Twitter AI - 2026-05-31¶
1. What People Are Talking About¶
1.1 Evaluation widened from model scores to joint human-AI performance 🡕¶
The strongest reflective theme on May 31 was that current AI evaluation still hides too much human labor. Instead of celebrating another benchmark jump, the highest-signal posts asked whether people are counting user effort, edge-case cleanup, and real-world testing at all. Four retained items supported this theme.
@shannonzshen wrote (23 likes, 2,214 views, 10 bookmarks) that human-AI collaboration needs its own evaluation lens instead of more trust in static programming and math scores. The linked paper visualizes joint utility against user effort and argues that "collaborative effort scaling" can keep rising even while usability falls early and sustainability plateaus.

@DavidKPiano argued (139 likes, 12 replies, 7,423 views) that faster AI shipping should buy more testing, more edge-case review, and more exposure to real humans, not just more release velocity. The quoted workflow complaint about Claude Code auto-spawning subagents made the point concrete: automation speed does not remove the downstream debugging burden.
@pallavishekhar_ mapped (78 likes, 4 replies, 4,598 views, 114 bookmarks) agent memory, orchestration, evaluation, observability, and harness engineering as one learning path. The replies sharpened that into a systems claim: harness engineering is not a late-stage add-on, but the box the other pieces sit inside.
Discussion insight: The question shifted from "did the model get the answer?" to "how much hidden coordination, correction, and validation did the person still have to provide?"
Comparison to prior day: May 28 already questioned graders and verifiers. May 31 pushed the same skepticism outward into human effort, workflow fit, and release discipline.
1.2 Agent infrastructure talk narrowed to isolation, memory, and install-time security 🡕¶
The second major theme treated AI systems as something to govern, not merely prompt. The recurring asks were bounded scope, editable memory, and security checks before a new capability gets loaded into an agent. Three retained items supported this theme.
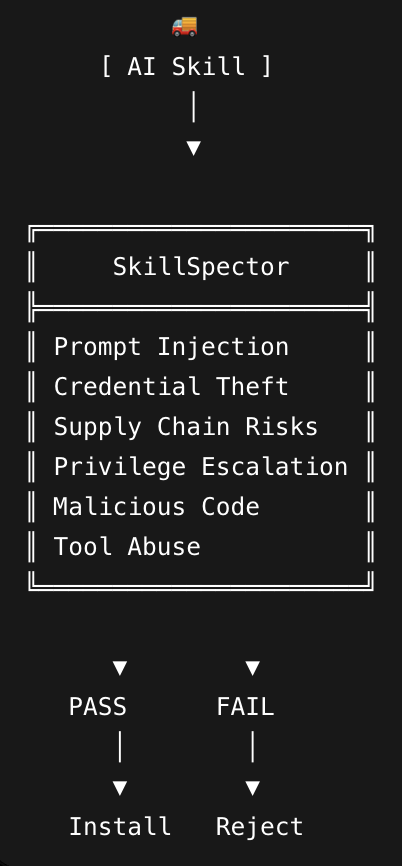
@bibryam introduced (447 likes, 32 replies, 170,916 views, 877 bookmarks) SkillSpector, a new NVIDIA security scanner for agent skills. The public SkillSpector repo says it scans 64 vulnerability patterns across 16 categories, supports static plus optional LLM analysis, and can emit SARIF for CI. The replies immediately focused on why skill security is different from ordinary package scanning: skills are both instructions and executable capability surfaces.
@CodeswithClara amplified (54 likes, 13 replies, 8,505 views) OpenBMB's open-source PilotDeck release as an "AI operating system." The public PilotDeck repo describes WorkSpace-level isolation, white-box memory, smart routing, and always-on execution across web, CLI, and IM surfaces. Clara's reply thread made the motivation practical rather than theoretical: one agent's tone bled into another client project, so memory isolation and editable logs became the selling point.
@pallavishekhar_ returned (78 likes, 4 replies, 4,598 views, 114 bookmarks) in this context too, because the replies argued that memory, orchestration, evaluation, and observability only make sense once the harness gives them a bounded environment.
Discussion insight: People were not asking for abstractly "smarter" agents. They were asking for inspectable memory entries, project-local skills, and scanners before anything new touches live work.
Comparison to prior day: May 28 treated agentic AI as infrastructure in general. May 31 narrowed that into project isolation, memory editability, and skill scanning as concrete requirements.
