Twitter AI - 2026-05-31¶
1. 人们在讨论什么¶
1.1 评估视角从模型分数扩展到人机协同表现 🡕¶
5 月 31 日反思意味最浓的主题是,当前 AI 评估仍把太多人类劳动藏了起来。与其庆祝又一次基准测试跃升,信号最强的帖子更在追问:用户投入、边界情况清理,以及现实世界测试,究竟有没有被算进去。至少有 4 条保留条目支撑了这一主题。
@shannonzshen 写道(23 次点赞、2,214 次浏览、10 次收藏),人机协作需要自己的评估视角,而不是继续相信静态的编程和数学分数。链接的 论文 用图展示了联合效用与用户投入之间的关系,并指出“协作投入扩张”可以持续上升,即便可用性在早期下滑、可持续性进入平台期。

@DavidKPiano 认为(139 次点赞、12 条回复、7,423 次浏览),更快的 AI 交付,换来的应该是更多测试、更多边界情况审查,以及让更多真实用户接触产品,而不只是更高的发布速度。那条引用的工作流吐槽提到 Claude Code 会自动拉起子智能体,把这一点说得很具体:自动化提速,并不会消掉后续调试负担。
@pallavishekhar_ 把(78 次点赞、4 条回复、4,598 次浏览、114 次收藏)智能体记忆、编排、评估、可观测性和运行框架工程串成一条学习路径。回复把这点进一步收束成一个系统判断:运行框架工程不是后期附加项,而是承载其他部分的容器。
讨论要点: 问题已经从“模型答对了吗?”转成了“人还得补上多少隐藏的协调、纠错和验证?”
与前日对比: 5 月 28 日已经在质疑评分器和验证器。5 月 31 日则把同样的怀疑扩展到了人类投入、工作流契合度和发布纪律。
1.2 智能体基础设施讨论收束到隔离、记忆和安装时安全 🡕¶
第二个主要主题把 AI 系统当成需要治理的对象,而不只是提示词操作对象。反复出现的诉求,是有边界的作用范围、可编辑的记忆,以及在新能力被装进智能体前先做安全检查。至少有 3 条保留条目支撑了这一主题。
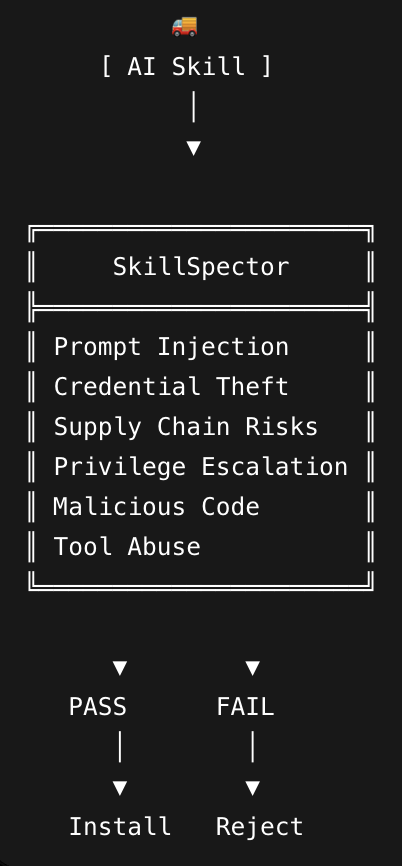
@bibryam 介绍了(447 次点赞、32 条回复、170,916 次浏览、877 次收藏)SkillSpector——NVIDIA 面向智能体技能推出的新安全扫描器。公开的 SkillSpector 仓库 称,它能扫描 16 个类别中的 64 种漏洞模式,支持静态分析以及可选的 LLM 分析,还能为 CI 输出 SARIF。回复立刻把焦点放在:为什么技能安全与普通包扫描不同——技能既是指令,也是可执行的能力暴露面。
@CodeswithClara 放大了(54 次点赞、13 条回复、8,505 次浏览)OpenBMB 把开源 PilotDeck 定位成“AI 操作系统”的说法。公开的 PilotDeck 仓库 把它描述成具备 WorkSpace 级隔离、白盒记忆、智能路由,并能跨 Web、CLI 和 IM 界面常驻执行的系统。Clara 的回复串把动机从理论拉回实际:一个智能体在某个客户项目里的语气,渗进了另一个客户项目,所以记忆隔离和可编辑日志成了卖点。
@pallavishekhar_ 在这一语境里也再次出现(78 次点赞、4 条回复、4,598 次浏览、114 次收藏),因为回复认为,只有当运行框架先给出一个有边界的环境时,记忆、编排、评估和可观测性才真正说得上有意义。
讨论要点: 人们要的不是抽象意义上更“聪明”的智能体,而是可检查的记忆条目、项目本地技能,以及任何新东西碰到在线工作前的扫描器。
