Twitter AI - 2026-05-26¶
1. 人们在讨论什么¶
1.1 评估不再只是记分牌,而成了控制层 🡕¶
5 月 26 日最响的讨论簇是评估,但重心变了。人们不再问哪个前沿模型赢了通用排行榜,而是在争论:谁来定义基准测试、它覆盖什么类型的工作,以及它能不能安全地为真实生产流量做路由。至少有 6 条保留样本支撑了这一主题。
@JayminSOfficial 认为,基准测试排行榜已经悄悄成了模型选型的默认操作系统(416 次点赞、590 次转发、30 条回复、44,477 次浏览);而被引用的 @shensi 的 Merge Gateway 发布则说,团队不该追着当前冠军跑,而是应该定义自己的权重、基准和评估。Merge 的 Build Your Own Router post 把这件事讲得很具体:组织可以把标准基准、行业榜单和自定义分数组合起来,然后追溯为什么某个模型赢得了那次路由决策。
@ValsAI 发起 了一项为期 3 到 6 个月的 fellowship,专门支持新的基准测试和评估技术(195 次点赞、12 条回复、18,199 次浏览、356 次收藏);回复区立刻把目光投向语音 AI 和 AI 驱动投资指标等尚未解决的缺口。值得注意的变化,不只是又多了一条基准测试帖子,而是评估本身被当成了一个有资金支持的研究类别。
@cyb3rops 分享 了 THOR 发现分诊基准测试,因为通用 LLM 排行榜并不能帮 RuneAI 判断一个混乱的端点告警到底该被压下、送审,还是升级(70 次点赞、4 条回复、4,923 次浏览、47 次收藏)。公开的 基准测试站点 和 仓库 写明,目前版本覆盖 45 个模型、10 份 THOR 报告、189 条专家分类发现,并给出 Operational Triage Score、关键漏报和误审负载等指标。
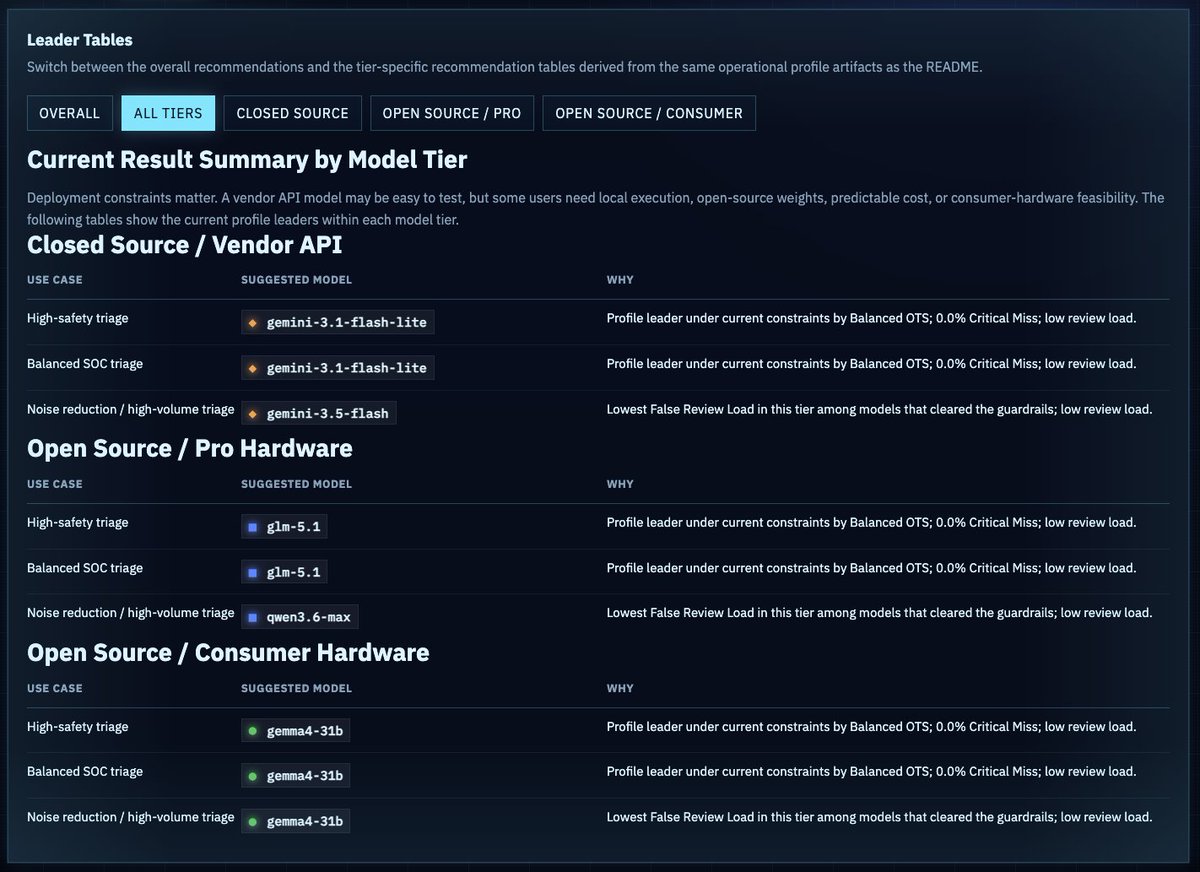
这张截图之所以重要,是因为它把评估输出呈现成部署决策表,而不是单一总冠军。
@DeepLearningAI 提到 了 Carnegie Mellon 和 Stanford 的研究:43 个智能体基准测试、72,342 个任务,仍然相对美国更广泛劳动力市场,过度偏向软件类工作(11 次点赞、9 条回复、848 次浏览)。链接的 论文 把当天对基准测试的怀疑,从一种感觉,落成了可衡量的覆盖问题。
讨论要点: Merge、Vals 和本地模型讨论串里的回复,都收敛到同一种怀疑:分数只有绑到具体工作流上才有用,不能被当成普适智能徽章。
与前日对比: 5 月 25 日已经把评估推进到更真实的环境和内建产品工具里。5 月 26 日则又往前走了一步,直接攻击基准测试本身:谁定义它、它覆盖什么工作,以及它究竟怎么给生产流量做路由。
1.2 可靠性工作开始聚焦可验证的推理与记忆 🡕¶
第二个讨论簇把可靠性当成结构设计问题,而不是提示词问题。共同模式是把更多工作搬进可检查的中间状态:fast weight 巩固、编译器可验证证明,或确定性证据汇编。3 条保留样本构成了这个主题的支点。
@iScienceLuvr 分享 了新论文《Language Models Need Sleep》(697 次点赞、23 条回复、43,042 次浏览、568 次收藏);链接的 arXiv 摘要 说,这个模型会周期性地把近期上下文转成持久快速权重(fast weights)、清空 KV cache,并在“睡眠”期间通过离线循环过程提升更难的推理任务。随附首页之所以重要,是因为它把精确机制摆了出来——状态空间模型块里的快速权重,加上离线 recurrence——而不是只停留在比喻层。

@HowToAI_ 表示,AlphaProof Nexus 通过把 LLM 和 Lean 证明编译器配对,解开了长期未解的数学问题(46 次点赞、6 条回复、2,358 次浏览、38 次收藏)。那篇 论文 也确认了核心结果:最强智能体解决了 353 个公开 Erdos 问题中的 9 个,并证明了 492 个 OEIS 猜想中的 44 个;而一个更简单的“生成加验证”闭环虽然复现了 Erdos 方向的成功,但在最难案例上成本更高。