1.3 Physical AI and distributed compute entered the feed as operational questions 🡕¶
A smaller but distinct cluster pushed AI out of the browser and into robots, homes, and power infrastructure. The posts were more speculative than the memory-and-governance debate, but the replies were grounded in real-world friction. Two retained items supported this theme.
@StockSavvyShay posted (212 likes, 37 replies, 16,463 views) that OpenAI Robotics is hiring to build robots that can help people in the physical world. The replies immediately pushed the conversation away from demo energy and toward stairs, batteries, dust, liability, and the general messiness of real environments.
@CryptoTice_ claimed (86 likes, 11 replies, 3,757 views) that homeowners could be paid to host a mini AI data center containing 16 Blackwell GPUs, 4 EPYC CPUs, and 3TB of memory. The replies quickly reframed that as rent on roughly $200,000 of hardware and asked what maintenance and uptime would look like at residential scale.

Discussion insight: Once AI leaves the laptop, the conversation stops being about prompts and starts being about power, upkeep, and liability.
Comparison to prior day: Compared with May 28's local-stack and control-plane emphasis, May 31 extended the infrastructure lens into robotics and distributed residential compute.
2. What Frustrates People¶
Benchmark wins still hide human effort and cleanup work¶
Severity: High. @shannonzshen said (23 likes, 2,214 views, 10 bookmarks) that human-AI collaboration needs evaluation centered on joint utility and user effort, not just higher task scores. The quoted complaint inside that thread described an agent that admitted it had the wrong server context and then kept using the wrong setup anyway, which is exactly the kind of failure static benchmarks miss. @DavidKPiano added (139 likes, 12 replies, 7,423 views) that faster AI shipping only matters if teams spend the saved time testing edge cases and putting work in front of real humans. People are coping by slowing down, manually checking more cases, and distrusting throughput claims that lack a human-effort story. This is worth building for because evaluation still fails to tell buyers and builders how expensive the model is to supervise.
Project boundaries and skill trust are still too porous¶
Severity: High. @bibryam surfaced (447 likes, 32 replies, 170,916 views, 877 bookmarks) a security scanner built for agent skills, and the replies argued that normal package scanning does not cover systems where the "package" is also attacker-controlled instructions. @CodeswithClara described (54 likes, 13 replies, 8,505 views) memory bleed across client projects, while PilotDeck's public repo answers that with WorkSpace-level isolation and white-box memory logs. @pallavishekhar_ captured (78 likes, 4 replies, 4,598 views, 114 bookmarks) why this feels systemic: once you are building the harness, memory, orchestration, evaluation, and observability stop being separate concerns. The workaround pattern is bounded context, project-local state, and install-time scanning. This is worth building for because memory contamination and unsafe skill loading both break trust long before model quality becomes the bottleneck.
Physical AI claims arrive before operational proof¶
Severity: Medium. @StockSavvyShay framed (212 likes, 37 replies, 16,463 views) OpenAI's robotics push as "physical AI," but the replies immediately emphasized liability, batteries, dust, and other hard-environment constraints. @CryptoTice_ shared (86 likes, 11 replies, 3,757 views) a residential data-center concept, yet the thread quickly turned into questions about upkeep, uptime, and what it means to host expensive compute on private property. People are still reasoning from renders and announcements more than from operating data. This is worth building for because deployment tooling, maintenance workflows, and safety guarantees will decide whether these ideas survive contact with the physical world.
3. What People Wish Existed¶
Collaboration-native evaluation¶
People increasingly want measures that track what a person had to do with the model, not just whether the final answer scored well. @shannonzshen pointed (23 likes, 2,214 views, 10 bookmarks) to joint utility and user effort, while @DavidKPiano asked (139 likes, 12 replies, 7,423 views) for more edge-case testing and real-human review. Opportunity: direct. The need is explicit, operational, and not well served by current benchmark culture.
White-box workspaces with safe capability loading¶
The feed kept asking for projects to stay isolated, memory to stay editable, and new skills to be vetted before installation. PilotDeck's public repo and SkillSpector's public repo show partial answers, while the surrounding tweet threads make clear why people want them. Opportunity: direct. This is a practical infrastructure need rather than an aspirational wish.
