIDIA's separate delivery post framed the CPU as infrastructure for tool calls, orchestration, long-context retrieval, and reinforcement-learning environments rather than a generic host processor.
@demian_ai argued (22 likes, 3 replies, 1,438 views, 11 bookmarks) that agentic coding harnesses spend a large share of time on CPU work such as tool use, file edits, linting, and shell orchestration, which is why CPU demand is bending faster than old capacity planning expected. @sean___ added (41 likes, 4,160 views, 20 bookmarks) a Mizuho note claiming NVIDIA's CPU revenue could imply roughly 3K PB of incremental CPU demand and that some customers remain 30-50% under-supplied.
Discussion insight: The most useful reply under NVIDIA's launch post did not talk about stock price. It argued that the teams who integrate CPU and GPU end to end will benefit most from lower-latency, agent-oriented infrastructure.
Comparison to prior day: Hardware chatter was already present on May 25, but the emphasis was lighter. On May 26 the CPU itself became the named bottleneck instead of a supporting detail behind GPUs and HBM.
2. What Frustrates People¶
Benchmark wins still do not tell teams what to deploy¶
The recurring complaint was not a lack of benchmarks. It was the wrong benchmarks holding too much power. @JayminSOfficial argued (416 likes, 590 retweets, 30 replies, 44,477 views) that research leaderboards now steer production traffic, while @cyb3rops showed (70 likes, 4 replies, 4,923 views, 47 bookmarks) why that fails in security triage, where the useful question is not who codes best but who best suppresses, reviews, or escalates messy endpoint findings. @DeepLearningAI added (11 likes, 9 replies, 848 views) that the benchmark portfolio itself still over-represents software work relative to the broader labor market. The visible coping behavior was to build custom routing configs, domain-specific benchmark suites, and new evaluation programs rather than trust one headline score. Severity: High. Worth building for: yes — the feed still points to a missing translation layer between benchmark output and production choice.
Strong models still fail on process, auditability, and verification¶
The second frustration was that strong models still break when the workflow demands process discipline instead of impressive text. @metatronics_ wrote (7 likes, 10 replies, 1,676 views) that frontier agents lost money in Alpha Arena because of overtrading, sloppy sizing, and stops set after the fact, not because they could not narrate markets. @ycombinator shared (108 likes, 10 replies, 476,173 views, 85 bookmarks) BioStack, and one reply immediately reframed the buyer test as auditability: can a hospital trace a bad recommendation through the simulated chart, reward rule, and clinical sign-off? In the compliance thread, @a16z made (38 likes, 6 replies, 9,174 views, 23 bookmarks) the strongest pro-automation case of the day, but the most substantive reply pushed back that a 90% correct compliance product is still effectively wrong when it settles a high-risk decision. The workaround pattern was to add deterministic retrieval, formal verifiers, or explicit process controls around the model. Severity: High. Worth building for: yes — the process layer remains visibly underbuilt.
Rights, consent, and appeal layers remain thin¶
The governance posts were most concrete when they touched identity and recourse. @Reuters reported (19 likes, 8 replies, 11,400 views) Chris Olah's call for oversight beyond tech firms, which is itself evidence that current institutional checks are not trusted to emerge from the market alone. @Anime reported (30 likes, 1,723 views) Kenjiro Tsuda's lawsuit against TikTok over alleged unauthorized AI voice use, showing that the consent problem is already litigable rather than theoretical. @a16z and its replies also exposed how brittle recourse remains in compliance workflows: enterprises may trust models more, but they still want verification before a wrong decision becomes a regulatory or customer-facing failure. Severity: High. Worth building for: yes — provenance, consent, and appeal tooling still look thinner than the risk they are meant to manage.
Agentic workloads are exposing CPU and memory bottlenecks¶
A separate frustration was infrastructural: agentic AI keeps getting described as a model problem while the feed increasingly treated it as a systems problem. @nvidia positioned (70 likes, 8 replies, 5,869 views) Vera as a CPU for agentic AI, @demian_ai argued (22 likes, 3 replies, 1,438 views, 11 bookmarks) that tool use, file edits, linting, and orchestration make agentic coding harnesses CPU-heavy, and @sean___ posted (41 likes, 4,160 views, 20 bookmarks) a Mizuho note pointing to undersupply and sharp pricing pressure. The workaround visible in the feed was not to abandon accelerators, but to think in end-to-end CPU-plus-GPU terms and treat orchestration hardware as a first-class design variable. Severity: Medium-High. Worth building for: yes — but this is a capital-intensive opportunity and the incumbents are already moving.