@yoheinakajima 表示,即便不做图谱事实抽取、也不写入语义记忆,ActiveGraph 在 LongMemEval-S 上依然撑住了(32 次点赞、9 条回复、5,685 次浏览、30 次收藏)。链接的 technical note 说,这套系统在 2,462 token 预算下达到了 85.6% 的 QA 准确率和 86.2% 的 answer-in-context,统计上与稠密 turn-level RAG 持平,但在检索侧表现出了可测量的优势。
讨论要点: 最技术向的回复,并没有要求更好的提示词。大家拿“睡眠”论文和 replay buffer 对比,问 ActiveGraph 是否依赖实体抽取,得到的回答是“这里没有 extraction”——这说明从业者确实在盯确定性机制和硬反馈闭环。
与前日对比: 5 月 25 日强调现实评估环境。5 月 26 日又加上了模型或运行框架内部的可靠性机制:fast weights、证明检查器,以及事件溯源式的证据汇编。
1.3 一旦和合规、同意绑定,治理讨论就会变得具体 🡒¶
治理对话依然热,但最强帖子不是抽象伦理串,而是在谈谁来监督前沿 AI、当合成输出侵犯同意时会怎样,以及企业合规自动化是否终于从“能拿来试点”跨到了“值得信任”。3 条保留样本支撑了这一主题。
@Reuters 报道 称,Anthropic 联合创始人 Chris Olah 说,AI 开发不能只交给科技公司,应该由宗教领袖、政府和公民社会共同监督(19 次点赞、8 条回复、11,400 次浏览)。即便无法读到付费的 Reuters 正文,仅从推文本身也能清楚看出,这条监督主张十分明确,也让围绕通谕的讨论获得了更主流的传播。
@Anime 报道 称,声优津田健次郎起诉 TikTok,指控其未经授权使用生成式 AI 模仿自己的声音(30 次点赞、1,723 次浏览)。链接的 Anime News Network story 把这件事从假设风险,落成了一场现实里的权利纠纷。
@a16z 认为,合规也许终于会从“勉强够 pilot”走到“已经够到可以信任”(38 次点赞、6 条回复、9,174 次浏览、23 次收藏);链接的 essay 说,前沿模型如今在 LegalBench 的 162 项法律推理任务上已经达到 80%-100% 的得分。那张图之所以重要,是因为它显示准确率的跃升就发生在最近,这也解释了为什么合规如今会重新成为创业类别,而不是两年前就已经爆发。

讨论要点: 最有分量的反驳出现在合规讨论串里:有人回复说,“90% 正确的产品,仍然可能是 100% 错的”,并转而主张在做出最终落定前先验证。这样一来,当天的治理讨论就被锚定在流程和申诉,而不只是采用乐观主义。
与前日对比: 5 月 25 日混合了通谕摘录、学术诚信数据和合成语音诉讼。5 月 26 日保持同一治理框架,但更贴近企业软件和正在发生的权利执行。
1.4 构建者的精力仍集中在工作流基础设施上 🡕¶
构建活动依然强劲,但模式比通用 AI 助手要更窄。最强信号的项目,都是把缺失的底层能力包在某个具体工作流周围:医疗后训练、可验证执行,或科学证据检索。4 条保留样本都符合这个形状。
@ycombinator 分享 了 BioStack,把它描述成让医疗 AI 模型在混乱临床记录、延迟结果、奖励和基准中训练的仿真环境(108 次点赞、10 条回复、476,173 次浏览、85 次收藏)。BioStack 的 site 又补充说,这家公司还出售面向 ML 的医疗数据集,覆盖 EHR、化验、影像、ECG、病历笔记和结果,以及 RL 环境和多智能体推理基础设施。
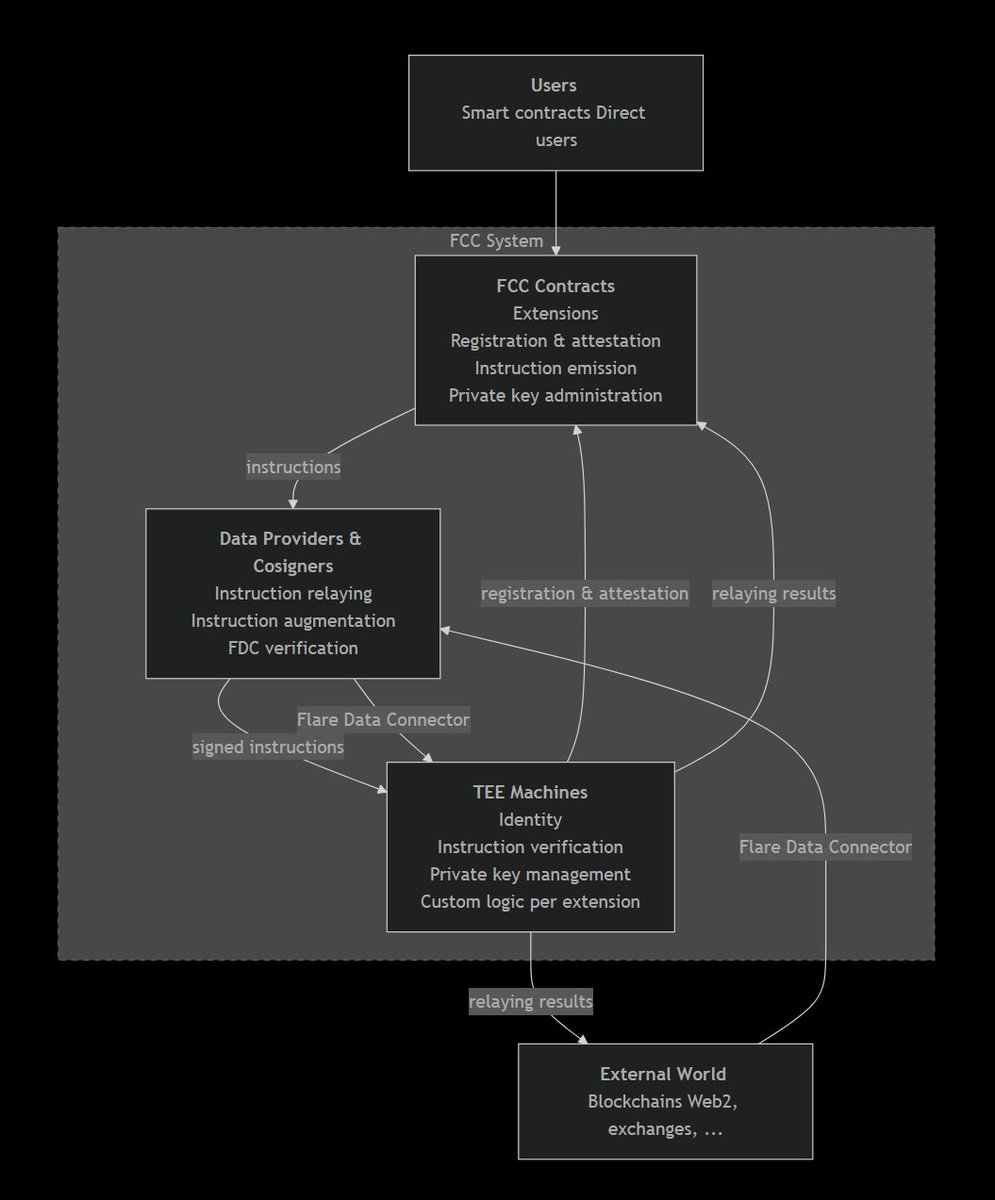
