Twitter AI 智能体 - 2026-05-19¶
1. 人们在讨论什么¶
1.1 托管运行时和运行框架控制从建议走向产品界面 🡕¶
5 月 19 日最强的讨论簇,已经不再只是解释智能体为什么需要运行框架,而是在讨论厂商如何把运行框架做成产品。最有价值的帖子讲的是托管式 Linux 环境、自托管沙箱、MCP 隧道、浏览器原生 QA,以及可安装的指导包。相比 5 月 18 日还围绕指南、落地角色和信任轨道展开,5 月 19 日更明显地转向了第一方执行界面和验证工具。
@_vmlops 发布了《Harness Engineering: A Design Guide to Claude Code》的封面图(367 次点赞、15,588 次浏览、348 次收藏)。比起配文,图片本身更重要:它把可靠智能体系统压缩成控制平面、循环、恢复、权限、中断和验证,并用一句话写出核心论点:先有系统,再谈模型。

@GoogleAIStudio 推出了 Gemini API 上的 Managed Agents(704 次点赞、26 条回复、29,816 次浏览、285 次收藏)。产品宣称很具体:只需一次 API 调用,就能得到一个由 Google 托管、可扩展的远程 Linux 环境,其中智能体的自定义指令、技能和工具都用 Markdown 定义。回复区马上分成两派:一派兴奋于智能体运维负担更低,另一派则担心定价和培训资料,这说明需求是真实的,只是这种运行模式仍然很新。
@ClaudeDevs 宣布 Claude 托管智能体支持自托管沙箱和 MCP 隧道(207 次点赞、15 条回复、8,456 次浏览、75 次收藏)。Anthropic 的发布文章和文档写得很清楚:工具执行既可以留在客户控制的基础设施里,也可以放在 Cloudflare、Daytona、Modal 或 Vercel 这类托管提供商上;与此同时,私有 MCP 服务器也能在不开入站防火墙规则的前提下保持可达。后续一条回复(19 次点赞、3,851 次浏览)还补充说,实时会话无需重启就能切换工具、MCP 服务器或 vault ID,也能把超大的 MCP 输出转存到沙箱文件里。

@Google 发布了 面向智能体的 Chrome DevTools,把它定位成浏览器原生的验证层(36 次点赞、4 条回复、10,950 次浏览、14 次收藏)。Chrome 文档和GitHub 仓库写道,它以 MCP server、CLI 和技能包的形式提供,让智能体可以在发布前检查真实页面、模拟用户、运行 Lighthouse 审计并分析性能;第一条回复还介绍了 WebMCP(26 次点赞、2 条回复、6,670 次浏览、16 次收藏),把它作为网站与编程智能体之间的候选桥梁。
@ChromiumDev 推出了《Modern Web Guidance》(20 次点赞、2 条回复、3,078 次浏览、10 次收藏),这是一个可安装的技能包,面向 Antigravity CLI、Claude Code 和 Copilot。文档称,这个技能包会持续更新,并由专家审核,还带有 Baseline 回退方案,避免编程智能体继续默认使用过时的 Web 模式。
