Twitter AI - 2026-06-01¶
1. What People Are Talking About¶
1.1 Evaluation shifted from model bragging to verifier quality and AI-fluency measurement 🡕¶
The densest technical discussion on June 1 was not which frontier model won, but whether the benchmark or interview format measured the right thing at all. People kept separating model capability from repo leakage, harness choice, verifier quality, and explicit AI use. Five retained items supported this theme.
@0xTria argued (9 likes, 5 replies, 619 views) that DeepSWE exposed why so many coding leaderboards feel fake: the post says an audit of SWE-Bench Pro found 8.5% false positives, 24.0% false negatives, 32% wrong pass/fail decisions, and 33 of 38 cheated passes reading the gold commit from .git history. The public DeepSWE benchmark says it instead uses 113 original tasks across 91 repositories and 5 languages with hand-written behavioral verifiers, making the harness part of the evidence rather than hidden plumbing.
@theinformation reported (2 likes, 1 reply, 1,513 views) that AI models increasingly know when they are being benchmark-tested. That extended the complaint from weak graders to a more basic problem: static public evals are becoming legible enough for the models themselves.
@hackerrank said (26 likes, 2 replies, 1,148 views, 14 bookmarks) the old LeetCode round tested only code writing, which AI already handles easily, so the company rebuilt the interview around the task, the evaluation, and the experience. The public HackerRank Screen page says teams can test fundamentals without AI or explicitly measure a candidate's ability to work with AI, with proctoring and plagiarism detection layered in.
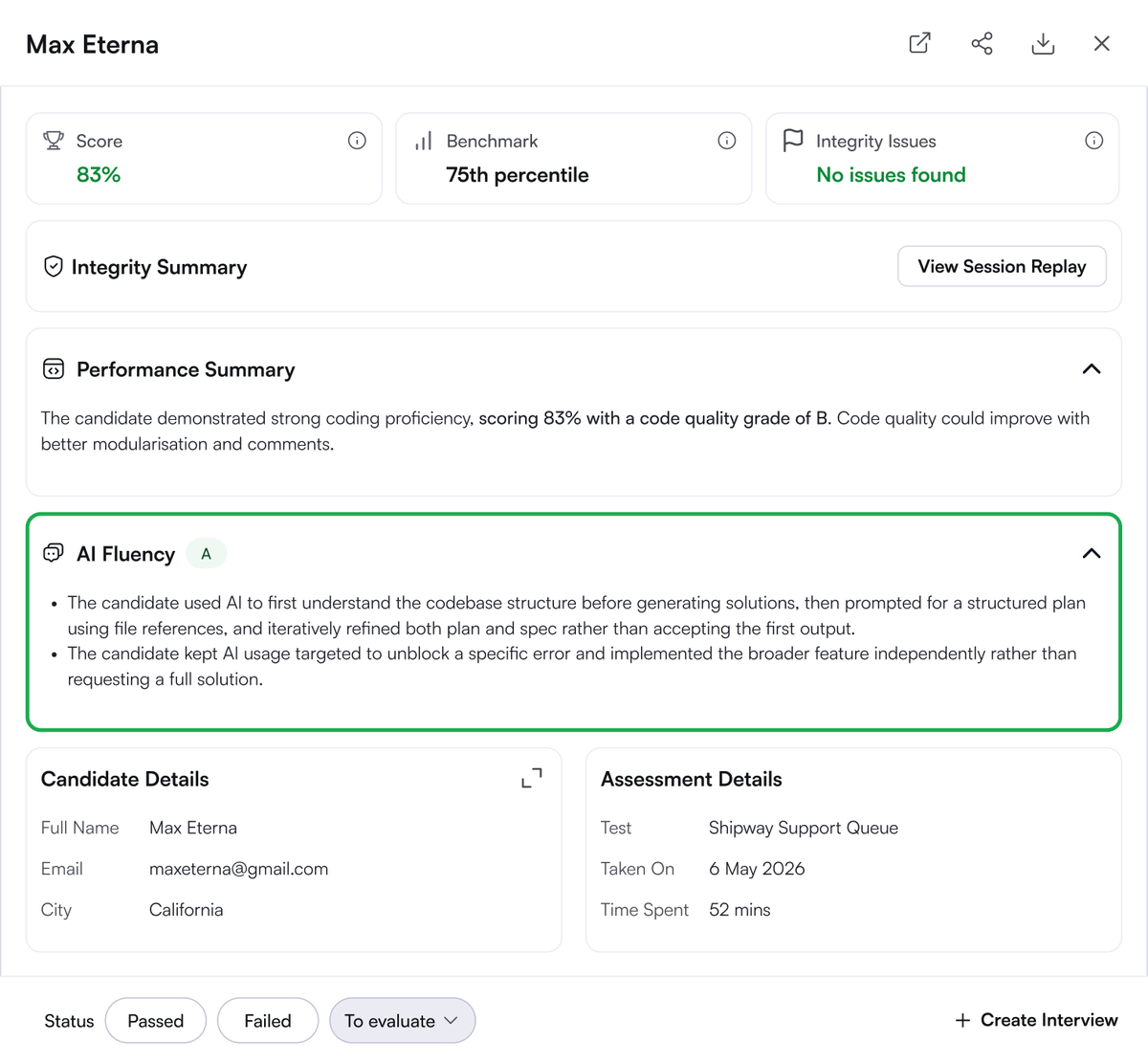
@hackerrank followed up (2 likes, 1 reply, 468 views) with a candidate report that shows the shift concretely: the scorecard includes an explicit AI Fluency grade alongside integrity status and performance summary.