@FlareDevHub 概述 了 Flare Confidential Compute:它试图证明到底跑了哪个模型、保持敏感输入私密、把签名密钥放在 TEE 里,并在可验证输出上结算智能体对智能体支付(33 次点赞、2 条回复、2,965 次浏览)。随附工作流图让这件事具体了很多,因为它展示的是 confidential compute 组件和支付流,而不是一句泛泛的“智能体金融”口号。
@zxlzr 分享 了 InnoEval 和 SciAtlas,把它们描述成围绕深度知识搜索、多视角审查和 4300 万篇论文知识图谱构建的科学想法评估栈(8 次点赞、167 次浏览、4 次收藏)。链接的 InnoEval paper、SciAtlas paper 和 SciAtlas repo 说明,这是一套面向文献综述、想法落地、趋势综合和基于证据评估的检索底座。
@TheAIWorld22 表示,ForgeTrain 比常见那种“AI 写了这个”的公告更像真的东西,因为它把基准测试公开了,方法论也开源了(9 次点赞、318 次浏览、5 次收藏)。公开的 ForgeTrain repo 声称,这个框架是由一套自主智能体闭环端到端写成的,并报告了 H100 上 44.13% 的 MFU。
讨论要点: 这个讨论簇里的回复反复回到可审计性、隐私和可复现性。市场信号很清楚:构建者已经不能只交付一个 demo 层,他们还得解释数据从哪来、工作流怎么检查,以及系统能不能复现。
与前日对比: 5 月 25 日已经偏向工作流原生系统。5 月 26 日则把同一种直觉再往底座层推进了一层:后训练环境、confidential compute、科学知识图谱,以及 AI 编写的基础设施。
1.5 CPU 再次以独立的智能体式 AI 瓶颈身份出现 🡕¶
一个规模较小但清楚的主题,把智能体式 AI 重新讲成 CPU 故事,而不只是 GPU 故事。证据来自 NVIDIA 的产品推进、从业者对工具使用开销的讨论串,以及一份把智能体需求和 DRAM 紧缺联系起来的卖方笔记。3 条保留样本支撑了这一主题。
@nvidia 表示,Vera 是专门为智能体式 AI 打造的(70 次点赞、8 条回复、5,869 次浏览)。NVIDIA 的 product page 写明,这颗芯片有 88 个 Olympus 核、最高 1.2 TB/s 的 LPDDR5X 带宽,而且机架级设计能运行超过 22,500 个并发环境。NVIDIA 另一个 delivery post 则把这颗 CPU 定义成工具调用、编排、长上下文检索和强化学习环境的基础设施,而不是泛用宿主处理器。
@demian_ai 认为,智能体式编程运行框架的大量时间,其实都花在 CPU 工作上,比如工具使用、文件编辑、lint 和 shell 编排,因此 CPU 需求弯折上升的速度,比旧的容量规划假设更快(22 次点赞、3 条回复、1,438 次浏览、11 次收藏)。@sean___ 又补充 了一份 Mizuho 笔记,称 NVIDIA 的 CPU 收入可能意味着大约 3K PB 的增量 CPU 需求,而且一些客户仍处在 30%-50% 的供给不足状态(41 次点赞、4,160 次浏览、20 次收藏)。
讨论要点: NVIDIA 发布帖下最有价值的回复,并没有在谈股价,而是在说:真正能吃到红利的,会是那些把 CPU 和 GPU 端到端整合到一起的团队,因为他们能把延迟更低、面向智能体的基础设施真正用起来。
与前日对比: 5 月 25 日已经有硬件讨论,但语气还更轻。到了 5 月 26 日,CPU 本身成了被点名的瓶颈,而不再只是 GPU 和 HBM 背后的一个配角。
2. 令人困扰的问题¶
基准测试的胜利,仍然告诉不了团队该部署什么¶
反复出现的抱怨,不是缺少基准测试,而是错误的基准测试握了太多权力。@JayminSOfficial 认为,研究排行榜如今已经在引导生产流量(416 次点赞、590 次转发、30 条回复、44,477 次浏览);@cyb3rops 则展示了,为什么这在安全分诊里会失效——真正有用的问题,不是谁最会写代码,而是谁最会对混乱的端点发现做压制、送审或升级(70 次点赞、4 条回复、4,923 次浏览、47 次收藏)。@DeepLearningAI 又补充 说,连基准组合本身都仍然过度代表软件工作,而不是更广泛劳动力市场(11 次点赞、9 条回复、848 次浏览)。可见的应对行为,是构建自定义路由配置、领域专用基准套件,以及新的评估计划,而不是相信一个头条分数。严重程度:高。这个方向值得做——信息流依旧指向一个缺失的翻译层:把基准测试输出真正变成生产选型。