3. What People Wish Existed¶
Workflow-specific routing and evaluation control planes¶
The strongest implied need was a layer that translates abstract model scores into product-specific decisions. @JayminSOfficial argued (416 likes, 590 retweets, 30 replies, 44,477 views) that benchmarks built for papers were already deciding production traffic, while the linked Merge Gateway launch responded by letting teams weight their own benchmarks and upload custom scores. @ValsAI opened (195 likes, 12 replies, 18,199 views, 356 bookmarks) a fellowship for new eval techniques, and @DeepLearningAI highlighted (11 likes, 9 replies, 848 views) research showing current agent benchmarks still miss much of real labor. This is a practical need with high urgency. Partial answers exist in Merge Gateway, THOR, and fellowship-backed eval work, but the stack still looks fragmented rather than settled. Opportunity: direct.
Verifiable process layers that prove what the agent actually did¶
A second unmet need is not a smarter answer generator but a system that can prove the work happened correctly. @HowToAI_ pointed (46 likes, 6 replies, 2,358 views, 38 bookmarks) to AlphaProof Nexus as a Lean-backed proof loop, @yoheinakajima reported (32 likes, 9 replies, 5,685 views, 30 bookmarks) deterministic evidence compilation before semantic memory, and @FlareDevHub outlined (33 likes, 2 replies, 2,965 views) verifiable inference and secure key custody for agents. @metatronics_ showed (7 likes, 10 replies, 1,676 views) why this matters: process failures, not language skill, ruined the live trading results. This is a practical need with high urgency. Partial answers exist, but most are still isolated techniques rather than one dependable control layer. Opportunity: direct.
Consent, provenance, and appeal systems for synthetic identity and automated decisions¶
The feed also pointed to a missing rights-management layer around AI outputs that affect real people. @Reuters reported (19 likes, 8 replies, 11,400 views) an explicit call for outside oversight, @Anime reported (30 likes, 1,723 views) a lawsuit over alleged AI voice misuse, and @a16z argued (38 likes, 6 replies, 9,174 views, 23 bookmarks) that compliance work is becoming AI-addressable only now that accuracy is higher. Together, those items imply a need for consent records, provenance, and recourse when AI systems imitate someone or make a regulated decision. This is both a practical and institutional need with high urgency. Partial answers today are still mostly lawsuits, encyclicals, and verification add-ons rather than productized safeguards. Opportunity: direct.
Domain-grounded data and knowledge substrates¶
Another clear need is for data and knowledge layers that look like the real task instead of a generic benchmark prompt. @ycombinator shared (108 likes, 10 replies, 476,173 views, 85 bookmarks) BioStack because healthcare post-training needs messy records, delayed outcomes, and reward loops in one system. @zxlzr shared (8 likes, 167 views, 4 bookmarks) SciAtlas and InnoEval to ground scientific idea evaluation in a 43-million-paper graph, and @cyb3rops built (70 likes, 4 replies, 4,923 views, 47 bookmarks) a public triage benchmark around real THOR reports. This is a practical need with medium-high urgency, and it is already attracting credible builders. Opportunity: competitive.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| Merge Gateway | LLM routing/control plane | (+) | Lets teams weight benchmarks, upload custom scores, audit routing decisions, and combine routing with DLP and prompt-injection controls | Still depends on customer-defined evals and whatever benchmark coverage the team can assemble |
| Vals AI / Vals Fellowship | Evaluation platform / research program | (+) | Funds hard eval problems and gives researchers API credits, GPUs, human data, and evaluation infrastructure | The replies themselves surfaced unresolved areas such as voice AI and long-horizon investment metrics |
| THOR Finding Triage Benchmark | Security benchmark | (+/-) | Domain-specific triage metrics, 45 models, 10 reports, 189 expert-labeled findings, and deployment-tier guidance | It is still a clean baseline before the full tool-augmented workflow the author expects in production |
| ActiveGraph | Memory/runtime | (+/-) | Deterministic ingestion, compact evidence compilation, and strong LongMemEval-S retrieval at low context budgets | Statistically tied rather than clearly better than dense turn-level RAG, and semantic memory is not added yet |
| AlphaProof Nexus + Lean | Formal proof stack | (+) | Compiler-backed verification, open-problem results, and a clear mechanism for rejecting flawed reasoning steps | Harder problems remain costlier and the method depends on formalizable domains |
| BioStack | Healthcare data / RL environment | (+) | ML-ready clinical data, delayed-outcome loops, reward functions, and post-training environments for healthcare AI | Auditability and privacy questions appear immediately when people imagine production deployment |
| LegalBench-led compliance AI | Legal/compliance benchmark layer | (+/-) | Frontier-model gains make document-heavy compliance automation more plausible and commercially urgent | The thread's own pushback stressed that even high accuracy still needs verification before settlement |
