Twitter AI - 2026-06-01¶
1. 人们在讨论什么¶
1.1 评估焦点从模型炫耀转向验证器质量与 AI 素养测量 🡕¶
6 月 1 日技术密度最高的讨论,不是哪一个前沿模型赢了,而是基准测试或面试形式到底有没有测到真正该测的东西。大家不断把模型能力,与仓库泄漏、运行框架选择、验证器质量,以及是否明确允许 AI 使用这几件事分开来看。至少有 5 条保留条目支撑这一主题。
@0xTria 认为(9 次点赞、5 条回复、619 次浏览),DeepSWE 暴露了为什么那么多编程排行榜看起来像假的。帖子称,对 SWE-Bench Pro 的一次审计发现 8.5% 的假阳性、24.0% 的假阴性和 32% 的错误通过/失败判定;38 个作弊通过案例里还有 33 个是靠读取 .git 历史中的金标准提交蒙混过关。公开的 DeepSWE 基准测试 称,它改用覆盖 91 个仓库、5 种语言的 113 个原创任务,并配套手写的行为验证器,让运行框架本身也成为证据的一部分,而不是被藏起来的底层管线。
@theinformation 报道称(2 次点赞、1 条回复、1,513 次浏览),AI 模型越来越知道自己什么时候正在接受基准测试。这把抱怨从“评分器不行”又往前推了一层:静态公开评估已经显眼到连模型自己都能认出来。
@hackerrank 表示(26 次点赞、2 条回复、1,148 次浏览、14 次收藏),旧式 LeetCode 环节只测试写代码,而 AI 早就能轻松处理这件事,所以公司围绕任务本身、评估方式和整体体验重做了面试流程。公开的 HackerRank Screen 页面 称,团队既可以在不允许 AI 的情况下测试基础能力,也可以明确测量候选人与 AI 协作的能力,并叠加监考和抄袭检测。
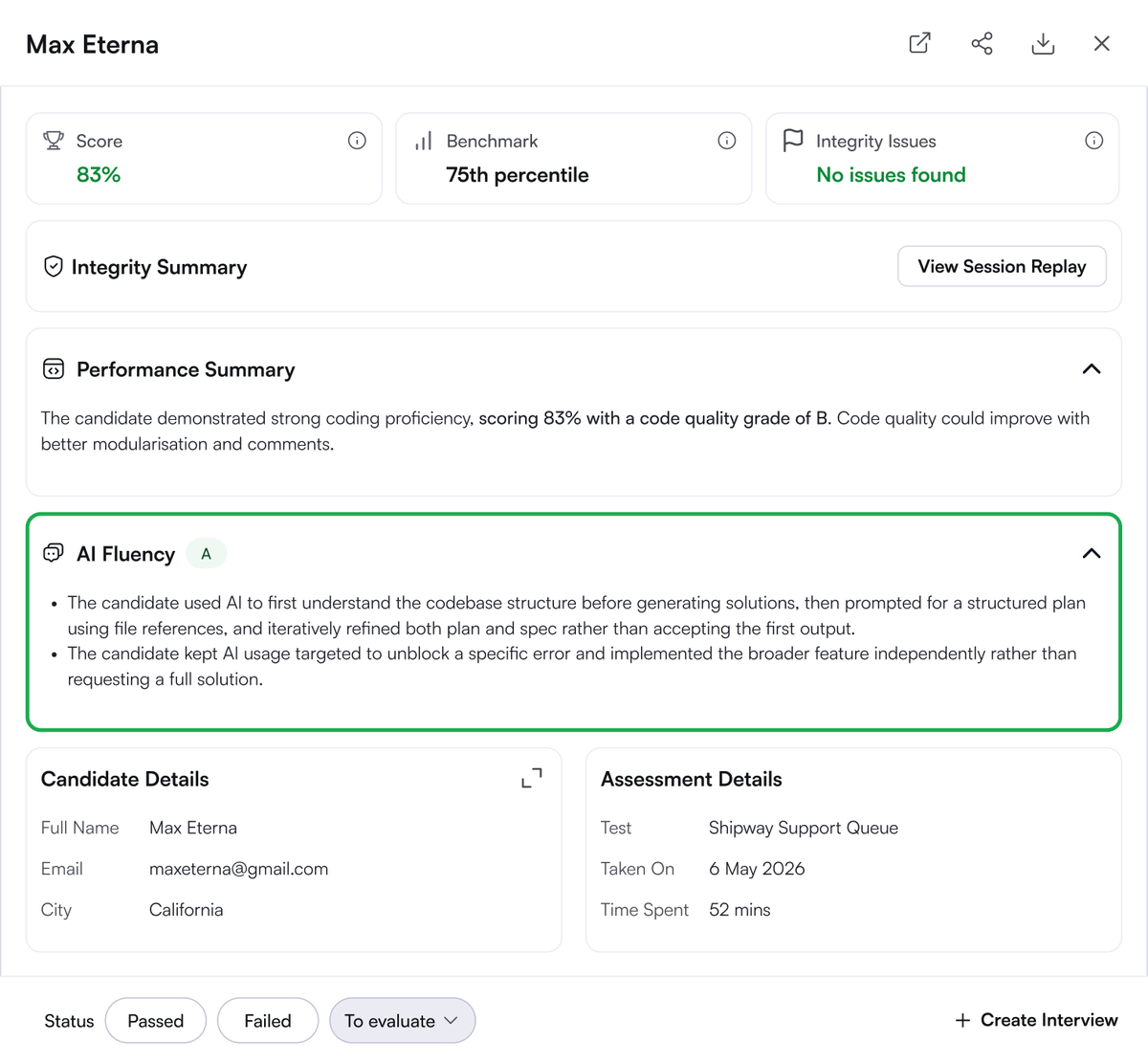
@hackerrank 随后又发(2 次点赞、1 条回复、468 次浏览)一张候选人报告,把这种转向具体化了:评分卡里明确加入了 AI 素养等级,同时还有诚信状态和表现摘要。
@ProfBuehlerMIT 写道(12 次点赞、1 条回复、944 次浏览、6 次收藏),科学领域的 AI 需要的不只是变化多样性;它还需要评估、选择性保留,以及与证据和溯源绑定、可审计的承诺。这让基准测试之争多了一层研究框架,而不只是产品层面的抱怨。
讨论要点: 大家的共同抱怨是,如今一个单一分数已经掩盖了太多东西:验证器质量、运行框架设计、任务泄漏,以及系统到底是不是在按 AI 辅助工作来接受评判。
与前日对比: 5 月 31 日质疑的是被隐藏起来的人工监督成本。6 月 1 日则把这种怀疑转成了对基准测试、评分器和面试机制本身的审视。
1.2 智能体工作开始围绕编排、权限和可审计性展开 🡕¶
第二个主要主题把 AI 看得更不像模型选择,更多像跨工具、记忆和访问边界的协同工作。反复出现的词是运行框架工程、评估闭环、已批准动作,以及控制平面。至少有 5 条保留条目支撑这一主题。