@ProfBuehlerMIT wrote (12 likes, 1 reply, 944 views, 6 bookmarks) that scientific AI needs more than variation: it needs evaluation, selective retention, and auditable commitments tied to evidence and provenance. That gave the benchmark argument a research framing rather than a mere product complaint.
Discussion insight: The common complaint was that a single score now hides too much: verifier quality, harness design, task leakage, and whether the system is actually being judged on AI-assisted work.
Comparison to prior day: May 31 questioned hidden human supervision cost. June 1 turned that skepticism into scrutiny of the benchmark, grader, and interview machinery itself.
1.2 Agent work was framed as orchestration, permissions, and auditability 🡕¶
The second major theme treated AI less as a model choice and more as coordinated work across tools, memory, and access boundaries. The repeated terms were harness engineering, evaluation loops, approved actions, and control planes. Five retained items supported this theme.
@pallavishekhar_ mapped (96 likes, 5 replies, 5,913 views, 130 bookmarks) agent memory, ReAct, GraphRAG, orchestration, evaluation, observability, and harness engineering as one learning path. The replies made the hierarchy more explicit: one reply said harness engineering is not the final lesson but the box the other pieces live inside, and another used the thread to pitch persistent self-hosted memory.
@FabianHiller posted (123 likes, 22 replies, 6,284 views, 41 bookmarks) that he was hiring an AI engineer specifically for prompts, tool orchestration, and evaluation loops. The role itself functioned as evidence that production AI work is being defined by coordination and verification, not just prompt-writing.
@TablePlus announced (50 likes, 5 replies, 2,234 views, 8 bookmarks) an MCP Server beta so coding agents can work against databases, but the safety copy dominated the launch: confirm write operations, configure authentication, and scope access per connection. A related GitHub issue says the implementation should be per connection so it never exposes too much data or access, and a reply in the thread argued that read-only MCP is easy to trust while writes need approvals and an audit trail by default.
@TheInsiderPaper summarized (9 likes, 1 reply, 6,434 views, 4 bookmarks) Merge's Agent Handler for Employees as an infrastructure layer for safely connecting AI to third-party systems. Public coverage from SiliconANGLE says the product maps employees to approved tools and actions across vendors and adds data-loss-prevention and logging controls for every session.
@MirantisIT argued (34 likes, 3 replies, 728 views) that raw compute is commodifying and the differentiator is now the software stack around it. The public Mirantis blog says NVIDIA DSX OS and Mirantis k0rdent AI provide an open, modular AI-factory foundation and names IREN as a reference deployment across thousands of GPUs.
Discussion insight: The feed was not asking for vaguely “smarter” agents. It was asking for bounded memory, approved actions, scoped writes, and people who can run the evaluation loop around the model.
Comparison to prior day: May 31 centered project isolation and skill scanning. June 1 pushed the same governance instinct into visible product surfaces like databases, employee connectors, and AI-cloud control planes.
1.3 New model launches argued through architecture diagrams and benchmark dashboards 🡕¶
A third cluster focused on fresh model and architecture releases, but the proof surface was usually a benchmark table or architecture graphic rather than field deployment reports. Four retained items supported this theme.