与前日对比: 5 月 28 日把智能体化 AI 当作基础设施来谈。5 月 31 日则把它收束成项目隔离、记忆可编辑性和技能扫描这些更具体的要求。
1.3 物理 AI 和分布式算力开始以运营问题进入信息流 🡕¶
另一个规模较小但很鲜明的讨论簇,把 AI 从浏览器里推到了机器人、家庭和电力基础设施里。这些帖子比围绕记忆与治理的争论更偏猜想,但回复却牢牢落在现实世界的摩擦点上。至少有 2 条保留条目支撑了这一主题。
@StockSavvyShay 发帖称(212 次点赞、37 条回复、16,463 次浏览),OpenAI Robotics 正在招聘,要打造能在物理世界帮助人们的机器人。回复立刻把讨论从演示氛围拉向楼梯、电池、灰尘、责任归属,以及真实环境普遍的混乱。
@CryptoTice_ 声称(86 次点赞、11 条回复、3,757 次浏览),房主可以通过托管一座迷你 AI 数据中心获得报酬,这套设备包含 16 张 Blackwell GPU、4 颗 EPYC CPU 和 3TB 内存。回复很快把它重写成一笔约 20 万美元硬件的出租生意,并追问这种住宅规模下的维护和可用性到底会怎样。

讨论要点: 一旦 AI 离开笔记本,讨论就不再是提示词,而是电力、维护和责任。
与前日对比: 相比 5 月 28 日对本地栈和控制平面的强调,5 月 31 日把基础设施视角延伸到了机器人和分布式住宅算力。
2. 令人困扰的问题¶
基准测试的胜利仍然掩盖了人类投入和清理工作¶
严重程度:高。@shannonzshen 说(23 次点赞、2,214 次浏览、10 次收藏),人机协作需要以联合效用和用户投入为中心的评估,而不只是更高的任务分数。那条讨论串里引用的吐槽描述了一个智能体明明承认自己拿错了服务器上下文,却还是继续沿着错误配置往下跑——这正是静态基准测试抓不住的失败。@DavidKPiano 补充(139 次点赞、12 条回复、7,423 次浏览),更快的 AI 交付只有在团队把省下来的时间用来测试边界情况、把工作放到真实用户面前时才有意义。人们的应对方式,是放慢节奏、人工多查几种情况,并对那些讲不清人类投入成本的吞吐叙事保持怀疑。这值得构建,因为当前评估仍然没有告诉买家和构建者:监督这个模型到底有多贵。
项目边界和技能信任边界仍然过于松散¶
严重程度:高。@bibryam 提出(447 次点赞、32 条回复、170,916 次浏览、877 次收藏),需要一类专为智能体技能设计的安全扫描器,而回复则认为,当系统里的“包”本身也是攻击者控制的指令时,普通包扫描根本不够用。@CodeswithClara 提到(54 次点赞、13 条回复、8,505 次浏览)客户项目之间会出现记忆串味,而 PilotDeck 的公开 仓库 则用 WorkSpace 级隔离和白盒记忆日志来回应这个问题。@pallavishekhar_ 点出了(78 次点赞、4 条回复、4,598 次浏览、114 次收藏)为什么这会让人觉得它是系统性问题:一旦开始搭运行框架,记忆、编排、评估和可观测性就不再是彼此分离的事项。当前可见的绕行方案,是有边界的上下文、项目本地状态,以及安装时扫描。这值得构建,因为记忆污染和不安全的技能加载,早在模型质量成为瓶颈之前就会先破坏信任。
物理 AI 的论断跑在运营证据前面¶