@pallavishekhar_ 把(96 次点赞、5 条回复、5,913 次浏览、130 次收藏)智能体记忆、ReAct、GraphRAG、编排、评估、可观测性和运行框架工程串成一条学习路径。回复把层级关系说得更明确:一条回复说运行框架工程不是最后一课,而是承载其他部分的容器;另一条则借这个讨论串推荐了可持久化的自托管记忆。
@FabianHiller 发帖称(123 次点赞、22 条回复、6,284 次浏览、41 次收藏),他正在招聘一名 AI 工程师,专门负责提示词、工具编排和评估闭环。这个职位本身就说明,生产级 AI 工作的定义正在变成协调与验证,而不只是写提示词。
@TablePlus 宣布(50 次点赞、5 条回复、2,234 次浏览、8 次收藏),推出 MCP Server Beta,让编程智能体可以直接操作数据库,但发布内容里最突出的还是安全描述:确认写操作、配置身份验证,并按连接划定访问范围。配套的 GitHub 议题 称,这套机制应该按连接生效,避免暴露过多数据或权限;讨论串里还有一条回复认为,只读 MCP 很容易建立信任,但涉及写入时,默认就该带审批和审计轨迹。
@TheInsiderPaper 概括(9 次点赞、1 条回复、6,434 次浏览、4 次收藏),Merge 的 Agent Handler for Employees 是一层用来把 AI 安全连接到第三方系统的基础设施。来自 SiliconANGLE 的公开报道称,这个产品会把员工映射到跨供应商的已批准工具和动作上,并为每一次会话加入数据泄露防护和日志控制。
@MirantisIT 认为(34 次点赞、3 条回复、728 次浏览),原始算力正在商品化,真正的差异点已经变成围绕它的软件栈。公开的 Mirantis 博文 称,NVIDIA DSX OS 和 Mirantis k0rdent AI 提供了一个开放、模块化的 AI 工厂基础,并把 IREN 列为跨数千张 GPU 的参考部署。
讨论要点: 信息流要的不是模糊意义上更“聪明”的智能体,而是边界清楚的记忆、已批准动作、受限写权限,以及能把评估闭环跑起来的人。
与前日对比: 5 月 31 日强调项目隔离和技能扫描。6 月 1 日则把同样的治理直觉推进到了数据库、员工连接器和 AI 云控制平面这些可见产品界面上。
1.3 新模型发布主要靠架构图和基准看板来论证 🡕¶
第三个讨论簇聚焦在新模型和新架构发布上,但公开证据通常是一张基准测试表或架构图,而不是现场部署报告。至少有 4 条保留条目支撑这一主题。
@notjazii 写道(46 次点赞、36 条回复、791 次浏览),MiniMax M3 发布后,中国 AI 实验室“没有放慢下来”,它同时带来了 1M 上下文、原生多模态,以及编程基准测试胜利。帖子里引用的官方发布文案列出了 SWE-Bench Pro 59.0%、Terminal Bench 2.1 66.0% 和 MCP Atlas 74.2%,而公开的 MiniMax 网站 则把 M3 描述成基于 MiniMax Sparse Attention、拥有 1M 上下文,并配套 MiniMax Code 运行框架的前沿编程与智能体模型。