强模型仍会在流程、可审计性和验证上失手¶
第二类挫败感是:强模型一旦碰到需要流程纪律、而不是漂亮文案的工作流,就仍然会翻车。@metatronics_ 写道,前沿智能体在 Alpha Arena 里亏钱,并不是因为它们讲不清市场,而是因为过度交易、仓位控制松散,以及止损总在事后才设(7 次点赞、10 条回复、1,676 次浏览)。@ycombinator 分享 了 BioStack(108 次点赞、10 条回复、476,173 次浏览、85 次收藏),而其中一条回复立刻把买方测试重写成可审计性问题:医院能不能顺着模拟病历、奖励规则和临床签字,追溯到一条糟糕建议的来源?在合规讨论串里,@a16z 给出了 当天最强的自动化正面论证(38 次点赞、6 条回复、9,174 次浏览、23 次收藏),但最有分量的一条回复又反驳说:如果高风险决策已经落定,即便 90% 正确的合规产品,也仍然等于错。可见的绕行模式,是在模型外层再加确定性检索、形式验证器,或显式流程控制。严重程度:高。这个方向值得做——流程层明显还没有建好。
权利、同意和申诉层仍然很薄¶
治理类帖子一旦涉及身份和救济路径,就会变得最具体。@Reuters 报道 了 Chris Olah 对科技公司之外监督的呼吁(19 次点赞、8 条回复、11,400 次浏览),这本身就说明现有制度制衡并未被寄望于市场自动长出来。@Anime 报道 了津田健次郎起诉 TikTok 涉嫌未经授权使用 AI 语音(30 次点赞、1,723 次浏览),说明“同意”问题已经进入可诉层面,而不是纸面推演。@a16z 及其 回复也暴露出,合规工作流里的申诉仍很脆弱:企业也许更愿意信任模型了,但他们依然希望在错误决定变成监管事故或面向客户的失败前,先有验证和回退。严重程度:高。这个方向值得做——来源追踪、同意和申诉工具的厚度,仍然明显赶不上它们要承接的风险。
智能体式工作负载正在暴露 CPU 和内存瓶颈¶
另一类挫败感来自基础设施:智能体式 AI 一直被说成模型问题,但信息流越来越把它当成系统问题来讨论。@nvidia 把 Vera 定位成智能体式 AI 的 CPU(70 次点赞、8 条回复、5,869 次浏览),@demian_ai 认为 工具使用、文件编辑、lint 和编排让智能体式编程运行框架天然偏 CPU(22 次点赞、3 条回复、1,438 次浏览、11 次收藏),而 @sean___ 贴出的 Mizuho 笔记则指向供给不足和价格压力(41 次点赞、4,160 次浏览、20 次收藏)。在信息流里可见的应对方式,不是放弃加速器,而是开始按端到端 CPU 加 GPU 的系统去思考,并把编排硬件当成一等设计变量。严重程度:中高。这个方向值得做——但它是资本密集型机会,而且现有巨头已经开始行动。
3. 人们期望的功能¶
面向特定工作流的路由与评估控制平面¶
最强的隐含需求,是有一层能把抽象模型分数翻译成产品特定决策。@JayminSOfficial 认为,为论文而造的基准测试已经在决定生产流量(416 次点赞、590 次转发、30 条回复、44,477 次浏览);而链接的 Merge Gateway 发布,给出的回应就是让团队为自己的基准加权并上传自定义分数。@ValsAI 发起 了新的评估技术 fellowship(195 次点赞、12 条回复、18,199 次浏览、356 次收藏),@DeepLearningAI 则强调,当前智能体基准仍然漏掉了真实劳动市场的大块工作(11 次点赞、9 条回复、848 次浏览)。这是一个高度紧迫的现实需求。Merge Gateway、THOR 和 fellowship 支持的评估工作,已经给出一些局部答案,但整套栈看起来仍然碎片化,远未定型。机会:直接。