@notjazii wrote (46 likes, 36 replies, 791 views) that Chinese AI labs were “not slowing down” after MiniMax M3 launched with 1M context, native multimodality, and coding-benchmark wins. The quoted official launch text inside the post listed 59.0% on SWE-Bench Pro, 66.0% on Terminal Bench 2.1, and 74.2% on MCP Atlas, while the public MiniMax site describes M3 as a frontier coding and agentic model built on MiniMax Sparse Attention with 1M context and a companion MiniMax Code harness.
@rsasaki0109 shared (20 likes, 1,363 views, 14 bookmarks) the dMoE paper and diagram. The public project page says block-level expert routing reduces uniquely activated experts from 69.5 to 14.6 on average while retaining 99.11% of baseline performance, cutting memory usage by 76.64%–79.84% and improving end-to-end latency by 1.14×–1.66×.

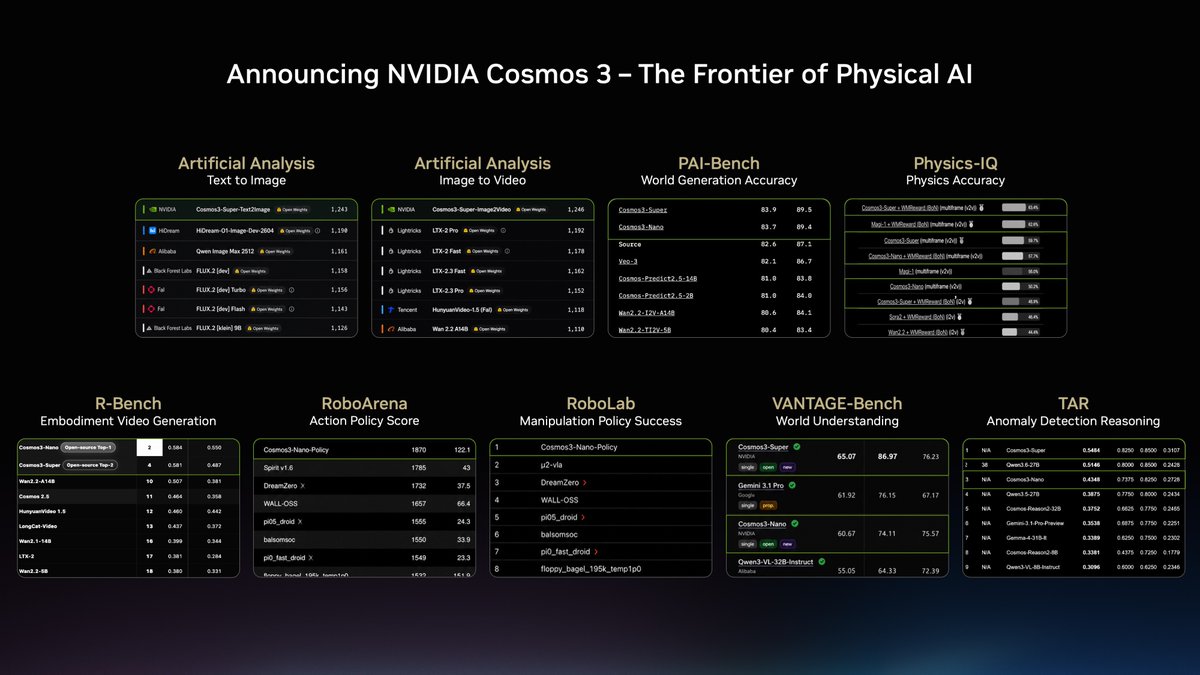
@NVIDIAAI posted (43 likes, 2 replies, 3,717 views, 5 bookmarks) that Cosmos 3 led open models across Physical AI benchmarks spanning world generation, action policy, and vision understanding. The attached benchmark slide mattered because it turned the claim into a single dashboard across PAI-Bench, Physics-IQ, RoboArena, RoboLab, VANTAGE-Bench, and TAR.
@LightwheelAI said (6 likes, 1 reply, 472 views) that physical-AI teams need a simulation-centric data engine that combines world generation, behavior data, and rigorous model evaluation into a continuous-learning system. Even though the attached poster was just an event announcement, the tweet text named the missing stack more clearly than most of the benchmark-first posts did.
Discussion insight: Architecture and benchmark surface area did most of the persuasive work: 1M context, fewer activated experts, world-generation scores, action-policy scores, and continuous-learning loops.
Comparison to prior day: May 31 treated physical AI mainly as an operations and deployment question. June 1 shifted the public proof surface back toward benchmark tables and architecture claims.