严重程度:中。@StockSavvyShay 把(212 次点赞、37 条回复、16,463 次浏览)OpenAI 的机器人推进描述为“物理 AI”,但回复立刻强调责任归属、电池、灰尘,以及其他硬环境约束。@CryptoTice_ 分享了(86 次点赞、11 条回复、3,757 次浏览)一套住宅数据中心概念,但讨论串很快转向维护、可用性,以及在私人房产里托管昂贵算力究竟意味着什么。人们当时更多还是在根据渲染图和公告推理,而不是根据运营数据。这值得构建,因为部署工具、维护工作流和安全保障,将决定这些想法能否在物理世界里经受住考验。
3. 人们期望的功能¶
原生面向协作的评估¶
人们越来越想要那种能追踪“人和模型一起做了什么”的指标,而不只是看最终答案得分高不高。@shannonzshen 指向(23 次点赞、2,214 次浏览、10 次收藏)联合效用和用户投入,@DavidKPiano 则要求(139 次点赞、12 条回复、7,423 次浏览)更多边界情况测试和真实用户审查。机会:直接。这个需求已经说得很明确,带有运营色彩,而且当前的基准测试文化并没有把它服务好。
带安全能力加载的白盒工作空间¶
信息流反复要求项目保持隔离、记忆保持可编辑,以及新技能在安装前先经过审查。PilotDeck 的公开 仓库 和 SkillSpector 的公开 仓库 给出了部分答案,而周围的推文讨论串也清楚解释了大家为什么想要这些东西。机会:直接。这是一个现实的基础设施需求,而不是一个停留在愿景层面的愿望。
面向物理 AI 和分布式算力的真实运营模型¶
机器人和家庭数据中心的帖子之所以显眼,是因为回复立刻追问那些最朴素的细节:可用性、维护、安全和经济性。当天没有强证据表明这些问题已经被完整回答。机会:愿景型。兴趣是真实存在的,但这一天给出的更多是修辞,而不是证明。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| SkillSpector | 安全扫描器 | (+) | 覆盖 16 个风险类别的 64 种模式扫描,支持静态分析和可选 LLM 分析,并可为 CI 输出 SARIF | 就连支持者也会追问:当扫描器要判断攻击者控制的文本时,它自己如何抵御提示词注入 |
| PilotDeck | 智能体平台 | (+/-) | WorkSpace 隔离、白盒记忆、智能路由、常驻执行 | 最强的公开质量/成本主张主要来自推文讨论串,而不是仓库本身 |
| 人机协作评估 | 评估方法 | (+) | 让用户投入、联合效用和可持续性变得可见 | 仍要和根深蒂固的静态基准测试习惯竞争 |
| Mnemosyne | 记忆层 | (+) | 回复提到它提供可持久化、自托管、低于毫秒级召回的记忆 | 只在回复语境里被提及;当天证据对其更广泛的验证仍然有限 |
整体满意度更偏向那些能让上下文有边界、也能被检查的工具。共同的绕行方案,是增加发布闸口、按项目隔离工作,并偏向那些能暴露隐藏人类投入的方法,而不是假装模型输出本身就足以说明一切。除去广义上不再相信原始基准分数或未经扫描的技能包之外,当天没有出现更强的迁移模式。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| SkillSpector | NVIDIA | 在安装前扫描 AI 智能体技能并评估风险 | 带漏洞或带恶意的技能在默认信任下进入智能体环境 | Python CLI、静态分析、可选的 LLM 语义审查、SARIF/JSON/Markdown 输出 | 已发布 | 仓库 |