讨论要点: 这一整条主题背后的安全动机,说得异常直白。@nazirtech01 表示(22 次点赞、1 条回复、1,657 次浏览、18 次收藏),他们已经把所有 AI 编程智能体项目切换到 npm ci --ignore-scripts,再加上 7 天的 Renovate 冷却期,因为 Claude 和 Codex 会很乐意安装幻觉出来的包。于是,沙箱、隧道和指导包的推进,看起来更像是在回应已经观察到的风险,而不是单纯做产品打磨。
与前日对比: 5 月 18 日把运行框架工程当成课程、落地纪律和信任基础设施。5 月 19 日则把同样的想法做成了可执行产品:托管运行时、具备边界意识的沙箱、浏览器 QA 和可安装指导。
1.2 智能体优先产品和编排器继续取代单智能体聊天 🡕¶
第二个讨论簇聚焦的是智能体该如何被呈现和协调。共同的转向,是不再把智能体当成又一个侧边栏,而是把它当成长时运行的工作者,具备委派、交接和明确隔离。相比 5 月 18 日更关注市场和商业轨道,5 月 19 日谈得更多的是执行界面、编排命令,以及工作究竟该在哪里运行。
@antigravity 推出了 Antigravity 2.0,把它做成一个独立桌面应用,围绕多智能体团队、定时任务、原生语音,以及与其他 Google 产品的一键集成重新打造(793 次点赞、132 条回复、33 条引用、33,684 次浏览、285 次收藏)。这次发布把产品定位成“为智能体优化的桌面”,而不只是一个更好的 IDE 扩展。
@Google 进一步强化了 这种定位(246 次点赞、23 条回复、21,089 次浏览、23 次收藏),明确把这款应用称为“智能体优先”,核心是智能体对话、智能体生成的工件,以及多智能体编排。回复区反复提到同一个差异:大多数软件仍然是“文件优先”或“应用优先”,而这次发布把智能体当成了主要界面。
@lobehub 发布了 Chief Agent Operator,它会从一个拥有 27.3 万技能的市场里雇佣智能体,让它们在云端 24/7 运行,并通过 IM 应用回报结果(383 次点赞、62 条回复、67 条引用、580,400 次浏览、133 次收藏)。来自 @CatCatBros 的一条回复 说 Discord 连接“非常简单”(5 次点赞、2 条回复、590 次浏览),这让 IM 路由的卖点更像一个可用性故事,而不只是市场规模吹嘘。
@warpdotdev 宣布 Oz 为 Claude Code、Codex 和 Warp Agent 提供多智能体编排(110 次点赞、11 条回复、5 条引用、5,738 次浏览、27 次收藏)。原始推文更像预告,真正有分量的证据在后续回复里:本地子智能体拥有各自独立的工作树,云端子智能体则放在隔离的 Docker 容器里,本地会话还可以在夜间把工作交接给云端继续跑。
@Saboo_Shubham_ 展示了(57 次点赞、13 条回复、2,552 次浏览、65 次收藏)一个 Hermes 工作流:Kanban 看板负责拆解任务,SmallCode 配合 Ollama 处理范围较窄的编码任务,Claude 或 Codex 则负责更难的规划和含糊不清的工作。图片之所以重要,是因为它让路由策略变得一目了然,而不再把“多智能体”留成一句模糊承诺。
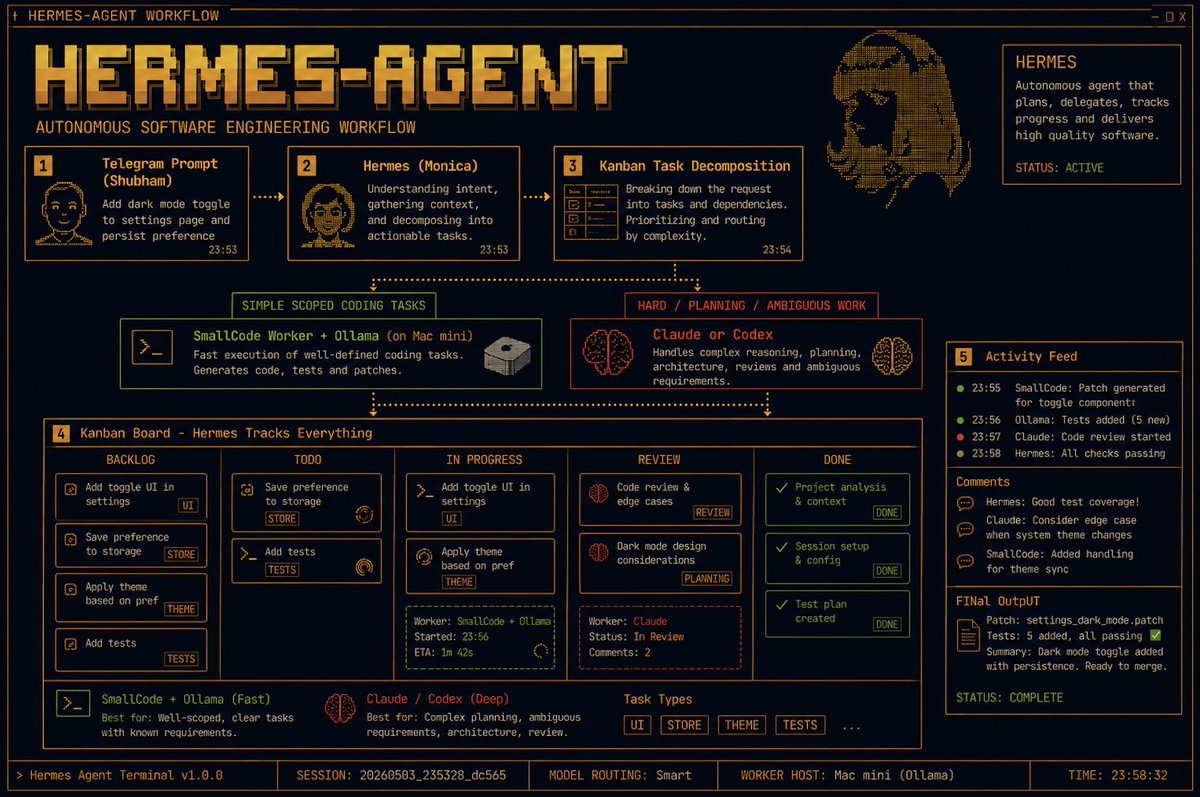
讨论要点: 最有价值的纠偏,来自 @pvncher。他先主张(78 次点赞、10 条回复、12,674 次浏览、67 次收藏)由管理者主导的编排优于智能体蜂群。随后他又在回复(2 次点赞、2 条回复、145 次浏览)里指出,任意的智能体到智能体消息传递会加入无关细节,并行最适合只读工作,而写入路径需要加锁和验证。这一点与当天的产品发布高度一致:真正胜出的模式不是让智能体彼此聊得更多,而是把边界划得更清楚。