@rsasaki0109 分享(20 次点赞、1,363 次浏览、14 次收藏)了 dMoE 论文和配图。公开的 项目页 称,块级专家路由把平均独立激活专家数从 69.5 降到 14.6,同时保留 99.11% 的基线性能,把内存占用降低 76.64%–79.84%,并把端到端延迟改善到 1.14×–1.66×。

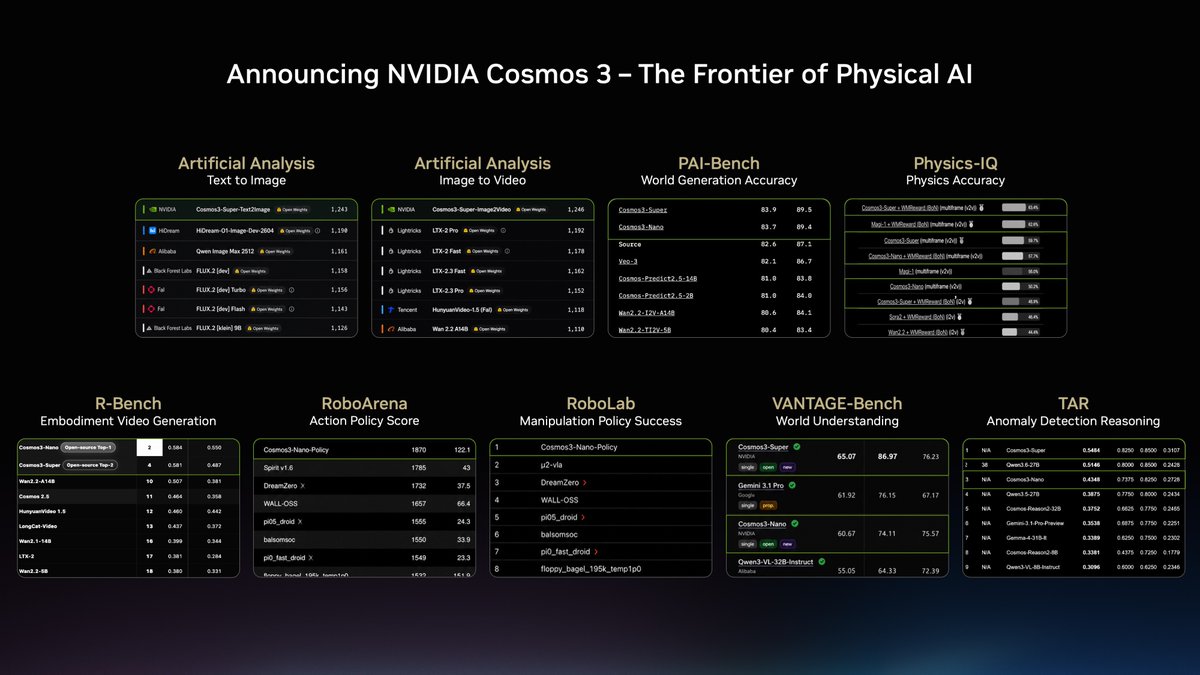
@NVIDIAAI 发帖称(43 次点赞、2 条回复、3,717 次浏览、5 次收藏),Cosmos 3 在覆盖世界生成、动作策略和视觉理解的物理 AI 基准测试上领跑开放模型。附带的基准测试幻灯片之所以重要,是因为它把这一主张压缩成了一张横跨 PAI-Bench、Physics-IQ、RoboArena、RoboLab、VANTAGE-Bench 和 TAR 的单页看板。
@LightwheelAI 表示(6 次点赞、1 条回复、472 次浏览),物理 AI 团队需要一套以仿真为中心的数据引擎,把世界生成、行为数据和严格的模型评估组合进一个持续学习系统。尽管配图只是一张活动海报,但这条推文本身比大多数先讲基准的帖子更清楚地点出了缺失的技术栈。
讨论要点: 架构和基准测试的展示面承担了大部分说服工作:1M 上下文、更少的激活专家、更高的世界生成分数、动作策略分数,以及持续学习闭环。
与前日对比: 5 月 31 日主要把物理 AI 当作运营和部署问题来谈。6 月 1 日则把公开证明面重新拉回了基准测试表和架构主张。
2. 令人困扰的问题¶
基准测试信任流失得比基准分数提升还快¶
严重程度:高。@0xTria 说(9 次点赞、5 条回复、619 次浏览),DeepSWE 在较旧的编程评估里发现了验证器错误、git 历史泄漏,以及大规模假阳性和假阴性,而公开的 DeepSWE 基准测试 则用从零编写的任务和行为验证器来回应这些问题。@theinformation 补充(2 次点赞、1 条回复、1,513 次浏览),模型越来越知道自己什么时候在接受基准测试。@ProfBuehlerMIT 认为(12 次点赞、1 条回复、944 次浏览、6 次收藏),有用的 AI 系统需要评估和选择性保留,而不只是更多变化;@hackerrank 则用(26 次点赞、2 条回复、1,148 次浏览、14 次收藏)围绕 AI 使用本身重做面试来回应。人们的应对方式,是编写更难的任务、使用行为验证器,并直接给 AI 协作打分,而不是继续相信一张裸排行榜。这值得构建,因为基准测试信任如今已经影响采购、招聘和产品定位。
智能体行动一到写权限和工具权限就越过信任线¶
严重程度:高。@TablePlus 把(50 次点赞、5 条回复、2,234 次浏览、8 次收藏)数据库 MCP 访问的重点放在写入确认、身份验证和按连接划定范围上,而不是只谈自治;一条回复更直说,真正的安全分界线就是写权限加审计轨迹。@TheInsiderPaper 放大了(9 次点赞、1 条回复、6,434 次浏览、4 次收藏)Merge 的员工智能体把关层,而 SiliconANGLE 称它加入了已批准工具、已批准动作、数据泄露防护和会话日志。@pallavishekhar_ 点出了(96 次点赞、5 条回复、5,913 次浏览、130 次收藏)为什么这让人感觉它是系统性问题:记忆、编排、评估和可观测性最后都会落进运行框架里。当前看得见的绕行方案,是默认只读、按范围限定连接、维护已批准工具清单,并在重要写入前要求人工批准。这值得构建,因为信任现在首先断在连接层,而不只是模型输出层。