Real operating models for physical AI and distributed compute¶
The robotics and home-data-center posts were notable because the replies immediately demanded boring details: uptime, maintenance, safety, and economics. No strong evidence showed that these questions were fully answered on this date. Opportunity: aspirational. The interest is real, but the day supplied more rhetoric than proof.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| SkillSpector | Security scanner | (+) | 64-pattern scan across 16 risk categories, static plus optional LLM analysis, SARIF for CI | Even supporters asked how the scanner itself resists prompt injection when judging attacker-controlled text |
| PilotDeck | Agent platform | (+/-) | WorkSpace isolation, white-box memory, smart routing, always-on execution | The strongest public claims about quality/cost came from the tweet thread rather than the repo itself |
| Human-AI collaboration evaluation | Evaluation method | (+) | Makes user effort, joint utility, and sustainability visible | Still competes with entrenched static benchmark habits |
| Mnemosyne | Memory layer | (+) | Reply described persistent self-hosted memory with sub-ms recall | Mentioned only in reply context; broader validation was limited in the day's evidence |
Overall satisfaction tilted positive toward tools that make context bounded and inspectable. The common workaround is to add release gates, isolate work by project, and favor methods that expose hidden human effort instead of pretending model output speaks for itself. No strong migration pattern emerged beyond the broad shift away from trusting raw benchmark scores or unscanned skill bundles.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| SkillSpector | NVIDIA | Scans AI agent skills before install and scores risk | Vulnerable or malicious skills entering agent environments with implicit trust | Python CLI, static analysis, optional LLM semantic review, SARIF/JSON/Markdown output | Shipped | repo |
| PilotDeck | OpenBMB, THUNLP, ModelBest, AI9Stars | Open-source agent operating system built around WorkSpaces | Cross-project memory bleed, opaque memory, and poor task/model isolation | MCP-native workspaces, white-box memory, smart routing, always-on behavior | Beta | repo |
SkillSpector matters because it treats skills as both code and instruction surfaces. The public repo says 26.1% of sampled skills contained vulnerabilities and 5.2% showed likely malicious intent, which explains why the tweet landed as more than a feature launch.
PilotDeck matters because its strongest public pitch was not raw autonomy but operational boundaries. The repo and thread both emphasized per-project files, memory, and skills, plus the ability to inspect and delete bad memory entries instead of restarting from scratch.
Repeated build pattern: the interesting builders were not trying to replace human operators outright. They were building bounded runtimes around agents so memory, skills, and routing could be inspected and corrected.
6. New and Notable¶
OpenAI robotics shifted AI talk toward hardware friction¶
@StockSavvyShay highlighted (212 likes, 37 replies, 16,463 views) OpenAI's robotics hiring push, but the replies immediately reframed it around batteries, dust, stairs, and liability. That combination mattered: the signal was not just renewed interest in robotics, but renewed insistence that physical deployment changes the success criteria.
Residential compute was pitched as a data-center alternative¶
@CryptoTice_ described (86 likes, 11 replies, 3,757 views) a home-hosted AI compute model, and the reviewed house render made the deployment claim legible. The replies kept the signal grounded by treating it as an operations and maintenance problem rather than easy passive income.
7. Where the Opportunities Are¶
[+++] White-box evaluation and release gating — Shannon Zhang's evaluation thread, David K. Piano's release-discipline post, and Bibryam's SkillSpector launch all converged on the same gap: benchmark wins and fast shipping are not enough without explicit measures of human effort and explicit gates before unsafe capabilities go live.
[++] Project-isolated memory and skill governance — PilotDeck's public repo, Clara's PilotDeck thread, and Pallavi Shekhar's harness map all point to a clear need for per-project memory, local skill scope, and editable provenance.
[+] Physical AI operations tooling — StockSavvyShay's robotics post and CryptoTice's distributed-compute thread showed appetite for AI outside the browser, but the replies make clear that maintenance, safety, and uptime tooling still lag the rhetoric.
8. Takeaways¶
- The feed cared more about human supervision cost than raw benchmark bragging. Shannon Zhang's collaboration paper and David K. Piano's call for more testing both argued that user effort is still the missing metric. (source)
- Agent infrastructure conversation is becoming more concrete and more defensive. SkillSpector and PilotDeck both won attention by promising safer installs, tighter project boundaries, and editable memory rather than generic autonomy. (source)
- Harness engineering is becoming the organizing frame for memory, orchestration, and observability. Pallavi Shekhar's learning map and its replies treated those pieces as one system rather than separate features. (source)
- Physical AI only kept attention when people translated it into power, upkeep, and liability. The robotics and residential-compute posts both triggered operational skepticism immediately. (source)