能证明智能体到底做过什么的可验证流程层¶
第二个未被满足需求,不是更聪明的答案生成器,而是一套能证明工作确实正确发生的系统。@HowToAI_ 指向 了 AlphaProof Nexus 这类 Lean 支撑的证明闭环(46 次点赞、6 条回复、2,358 次浏览、38 次收藏),@yoheinakajima 则提到 了先做确定性证据汇编、再进入语义记忆(32 次点赞、9 条回复、5,685 次浏览、30 次收藏),@FlareDevHub 又概述了 面向智能体的可验证推理与安全密钥托管(33 次点赞、2 条回复、2,965 次浏览)。@metatronics_ 给出了 这件事为什么重要的反面例子:毁掉真实交易结果的,不是语言能力,而是流程失控(7 次点赞、10 条回复、1,676 次浏览)。这是一个高度紧迫的现实需求。局部答案已经存在,但大多还只是孤立技术,不是一层可靠控制面。机会:直接。
面向合成身份与自动决策的同意、来源追踪和申诉系统¶
信息流也清楚指向了一层围绕 AI 输出的缺失权利管理体系,尤其当这些输出会影响真人时。@Reuters 报道 了来自外部监督的明确呼吁(19 次点赞、8 条回复、11,400 次浏览),@Anime 报道 了一场围绕 AI 语音滥用的诉讼(30 次点赞、1,723 次浏览),而 @a16z 则认为,合规工作之所以现在才变得更像 AI 可解问题,是因为准确率终于上来了(38 次点赞、6 条回复、9,174 次浏览、23 次收藏)。把这些放在一起,就能看出人们想要的是:当 AI 模仿某个人,或代替系统做出受监管决策时,必须有同意记录、来源追踪,以及能走回来的申诉路径。这同时是现实需求,也是制度需求,而且紧迫度很高。今天能看到的答案,更多还是诉讼、通谕和验证插件,而不是成型产品。机会:直接。
扎根具体领域的数据与知识底座¶
另一个清晰需求,是让数据和知识层长得像真实任务,而不是一条通用基准测试提示词。@ycombinator 分享 了 BioStack,因为医疗后训练需要的是混乱病历、延迟结果和奖励闭环同时存在于一套系统里(108 次点赞、10 条回复、476,173 次浏览、85 次收藏)。@zxlzr 分享 了 SciAtlas 和 InnoEval,把科学想法评估扎进一个 4300 万篇论文的图谱里(8 次点赞、167 次浏览、4 次收藏),而 @cyb3rops 则围绕 真实 THOR 报告,构建了公开分诊基准(70 次点赞、4 条回复、4,923 次浏览、47 次收藏)。这是一个现实需求,紧迫度中高,而且已经吸引到有分量的构建者。机会:具竞争性。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Merge Gateway | LLM 路由 / 控制平面 | (+) | 允许团队为基准加权、上传自定义分数、审计路由决策,并把路由和 DLP、提示注入控制结合 | 仍依赖客户自定义评估,以及团队自己能凑出的基准覆盖面 |
| Vals AI / Vals Fellowship | 评估平台 / 研究计划 | (+) | 为难评估问题提供资金,并给研究者 API 积分、GPU、人类数据和评估基础设施 | 回复区本身就暴露出语音 AI 和长周期投资指标等未解领域 |
| THOR Finding Triage Benchmark | 安全基准测试 | (+/-) | 领域专用分诊指标、45 个模型、10 份报告、189 条专家标注发现,以及部署档位建议 | 在作者期待的完整工具增强工作流之前,它仍只是一个干净基线 |
| ActiveGraph | 记忆 / 运行时 | (+/-) | 确定性摄取、紧凑证据汇编,以及在低上下文预算下 LongMemEval-S 的强检索表现 | 与稠密 turn-level RAG 统计上只是持平,语义记忆也还没加进来 |