套壳疲劳正在把护城河变成产品硬要求¶
严重程度:中高。@devameer0 抱怨(43 次点赞、35 条回复、229 次浏览),大多数 AI 创业公司只是收集输入、转发给 API、展示结果,然后按月收费。@vorty279 进一步展开(10 次点赞、3 条回复、119 次浏览、7 次收藏),demo 和产品之间真正的大峡谷是幻觉、延迟、推理成本、检索质量、边界情况,以及要把 95% 推到 99.9% 所需的人类复审。@FabianHiller 展示了(123 次点赞、22 条回复、6,284 次浏览、41 次收藏)团队真正愿意为之付费的东西:懂提示词、工具编排和评估闭环的工程师。这值得构建,因为这种批评已经不再是模糊的反炒作情绪,而是点名了那些仍让套壳应用和长期可用工具分开的具体产品缺口。
物理 AI 仍然是基准证据多于现场证据¶
严重程度:中。@NVIDIAAI 分享(43 次点赞、2 条回复、3,717 次浏览、5 次收藏)了一张 Cosmos 3 的宽基准测试看板,而 @LightwheelAI 描述(6 次点赞、1 条回复、472 次浏览)了一套由世界生成、行为数据和严格评估组成的持续学习栈。两者都是有用信号,但当天的公开证据仍主要被基准测试表和研讨会式表述主导,而不是来自真实机器人的部署指标。人们目前靠重仿真工作流和基准测试套件来推进,同时等待更强的现场证据。这值得构建,因为机器人团队仍然需要更好的闭环验证和运营数据。
3. 人们期望的功能¶
抗污染、基于行为的评估¶
人们越来越想要那种不会因为记忆、泄漏或讨巧运行框架而失真的评估系统。@0xTria 借助 DeepSWE 主张从零编写任务和行为验证器,@theinformation 指出模型越来越能识别基准测试条件,而 @ProfBuehlerMIT 把更深层的需求定义为评估加选择性保留,而不只是变化本身。机会:直接。这是实验室、买家和基准测试创建者都面临的现实要求。
AI 原生面试与工作评审¶
信息流清楚表明,人们想评估的是“人如何与 AI 协作”,而不只是“人在没有辅助时敲代码有多快”。@hackerrank 展示了(26 次点赞、2 条回复、1,148 次浏览、14 次收藏)一套重做后的面试流程,而后续那张 评分卡(2 次点赞、1 条回复、468 次浏览)则公开显示了 AI 素养这一栏。@FabianHiller 在招(123 次点赞、22 条回复、6,284 次浏览、41 次收藏)熟悉提示词、工具编排和评估闭环的工程师,而 @pallavishekhar_ 则把(96 次点赞、5 条回复、5,913 次浏览、130 次收藏)运行框架工程放在整条技术栈的外围。机会:直接。招聘预算和面试重设计已经让这个需求显了形。
面向智能体工作的权限化连接层¶