| SciAtlas | Scientific knowledge graph / agent skills | (+) | 43M papers, 157M entities, 3B triplets, and structured retrieval for literature review, idea grounding, and trend synthesis | The paper is still labeled ongoing work and the ecosystem is early |
| ForgeTrain | Training infrastructure | (+/-) | Public repo, AI-authored codebase, and a 44.13% MFU claim with open-source framing | The harness is still coming soon, so the full autonomous-build story is only partially released |
| Flare Confidential Compute | Verifiable compute / TEE stack | (+/-) | Verifiable inference, private inputs, secure key custody, and agent-payment logic in one concept | Public documentation is still thin, so the strongest evidence today is the architecture sketch and tweet thread |
| NVIDIA Vera CPU | CPU / agentic hardware | (+) | 88 Olympus cores, up to 1.2 TB/s bandwidth, and explicit optimization for RL environments, orchestration, and tool-heavy agent workloads | The first systems are only now entering customer evaluation, so the real adoption curve is still forming |
Overall, sentiment was strongest for tools that constrain or ground model behavior rather than simply promise a smarter model. People liked routing layers that expose the policy, benchmarks that match the task, proof systems that can reject bad steps, and data and knowledge substrates that look like real work.
The visible workarounds were to switch from one generic leaderboard to weighted benchmark configs, from full-history prompting to deterministic evidence compilation, from manual compliance to AI plus verification, and from GPU-only thinking to CPU-aware system design. Competitive pressure was clearest in routing, evaluation, and compliance, where multiple builders are converging on similar control-layer problems even when their verticals differ.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| Merge Gateway | @shensi / @merge_api | Routes LLM requests using weighted benchmark and policy configs | Teams were re-testing and re-integrating every time a new model topped a generic leaderboard | Benchmark library, custom scores, routing configs, policy routing, DLP, prompt-injection controls | Shipped | tweet · blog |
| BioStack | @sanatmishra7 / @patwa_parth | Builds simulation environments and data pipelines for healthcare AI post-training | Healthcare models need messy records, delayed outcomes, and reward loops instead of benchmark-only demos | RL environments, healthcare datasets, annotation, reward functions, multi-agent reasoning infrastructure | Shipped | tweet · site |
| THOR Finding Triage Benchmark | @cyb3rops | Evaluates models on security-event and forensic finding triage | Generic reasoning or coding leaderboards do not tell teams how a model will behave in SOC triage | THOR reports, Operational Triage Score, critical-miss rate, false-review load, public repo/site | Shipped | tweet · site · repo |
| ActiveGraph | @yoheinakajima | Event-sourced graph runtime for agent memory and evidence compilation | Long-horizon memory systems need reproducible evidence assembly without paying a large retrieval tax | Event log, deterministic graph projection, embeddings, LLM reader, benchmark harness | Alpha | tweet · blog · repo |
| SciAtlas | @zxlzr | Knowledge-graph substrate and client tooling for scientific research agents | Literature search and idea evaluation break when evidence stays fragmented and unstructured | 43M-paper KG, graph reranking, CLI/API, agent skills | Alpha | tweet · paper · repo |
| ForgeTrain | @OpenBMB | AI-authored pretraining framework for LLM training | Infrastructure code generation claims usually lack open methodology and measurable output | Autonomous agent loop, PyTorch/CUDA stack, H100 training framework, MFU benchmarking | Beta | tweet · repo |
| Flare Confidential Compute | @FlareDevHub | Proposes attested model execution, private inputs, secure key custody, and agent payments | Agents cannot easily prove what model ran or safely hold secrets/payments today | TEE-style enclaves, attestation, onchain proofs, key custody, agent-payment flow | RFC | tweet |
| AgentScoreboard | @Paymindai | Adds ranking, badges, and exportable scorecards for banking agents | Agent benchmarking and certification are still hard to compare or operationalize inside products | Elo ranking, time decay, domain scores, badge system, Markdown/JSON export | Alpha | tweet |
Merge Gateway and THOR were the clearest examples of the day's shared builder trigger: generic leaderboards were no longer enough. Merge answered by making routing policy configurable; THOR answered by publishing a security-specific baseline with deployment tiers, critical-miss metrics, and public artifacts.
BioStack and SciAtlas attacked the same structural gap from the data side. BioStack wraps real clinical evidence, delayed outcomes, and reward loops into one healthcare post-training stack, while SciAtlas packages 43 million papers and 157 million entities into a graph that research agents can query for grounded evaluation and literature work.