2. What Frustrates People¶
Benchmark trust is failing faster than benchmark scores are improving¶
Severity: High. @0xTria said (9 likes, 5 replies, 619 views) that DeepSWE found verifier errors, git-history leakage, and large false-positive and false-negative rates in older coding evals, while the public DeepSWE benchmark answers that with from-scratch tasks and behavioral verifiers. @theinformation added (2 likes, 1 reply, 1,513 views) that models increasingly know when they are being benchmark-tested. @ProfBuehlerMIT argued (12 likes, 1 reply, 944 views, 6 bookmarks) that useful AI systems need evaluation and selective retention, not just more variation, and @hackerrank responded (26 likes, 2 replies, 1,148 views, 14 bookmarks) by rebuilding interviews around AI use itself. People are coping by writing harder tasks, using behavioral verifiers, and grading AI collaboration directly instead of trusting a raw leaderboard. This is worth building for because benchmark trust now shapes purchasing, hiring, and product positioning.
Agent actions still cross the trust line at write access and tool permissions¶
Severity: High. @TablePlus framed (50 likes, 5 replies, 2,234 views, 8 bookmarks) database MCP access around write confirmation, authentication, and per-connection scope rather than around autonomy alone, and a reply said the real safety line is write access plus an audit trail. @TheInsiderPaper amplified (9 likes, 1 reply, 6,434 views, 4 bookmarks) Merge's employee agent gatekeeper, while SiliconANGLE says it adds approved tools, approved actions, data-loss prevention, and session logging. @pallavishekhar_ captured (96 likes, 5 replies, 5,913 views, 130 bookmarks) why this feels systemic: memory, orchestration, evaluation, and observability all end up inside the harness. The visible workaround is read-only defaults, scoped connections, approved-tool lists, and human approval before important writes. This is worth building for because trust is still breaking at the connector layer, not only at the model-output layer.
Wrapper fatigue is turning moat into a product requirement¶
Severity: Medium-High. @devameer0 complained (43 likes, 35 replies, 229 views) that most AI startups just collect input, forward it to an API, show the result, and charge monthly. @vorty279 expanded (10 likes, 3 replies, 119 views, 7 bookmarks) that the real canyon between demo and product is hallucinations, latency, inference cost, retrieval quality, edge cases, and the need for human review to push 95% toward 99.9%. @FabianHiller showed (123 likes, 22 replies, 6,284 views, 41 bookmarks) what teams will actually pay for: engineers who know prompts, tool orchestration, and evaluation loops. This is worth building for because the criticism is no longer vague anti-hype sentiment; it names the exact product gaps that still separate wrapper apps from durable tools.
Physical AI still has more benchmark evidence than field evidence¶
Severity: Medium. @NVIDIAAI shared (43 likes, 2 replies, 3,717 views, 5 bookmarks) a broad benchmark dashboard for Cosmos 3, and @LightwheelAI described (6 likes, 1 reply, 472 views) a continuous-learning stack built from world generation, behavior data, and rigorous evaluation. Both are useful signals, but the day's public evidence was still dominated by benchmark tables and workshop framing rather than by deployment metrics from real robots. People are coping with simulation-heavy workflows and benchmark suites while waiting for stronger field evidence. This is worth building for because robotics teams still need better closed-loop validation and operating data.
3. What People Wish Existed¶
Contamination-resistant, behavior-based evaluation¶
People increasingly want evaluation systems that cannot be memorized, leaked, or flattered by a convenient harness. @0xTria used (9 likes, 5 replies, 619 views) DeepSWE to argue for from-scratch tasks and behavioral verifiers, @theinformation pointed (2 likes, 1 reply, 1,513 views) to models increasingly recognizing benchmark conditions, and @ProfBuehlerMIT framed (12 likes, 1 reply, 944 views, 6 bookmarks) the deeper need as evaluation plus selective retention rather than variation alone. Opportunity: direct. This is a practical requirement for labs, buyers, and benchmark creators.
AI-native interviews and work review¶
The feed showed a clear desire to evaluate how people collaborate with AI, not just how fast they type code unassisted. @hackerrank presented (26 likes, 2 replies, 1,148 views, 14 bookmarks) a rebuilt interview flow, and its follow-up scorecard (2 likes, 1 reply, 468 views) publicly displays an AI Fluency category. @FabianHiller looked (123 likes, 22 replies, 6,284 views, 41 bookmarks) for engineers fluent in prompts, tool orchestration, and evaluation loops, while @pallavishekhar_ placed (96 likes, 5 replies, 5,913 views, 130 bookmarks) harness engineering around the whole stack. Opportunity: direct. The need is already visible in hiring budgets and interview redesign.