| AlphaProof Nexus + Lean | 形式证明栈 | (+) | 编译器支撑的验证、公开难题结果,以及能拒绝错误推理步骤的清晰机制 | 更难的问题成本更高,而且方法依赖可形式化领域 |
| BioStack | 医疗数据 / RL 环境 | (+) | 面向 ML 的临床数据、延迟结果闭环、奖励函数,以及医疗 AI 后训练环境 | 一旦想像进生产部署,人们立刻就会追问可审计性和隐私 |
| LegalBench-led compliance AI | 法律 / 合规基准层 | (+/-) | 前沿模型进步让文档密集型合规自动化更可行,也更具商业紧迫性 | 讨论串自己的反驳也强调,即便准确率高,落定前仍需要验证 |
| SciAtlas | 科学知识图谱 / 智能体技能 | (+) | 4300 万篇论文、1.57 亿实体、30 亿三元组,以及面向文献综述、想法落地和趋势综合的结构化检索 | 论文仍标成 ongoing work,生态也还很早 |
| ForgeTrain | 训练基础设施 | (+/-) | 公开仓库、AI 编写代码库,以及 44.13% MFU 的公开说法 | 运行框架本体还在 coming soon 阶段,因此完整“自主构建”故事仍只释放了一部分 |
| Flare Confidential Compute | 可验证计算 / TEE 栈 | (+/-) | 可验证推理、私密输入、安全密钥托管,以及智能体支付逻辑被放进同一个概念里 | 公开文档仍然很薄,因此今天最强证据还是那张架构图和推文串 |
| NVIDIA Vera CPU | CPU / 智能体硬件 | (+) | 88 个 Olympus core、最高 1.2 TB/s 带宽,并明确为 RL 环境、编排和工具密集型智能体工作负载优化 | 首批系统才刚进入客户评估,真实采用曲线还没跑清楚 |
整体来看,人们最喜欢的是那些会约束或扎根模型行为的工具,而不是只承诺一个“更聪明的模型”。大家偏爱能暴露策略的路由层、贴任务的基准测试、能拒绝坏步骤的证明系统,以及像真实工作那样组织数据与知识的底座。
信息流里可见的绕行方式,是从单一通用排行榜转向加权基准配置;从完整历史提示词,转向确定性证据汇编;从手工合规,转向 AI 加验证;以及从“只看 GPU”,转向对 CPU 也有感知的系统设计。竞争压力最明显的地方,是路由、评估和合规,因为即便垂直方向不同,多个构建者也都在收敛到相似的控制层问题上。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Merge Gateway | @shensi / @merge_api | 用加权基准和策略配置来路由 LLM 请求 | 每次有新模型登顶通用排行榜,团队都得重测、重集成 | Benchmark library, custom scores, routing configs, policy routing, DLP, prompt-injection controls | Shipped | tweet · blog |
| BioStack | @sanatmishra7 / @patwa_parth | 为医疗 AI 后训练构建仿真环境和数据管道 | 医疗模型需要的是混乱记录、延迟结果和奖励闭环,而不是只有排行榜 demo | RL environments, healthcare datasets, annotation, reward functions, multi-agent reasoning infrastructure | Shipped | tweet · site |
| THOR Finding Triage Benchmark | @cyb3rops | 在安全事件与取证发现分诊任务上评估模型 | 通用推理或编程排行榜,告诉不了团队模型在 SOC 分诊里会怎么表现 | THOR reports, Operational Triage Score, critical-miss rate, false-review load, public repo/site | Shipped | tweet · site · repo |