ForgeTrain, Flare Confidential Compute, and AgentScoreboard show a second pattern: the control layer itself is becoming a product. ForgeTrain turns reproducibility and performance claims into a public repo, Flare tries to make execution and payment flows attestable, and AgentScoreboard turns comparison and certification into a visible feature rather than an internal spreadsheet.
6. New and Notable¶
LLMorphism gave anti-anthropomorphism critique a sharper name¶
@ValerioCapraro argued (70 likes, 19 replies, 11,644 views, 53 bookmarks) that people are increasingly treating human cognition as if it works like a large language model, and he labeled that mistake "LLMorphism." The attached infographic and linked paper make the term notable because they push the conversation past generic anthropomorphism warnings and into specific mechanisms, consequences, and mitigations.

Consumer-hardware coding models kept narrowing the frontier gap¶
@bridgemindai posted (146 likes, 21 replies, 7,284 views) that local Gemma and Qwen variants were now topping GPT-5 on one coding chart, while still trailing GPT-5.5 and Claude Opus 4.7. The image is notable because it makes the spread visible rather than rhetorical, but the top reply immediately pushed back that benchmark scores were not matching real quality - a compact summary of the day's broader benchmark tension.

Agent ranking started to look like a product primitive¶
@Paymindai announced (17 likes, 1 reply, 528 views) an AgentScoreboard update with Elo-style ranking, time decay, domain scores, badges, and Markdown/JSON export for banking agents. This was an early signal, but it was notable because it turned agent comparison and certification into an in-product feature rather than an internal benchmark spreadsheet.
AI-authored training infrastructure became a more concrete public artifact¶
@TheAIWorld22 said (9 likes, 318 views, 5 bookmarks) ForgeTrain was harder to dismiss than typical "AI wrote this" announcements because the methodology and benchmarks were public. The linked repo made that notable by publishing a claimed 44.13% MFU result on H100 and framing the framework as code produced end-to-end by an autonomous agent loop.
7. Where the Opportunities Are¶
[+++] Workflow-specific evaluation and routing infrastructure — Evidence appeared across Merge Gateway, THOR, Vals, DeepLearning.AI's benchmark-coverage critique, and AgentScoreboard. The strongest pattern on May 26 was that teams no longer trust one leaderboard to decide model choice, but they also do not yet have a default replacement.
[+++] Verifiable agent control and process-enforcement layers — AlphaProof Nexus, ActiveGraph, Flare Confidential Compute, the Alpha Arena trading failure, and the compliance-verification pushback all point to the same gap: the model may be impressive, but the system still needs a way to prove what happened and reject bad steps before they matter.
[++] Domain-grounded data and knowledge substrates — BioStack, SciAtlas, and THOR show builders repeatedly wrapping the missing evidence layer around one workflow. This is a moderate-to-strong opportunity because the pain is explicit, but credible builders are already forming in healthcare, security, and research.
[++] Rights, provenance, and appeals for synthetic media and regulated AI — Chris Olah's oversight call, the Tsuda lawsuit, and the compliance discussion all showed institutions looking for recourse, not just accuracy. The need is clear, but the current responses are still more legal and policy driven than productized.
[+] CPU-aware agent infrastructure — NVIDIA Vera, the demian_ai thread, and the Mizuho note all suggest a growing market for systems that optimize orchestration, memory movement, and tool-heavy agent work outside the GPU headline story. The opportunity is emerging, but incumbent hardware vendors already have momentum.
8. Takeaways¶
- Benchmark skepticism is now operational, not philosophical. Merge Gateway, THOR, and the labor-coverage critique all pointed to the same shift: teams want benchmark outputs that map to a workflow, not a universal ranking. (source)
- Reliability progress is increasingly coming from structure around the model. Fast-weight consolidation, Lean-backed proof verification, and deterministic evidence compilation all got more attention than prompt tricks or vague autonomy claims. (source)
- Governance became most legible when tied to real enforcement or enterprise process. Chris Olah's oversight call, the Tsuda lawsuit, and the compliance thread all turned AI governance into questions of consent, recourse, and verification. (source)
- The strongest builders were shipping missing substrates rather than generic assistants. BioStack, SciAtlas, THOR, and ForgeTrain all packaged the overlooked layer - data, evaluation, knowledge structure, or infrastructure code - around one narrow job. (source)
- Agentic AI is widening the hardware conversation beyond GPUs. NVIDIA Vera, demian_ai's CPU thesis, and the Mizuho note all treated orchestration, file work, and memory movement as a first-class bottleneck. (source)