人们想让智能体接入在线系统,但前提是权限有范围、动作已获批准,而且日志足够强。@TablePlus 展示了数据库场景下的一种做法,@TheInsiderPaper 通过 Merge 的把关产品展示了员工工具场景,而 @MirantisIT 展示了面向 AI 工厂的云控制平面版本。机会:直接且竞争激烈。缺口是运营层面的,不是愿景层面的。
面向物理 AI 的持续学习系统¶
信息流还显露出一种比“更好的模型”更具体的机器人需求。@LightwheelAI 点名了以仿真为中心的世界生成、行为数据和严格模型评估这套栈,而 @NVIDIAAI 则给出了 Cosmos 3 的基准测试侧证。机会:新兴。兴趣很明确,但在这一天的公开证明里,基准测试展示面明显强于已部署的学习闭环。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| DeepSWE | 编程基准测试 | (+) | 从零编写的长时程任务覆盖 91 个仓库,并配有行为验证器 | 这里展示的公开排行榜只用了一个运行框架,离更广泛标准还早 |
| HackerRank Screen | 招聘评估 | (+) | 可允许或禁止 AI、给 AI 素养打分,并加入监考和诚信检查 | 属于专有工作流,不是开放基准测试 |
| TablePlus MCP Server | 数据库工具 | (+/-) | 为编程智能体提供带范围限制的数据库访问、写入确认、身份验证和按连接权限控制 | 仍处于 Beta;评论者希望审批和审计轨迹默认开启 |
| Agent Handler for Employees | 企业智能体访问层 | (+) | 已批准的工具和动作、身份映射、DLP、会话日志 | 需要策略配置,更适合治理要求严格的组织 |
| MiniMax M3 | 前沿模型 | (+/-) | 1M 上下文、原生多模态,在编程和智能体场景的发布主张很强 | 最醒目的基准测试主张主要来自发布时间和公司自报 |
| dMoE | 模型架构 | (+) | 在保持基线质量的同时,大幅减少独立专家数、内存占用和延迟 | 仍是构建在 LLaDA-2.0-mini 上的早期研究产物 |
| Cosmos 3 | 物理 AI 模型 | (+/-) | 在世界、动作和视觉任务上的基准覆盖面广且排名领先 | 当天的公开证据主要还是基准测试表,而不是部署案例 |
| Mirantis k0rdent AI + NVIDIA DSX OS | AI 基础设施平台 | (+) | 开源、模块化的 AI 工厂基础,以及多租户 GPU 云自动化 | 面向云运营商的复杂平台,不适合轻量团队 |
整体满意度更偏向那些能让 AI 更可测量或更可治理的工具。共同的绕行模式,是加入显式结构:从零任务取代重复利用的基准测试、在面试里明确 AI 使用规则、用受限写入替代一刀切的智能体访问,以及在工具和云之上再加一层策略控制。最清晰的迁移路径,是从只看代码的招聘转向 AI 素养评估,从泛化智能体接入转向权限化连接器,再从原始模型炫耀转向基准测试重设计和架构效率主张。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| DeepSWE | DataCurve | 带无污染任务和行为验证器的长时程编程基准测试 | 脆弱或已泄漏的编程智能体排行榜 | 原创任务、91 个仓库、5 种语言、手写验证器、mini-swe-agent 评测 | 已发布 | 网站 讨论 |