| ActiveGraph | @yoheinakajima | 面向智能体记忆与证据汇编的事件溯源图运行时 | 长时程记忆系统需要可复现的证据组装方式,又不能付出过高检索成本 | Event log, deterministic graph projection, embeddings, LLM reader, benchmark harness | Alpha | tweet · blog · repo |
| SciAtlas | @zxlzr | 为科学研究智能体提供知识图谱底座和客户端工具 | 一旦证据长期碎片化、无结构,文献检索和想法评估就会失灵 | 43M-paper KG, graph reranking, CLI/API, agent skills | Alpha | tweet · paper · repo |
| ForgeTrain | @OpenBMB | 面向 LLM 训练的 AI 编写预训练框架 | 基础设施代码自动生成的说法,通常缺少开放方法论和可量化输出 | Autonomous agent loop, PyTorch/CUDA stack, H100 training framework, MFU benchmarking | Beta | tweet · repo |
| Flare Confidential Compute | @FlareDevHub | 提出可认证模型执行、私密输入、安全密钥托管和智能体支付 | 今天的智能体既难以证明到底跑了哪个模型,也很难安全持有密钥或处理支付 | TEE-style enclaves, attestation, onchain proofs, key custody, agent-payment flow | RFC | tweet |
| AgentScoreboard | @Paymindai | 为银行智能体提供排名、徽章和可导出成绩单 | 智能体基准测试与认证仍难在产品内比较和操作化 | Elo ranking, time decay, domain scores, badge system, Markdown/JSON export | Alpha | tweet |
Merge Gateway 和 THOR 是当天最清楚的两个例子,说明共同的构建触发点是什么:通用排行榜已经不够用了。Merge 的回答,是让路由策略可配置;THOR 的回答,则是发布一个带部署档位、关键漏报指标和公开工件的安全专用基线。
BioStack 和 SciAtlas 则从数据侧面攻击同一个结构性缺口。BioStack 把真实临床证据、延迟结果和奖励闭环包进一套医疗后训练栈里;SciAtlas 则把 4300 万篇论文和 1.57 亿实体装进图谱,让研究智能体能围绕有根据的评估和文献工作来查询。
ForgeTrain、Flare Confidential Compute 和 AgentScoreboard 又展示了第二种模式:控制层本身正在变成产品。ForgeTrain 把可复现性和性能说法做成公开仓库,Flare 试图让执行和支付流可认证,而 AgentScoreboard 则把比较与认证做成面向用户可见的功能,而不再只是一张内部电子表格。
6. 新动态与亮点¶
LLMorphism 给反拟人化批评起了个更锋利的名字¶
@ValerioCapraro 认为,人们越来越把人类认知当成像大语言模型那样运作,并把这种错误命名为“LLMorphism”(70 次点赞、19 条回复、11,644 次浏览、53 次收藏)。随附信息图和链接的 论文 让这个词变得值得注意,因为它把讨论从泛泛的拟人化警告,推进到了更具体的机制、后果和缓解办法。

消费级硬件上的编程模型继续缩小与前沿模型的差距¶