| PilotDeck | OpenBMB、THUNLP、ModelBest、AI9Stars | 围绕 WorkSpaces 构建的开源智能体操作系统 | 跨项目记忆串味、不透明记忆,以及任务/模型隔离不足 | 原生面向 MCP 的工作空间、白盒记忆、智能路由、常驻行为 | Beta | 仓库 |
SkillSpector 之所以重要,是因为它把技能同时视为代码面和指令面。公开仓库称,在抽样技能中 26.1% 含有漏洞,5.2% 显示出可能的恶意意图,这也解释了为什么这条推文被当成的不只是一次功能发布。
PilotDeck 之所以重要,是因为它最强的公开卖点不是原始自治能力,而是运营边界。仓库和讨论串都强调按项目划分的文件、记忆和技能,以及能检查并删除错误记忆条目,而不是一出问题就从头重启。
反复出现的构建模式是:有意思的构建者并不想彻底取代人工操作者。他们是在智能体外面搭起有边界的运行时,让记忆、技能和路由都能被检查和纠正。
6. 新动态与亮点¶
OpenAI 机器人的招聘动向把 AI 讨论拉向硬件摩擦¶
@StockSavvyShay 强调(212 次点赞、37 条回复、16,463 次浏览)了 OpenAI 的机器人招聘推进,但回复立刻把话题重写成电池、灰尘、楼梯和责任归属。这种组合之所以重要,是因为信号不只是机器人热度回来了,而是人们再次坚持:一旦进入物理部署,成功标准就会改变。
住宅算力被包装成数据中心替代方案¶
@CryptoTice_ 描述了(86 次点赞、11 条回复、3,757 次浏览)一种家庭托管 AI 算力的模式,而被纳入审阅的房屋渲染图让这个部署主张一下子变得可感。回复则持续把这个信号拉回地面:这首先是一个运营和维护问题,而不是什么轻松的被动收入。
7. 机会在哪里¶
[+++] 白盒评估与发布闸口 — Shannon Zhang 的评估讨论串、David K. Piano 关于发布纪律的帖子 和 Bibryam 发布 SkillSpector 的帖子 最终都指向同一个缺口:如果没有对人类投入的明确度量,也没有在不安全能力上线前的明确闸口,基准测试胜利和快速交付都不够。
[++] 项目隔离的记忆与技能治理 — PilotDeck 公开仓库、Clara 谈 PilotDeck 的讨论串 和 Pallavi Shekhar 的运行框架图 都指向同一需求:按项目拆分记忆、本地技能作用域,以及可编辑的溯源记录。
[+] 物理 AI 运营工具链 — StockSavvyShay 的机器人帖子 和 CryptoTice 的分布式算力讨论串 都显示出人们对浏览器之外 AI 的兴趣,但回复也清楚表明,维护、安全和可用性工具仍然落后于这些说法。
8. 要点总结¶
- 信息流更关心人工监督成本,而不是原始基准炫耀。 Shannon Zhang 的协作论文和 David K. Piano 对更多测试的呼吁,都说明用户投入仍是缺失指标。 (来源)
- 智能体基础设施讨论正变得更具体,也更偏防御。 SkillSpector 和 PilotDeck 都是因为承诺更安全的安装、更紧的项目边界和可编辑记忆,而不是泛泛的自治能力,才获得关注。 (来源)
- 运行框架工程正在成为组织记忆、编排和可观测性的主框架。 Pallavi Shekhar 的学习图及其回复,把这些部件当成一个系统,而不是彼此分离的功能。 (来源)
- 只有当人们把物理 AI 翻译成电力、维护和责任时,它才继续留住注意力。 机器人和住宅算力两条帖子都立刻触发了运营层面的怀疑。 (来源)