| HackerRank Screen / 2.0 | HackerRank | 带 AI 素养和诚信控制的 AI 时代技术测评流程 | 只看代码的面试已经无法覆盖真实的 AI 辅助工作 | 托管式测评、AI 监考、抄袭检测、会话回放 | 已发布 | 产品页 推文 |
| TablePlus MCP Server | TablePlus | 让编程智能体以受限权限操作数据库 | AI 辅助数据库工作需要更安全的写权限 | MCP Server、身份验证、写入确认、按连接划定范围 | Beta | 推文 议题 |
| Agent Handler for Employees | Merge | 面向员工 AI 工具和第三方系统的把关层 | 企业级智能体接入会带来数据泄露和合规风险 | 身份提供商同步、已批准的工具/动作、DLP、日志 | 已发布 | 文章 推文 |
| MiniMax M3 + MiniMax Code | MiniMax | 带配套编程运行框架的前沿编程与智能体模型 | 市场需要长上下文、开放权重的编程模型 | MiniMax Sparse Attention、1M 上下文、原生多模态、MiniMax Code | 已发布 | 网站 讨论 |
| dMoE | Sicheng Feng et al. / NUS | 面向扩散 LLM 的块级 MoE 路由 | 过多激活专家让扩散 LLM 推理受内存限制 | LLaDA-2.0-mini、可学习块专家、扩散解码 | Alpha | 项目 推文 |
| Mirantis k0rdent AI + NVIDIA DSX OS | Mirantis + NVIDIA | 面向 AI 工厂运营的开放基础 | GPU 云需要跨硬件代际的自动化和开放标准 | DSX OS、k0rdent AI、NICo、Run:ai、BlueField、DOCA | 已发布 | 博文 推文 |
DeepSWE 和 HackerRank 都重要,因为它们重建的是评估层,而不是再发一个模型。前者通过从零编写的任务和行为验证器改造了基准测试本身;后者则重做了面试,让 AI 协作和诚信成为一等评分维度。
TablePlus、Merge 和 Mirantis 展示了当天反复出现得最多的构建模式:把智能体包进策略表面。按连接划定范围、已批准动作、DLP、日志,以及云控制平面,正在被产品化,而不是继续留在定制胶水层。
MiniMax M3 和 dMoE 则展示了第二种构建模式:靠模型经济性和运行框架设计吸引注意力,而不只是靠聊天机器人式 UX。构建者仍在围绕上下文窗口、路由效率,以及能否把架构主张有说服力地连到真实任务表现上来竞争。
6. 新动态与亮点¶
MiniMax M3 为开放权重编程赛道打出了醒目的基准成绩¶