@bridgemindai 贴出 一张图,说本地 Gemma 和 Qwen 变体如今已经在某项编程图表上超过 GPT-5,但仍落后于 GPT-5.5 和 Claude Opus 4.7(146 次点赞、21 条回复、7,284 次浏览)。这张图之所以值得注意,是因为它把差距可视化了,而不是只停留在口头描述;但最高赞回复也立刻反驳说,基准测试分数并没有反映真实质量——这正好压缩呈现了当天更大的“基准测试张力”。

智能体排名开始看起来像一种产品原语¶
@Paymindai 宣布 更新 AgentScoreboard,为银行智能体加入 Elo 风格排名、时间衰减、领域分数、徽章和 Markdown/JSON 导出(17 次点赞、1 条回复、528 次浏览)。这还是一个早期信号,但值得注意,因为它把智能体对比和认证从内部基准表,搬成了产品内功能。
AI 编写的训练基础设施,变成了更具体的公共工件¶
@TheAIWorld22 表示,ForgeTrain 比常见那种“AI 写了这个”的公告更难被轻易否定,因为它把方法和基准都公开了(9 次点赞、318 次浏览、5 次收藏)。链接的 仓库 之所以让它值得注意,是因为仓库公开了在 H100 上 44.13% MFU 的说法,并把这个框架表述为一套由自主智能体闭环端到端生成的代码。
7. 机会在哪里¶
[+++] 面向特定工作流的评估与路由基础设施 — Merge Gateway、THOR、Vals、DeepLearning.AI 对基准覆盖面的批评,以及 AgentScoreboard,都指向同一件事。5 月 26 日最强的模式,是团队已经不再信任一个排行榜来决定模型选型,但他们也还没有默认替代方案。
[+++] 可验证的智能体控制与流程执行层 — AlphaProof Nexus、ActiveGraph、Flare Confidential Compute、Alpha Arena 的交易失败,以及合规讨论串里的验证反驳,都指向同一个缺口:模型也许很惊艳,但系统仍然需要一层能证明发生过什么、并在坏步骤真正造成影响前把它拒掉的机制。
[++] 扎根具体领域的数据与知识底座 — BioStack、SciAtlas 和 THOR 都显示,构建者在反复把缺失的证据层包到某个具体工作流周围。这是中强度机会,因为痛点很明确,但医疗、安全和研究里已经都有靠谱构建者在场。
[++] 面向合成媒体和受监管 AI 的权利、来源追踪与申诉 — Chris Olah 的监督呼吁、津田诉讼,以及合规讨论,都说明制度层想要的不是更高准确率本身,而是出错时能追、能挡、能申诉。需求非常明确,但当前回应仍更多是法律和政策推动,而不是成熟产品。
[+] 感知 CPU 约束的智能体基础设施 — NVIDIA Vera、demian_ai 的 CPU 论点,以及 Mizuho 笔记,都说明编排、内存搬运和工具密集型智能体工作,正在 GPU 之外催生一个增长中的系统市场。这个机会正在冒头,但硬件巨头已经握有明显势能。
8. 要点总结¶
- 对基准测试的怀疑,如今已经是运维级的,而不只是哲学级的。 Merge Gateway、THOR 和对劳动覆盖面的批评,都在指向同一转变:团队想要的是能映射到具体工作流的评估输出,而不是一个普适排名。(source)
- 可靠性进展,越来越来自模型周围的结构。 fast weight 巩固、Lean 支撑的证明验证,以及确定性证据汇编,都比提示词技巧或空泛的自主性口号获得了更多注意力。(source)
- 治理只有在连到真实执行或企业流程时,才变得最清晰。 Chris Olah 的监督呼吁、津田诉讼,以及合规讨论串,都把 AI 治理压缩成了同意、申诉和验证问题。(source)
- 最强的构建者,交付的是缺失底座,而不是通用助手。 BioStack、SciAtlas、THOR 和 ForgeTrain,都围绕一项狭窄任务,把被忽视的数据层、评估层、知识结构或基础设施代码打包出来。(source)
- 智能体式 AI 正在把硬件讨论从 GPU 扩展出去。 NVIDIA Vera、demian_ai 的 CPU 论点,以及 Mizuho 笔记,都把编排、文件工作和内存搬运点名为一等瓶颈。(source)