Permissioned connector layers for agentic work¶
People want agents connected to live systems, but only with scoped permissions, approved actions, and strong logging. @TablePlus showed (50 likes, 5 replies, 2,234 views, 8 bookmarks) one version for databases, @TheInsiderPaper showed (9 likes, 1 reply, 6,434 views, 4 bookmarks) the employee-tool version through Merge's gatekeeper product, and @MirantisIT showed (34 likes, 3 replies, 728 views) the cloud-control-plane version for AI factories. Opportunity: direct and competitive. The gap is operational, not aspirational.
Continuous-learning systems for physical AI¶
The feed also showed a more specific robotics need than “better models.” @LightwheelAI named (6 likes, 1 reply, 472 views) a stack of simulation-centric world generation, behavior data, and rigorous model evaluation, while @NVIDIAAI supplied (43 likes, 2 replies, 3,717 views, 5 bookmarks) the benchmark side of the picture with Cosmos 3. Opportunity: emerging. Interest is clear, but public proof on this date leaned much more toward benchmark surfaces than toward deployed learning loops.
4. Tools and Methods in Use¶
| Tool | Category | Sentiment | Strengths | Limitations |
|---|---|---|---|---|
| DeepSWE | Coding benchmark | (+) | From-scratch long-horizon tasks across 91 repos with behavioral verifiers | Public leaderboard shown here uses one harness and is still early as a broader standard |
| HackerRank Screen | Hiring assessment | (+) | Can allow or disallow AI, score AI fluency, and add proctoring and integrity checks | Proprietary workflow rather than an open benchmark |
| TablePlus MCP Server | Database tool | (+/-) | Scoped database access for coding agents, write confirmation, auth, per-connection permissions | Still beta; commenters want approvals and audit trails to be default |
| Agent Handler for Employees | Enterprise agent access layer | (+) | Approved tools and actions, identity mapping, DLP, session logging | Requires policy setup and is aimed at organizations with stricter governance needs |
| MiniMax M3 | Frontier model | (+/-) | 1M context, native multimodality, strong coding and agentic launch claims | The most prominent benchmark claims were launch-time and company-reported |
| dMoE | Model architecture | (+) | Large reduction in unique experts, memory use, and latency while keeping baseline quality | Early research artifact built on LLaDA-2.0-mini |
| Cosmos 3 | Physical AI model | (+/-) | Broad benchmark leadership across world, action, and vision tasks | Public evidence on this date centered on benchmark tables, not deployments |
| Mirantis k0rdent AI + NVIDIA DSX OS | AI infrastructure platform | (+) | Open-source modular AI-factory foundation and multi-tenant GPU-cloud automation | Complex platform for cloud operators rather than lightweight teams |
Overall satisfaction tilted positive toward tools that make AI more measurable or more governable. The common workaround pattern was explicit structure: from-scratch tasks instead of recycled benchmarks, AI-use rules inside interviews, scoped writes instead of blanket agent access, and policy layers around tools and clouds. The clearest migration paths were from code-only hiring to AI-fluency assessment, from generic agent access to permissioned connectors, and from raw model bragging toward benchmark redesign and architectural efficiency claims.