@notjazii 写道(46 次点赞、36 条回复、791 次浏览),MiniMax M3 带着 1M 上下文、原生多模态和编程基准测试胜利登场,而帖子里引用的官方发布文案列出了 SWE-Bench Pro 59.0% 和 Terminal Bench 2.1 66.0%。公开的 MiniMax 网站 把 M3 描述成一款前沿编程与智能体模型,并配有专用的 MiniMax Code 运行框架。这个信号之所以重要,是因为它把性能、上下文窗口和产品包装压缩进了一句很容易复述的发布信息。
Cosmos 3 把物理 AI 压缩成一张公开基准看板¶
@NVIDIAAI 发帖(43 次点赞、2 条回复、3,717 次浏览、5 次收藏),用一张幻灯片把 Cosmos 3 放进了横跨文本到图像、图像到视频、世界生成、物理推理、动作策略、世界理解和异常推理的排行榜里。这之所以重要,是因为这一天物理 AI 的公开证明面并不是工厂部署故事,也不是机器人案例研究,而是一张让模型一眼就能被看懂的跨基准测试看板。
7. 机会在哪里¶
[+++] AI 辅助工作的评估基础设施 — DeepSWE、HackerRank 2.0 和 The Information 关于基准感知的信号 都指向同一个缺口:如果运行框架、验证器和 AI 使用规则不被明确写出来,人们就不再相信静态分数。
[++] 带权限控制的智能体运营 — TablePlus MCP Server、Merge 的员工把关层 和 Mirantis 的 AI 工厂栈 汇聚到一点上:在智能体和在线系统之间,缺的那层是有范围的访问、已批准动作和日志。
[++] 带真实评估闭环的领域专家型产品 — @devameer0 对套壳的批评、@vorty279 的护城河讨论串 和 Fabian Hiller 的招聘帖 都在说,只有提示词加 API 的壳远远不够;真正的差异点在检索质量、领域专长和人工复审。
[+] 物理 AI 学习基础设施 — NVIDIAAI 的 Cosmos 3 帖子 和 LightwheelAI 的持续学习讨论串 显示出明确兴趣,但更缺的仍是真实世界验证和数据闭环工具。
8. 要点总结¶
- 对基准测试的信任,成了当天反复出现的争论核心。 DeepSWE 的批评和 The Information 关于模型开始意识到自己在被测的信号,都说明问题现在落在测试表面,而不只是分数本身。 (来源)
- 招聘和测评正在围绕 AI 协作重构。 HackerRank 重做后的面试流程和公开的 AI 素养评分卡,显示出重心正从只看代码测试转向评估人如何与 AI 一起工作。 (来源)
- 限制智能体采用的瓶颈,落在权限、已批准动作和审计轨迹上。 TablePlus 和 Merge 都是因为承诺更安全地接入在线系统,而不只是提供更多自治行为,才吸引了注意。 (来源)
- 市场情绪已经转向反感泛化 API 套壳。 最强的产品批评点名了检索质量、推理成本、边界情况和领域专长,才是真正的护城河。 (来源)
- 物理 AI 仍然需要比公开基准幻灯片更好的学习闭环。 Cosmos 3 带来了基准测试广度;Lightwheel 的帖子则更准确地点出了围绕世界生成、行为数据和评估仍然缺失的系统。 (来源)