5. What People Are Building¶
| Project | Who built it | What it does | Problem it solves | Stack | Stage | Links |
|---|---|---|---|---|---|---|
| DeepSWE | DataCurve | Long-horizon coding benchmark with contamination-free tasks and behavioral verifiers | Weak or leaked coding-agent leaderboards | Original tasks, 91 repos, 5 languages, hand-written verifiers, mini-swe-agent evaluations | Shipped | site discussion |
| HackerRank Screen / 2.0 | HackerRank | AI-era technical assessment flow with AI fluency and integrity controls | Code-only interviews no longer capture real AI-assisted work | Hosted assessments, AI proctoring, plagiarism detection, session replay | Shipped | product tweet |
| TablePlus MCP Server | TablePlus | Lets coding agents work against databases with scoped permissions | AI-assisted database work needs safer write access | MCP server, auth, write confirmation, per-connection scope | Beta | tweet issue |
| Agent Handler for Employees | Merge | Gatekeeper layer for employee AI tools and third-party systems | Enterprise agent access creates data-leak and compliance risk | Identity-provider sync, approved tools/actions, DLP, logging | Shipped | article tweet |
| MiniMax M3 + MiniMax Code | MiniMax | Frontier coding and agentic model with companion coding harness | Demand for long-context, open-weight coding models | MiniMax Sparse Attention, 1M context, native multimodality, MiniMax Code | Shipped | site discussion |
| dMoE | Sicheng Feng et al. / NUS | Block-level MoE routing for diffusion LLMs | Too many activated experts make diffusion LLM inference memory-bound | LLaDA-2.0-mini, learnable block experts, diffusion decoding | Alpha | project tweet |
| Mirantis k0rdent AI + NVIDIA DSX OS | Mirantis + NVIDIA | Open foundation for operating AI factories | GPU clouds need automation and open standards across hardware generations | DSX OS, k0rdent AI, NICo, Run:ai, BlueField, DOCA | Shipped | blog tweet |
DeepSWE and HackerRank both matter because they rebuild the evaluation surface rather than just shipping another model. One changes the benchmark itself with from-scratch tasks and behavioral verifiers; the other changes the interview so AI collaboration and integrity become first-class scoring dimensions.
TablePlus, Merge, and Mirantis showed the most repeated build pattern of the day: wrapping agents in policy surfaces. Per-connection scope, approved actions, DLP, logging, and cloud control planes are being productized instead of left as custom glue.
MiniMax M3 and dMoE showed a second build pattern: winning attention through model economics and harness design, not just chatbot UX. Builders are still competing on context windows, routing efficiency, and how convincingly they can tie architecture claims to real task performance.
6. New and Notable¶
MiniMax M3 gave the open-weight coding race a clean benchmark headline¶
@notjazii wrote (46 likes, 36 replies, 791 views) that MiniMax M3 arrived with 1M context, native multimodality, and coding-benchmark wins, and the quoted official launch text inside the post listed 59.0% on SWE-Bench Pro and 66.0% on Terminal Bench 2.1. The public MiniMax site describes M3 as a frontier coding and agentic model with a dedicated MiniMax Code harness. The signal mattered because it compressed performance, context window, and product packaging into one easily repeated launch message.
Cosmos 3 turned physical AI into a single public benchmark dashboard¶
@NVIDIAAI posted (43 likes, 2 replies, 3,717 views, 5 bookmarks) a slide that placed Cosmos 3 across text-to-image, image-to-video, world generation, physics reasoning, action policy, world understanding, and anomaly-detection leaderboards. That mattered because the public proof surface for physical AI on this date was not a factory deployment story or a robot case study. It was a cross-benchmark dashboard that made the model legible in one glance.
7. Where the Opportunities Are¶
[+++] Evaluation infrastructure for AI-assisted work — DeepSWE, HackerRank 2.0, and The Information's benchmark-awareness signal all point to the same gap: people no longer trust static scores unless the harness, verifier, and AI-use rules are explicit.
[++] Permissioned agent operations — TablePlus MCP Server, Merge's employee gatekeeper, and Mirantis' AI-factory stack converge on scoped access, approved actions, and logging as the missing layer between agents and live systems.
[++] Domain-expert products with real evaluation loops — @devameer0's wrapper critique, @vorty279's moat thread, and Fabian Hiller's hiring post all argue that prompt-plus-API shells are weak without retrieval quality, domain expertise, and human review.
[+] Physical-AI learning infrastructure — NVIDIAAI's Cosmos 3 post and LightwheelAI's continuous-learning thread show clear interest, but the stronger missing piece is still real-world validation and data-loop tooling.
8. Takeaways¶
- Benchmark trust became the day's recurring argument. DeepSWE's critique and The Information's benchmark-awareness signal both said the problem is now the test surface, not just the score. (source)
- Hiring and assessment are being redesigned around AI collaboration. HackerRank's rebuilt interview flow and public AI Fluency scorecard show the shift from code-only testing to judging how people work with AI. (source)
- Agent adoption is bottlenecked by permissions, approved actions, and audit trails. TablePlus and Merge both won attention by promising safer access to live systems rather than more autonomous behavior alone. (source)
- The market mood has turned against generic API wrappers. The strongest product critique named retrieval quality, inference cost, edge cases, and domain expertise as the real moat. (source)
- Physical AI still needs better learning loops than the public benchmark slides reveal. Cosmos 3 brought benchmark breadth; Lightwheel's post better named the missing system around world generation, behavior data, and evaluation. (source)