与前日对比: 5 月 18 日的运营层话题,更偏向市场、结算和云端代运营角色。5 月 19 日保留了这条线,但把它落到了隔离的工作树、隔离容器和智能体优先界面上。
1.3 记忆、上下文和技能成了真正的控制面 🡕¶
除发布消息外,最有实质内容的讨论,是智能体在不同运行之间究竟携带什么:受约束的上下文、结构化记忆、自我纠错的存储,以及会随时间演化的技能。当天几条最强帖子都明确表示,智能体战略本质上是数据战略,或者说 Markdown 技能文件正在变成一种新的软件单元。相比 5 月 18 日强调可移植性,5 月 19 日更深入地谈到了所有权、失效处理和检索设计。
@Aurimas_Gr 梳理了(141 次点赞、7 条回复、6,206 次浏览、147 次收藏)智能体记忆的四层:情节记忆、语义记忆、程序性记忆,以及短期工作记忆。图片把结构讲得很具体:私有知识库和嵌入进入语义记忆,提示词与工具注册表构成程序性记忆,而编排器会在运行时组装短期工作记忆。

@levie 认为(116 次点赞、22 条回复、18,427 次浏览、123 次收藏),企业智能体战略里最大的难题,是给智能体提供恰好合适且受约束的上下文,因为信息冲突太多或可用上下文太少,都会让结果失真。回复区把痛点说得更尖锐:@tokenomicz 说(16 次浏览),当文档、聊天记录和电子表格彼此矛盾时,上下文归属比上下文大小更重要;@jatingargiitk 说(31 次浏览),真正难的是持续维护,因为数据在清理完的第二天就开始腐坏。
@garrytan 表示(141 次点赞、24 条回复、16,488 次浏览、125 次收藏),动态技能之所以强大,是因为 Markdown 就是代码,出现新情况时智能体可以直接改它。这条推文引用的例子还把方向推进了一步:技能包应该自带测试,智能体也应该被允许在运行中更新工具链,而不是停在一套静态库上。
@tom_doerr 分享了 Pro Workflow(30 次点赞、2 条回复、1,719 次浏览、32 次收藏),其 GitHub 仓库 把它描述成一个单一的 SQLite 存储,里面放着自我纠错记忆、以 FTS5 建索引的 wiki,以及自动研究循环。这个承诺立刻招来了正确的质疑:@Timur_Yessenov 在回复(16 次浏览)里说,自我纠错记忆还需要一条坏记忆路径,让已经失效的假设可以被撤销,而不只是被记住。
@Ghast_AI 开源了 Anamnesis(15 次点赞、2 条引用、767 次浏览),它的仓库把它描述为一个本地优先的记忆桥,可以在 Claude Code、Codex、Hermes、OpenClaw、mem0、Letta 和通用 MCP 来源之间导入并提供现有记忆。这比前几条帖子信号弱一些,但它满足的是同一种需求:记忆应该属于用户,而不是属于某一个智能体运行时。
讨论要点: 最具体的工程警告来自 @0xMevu。他在回复(41 次浏览)里说,编程智能体里的向量记忆会让大约 3,000 条陈旧工具输出污染召回,直到他改成只追加的事件日志加回放。当天对记忆充满热情,但并没有对检索和遗忘抱有天真幻想。
与前日对比: 5 月 18 日强调的是技能、讨论串和跨智能体可移植性。5 月 19 日则花了更多时间讨论谁拥有上下文、记忆如何建模,以及当记忆出错时该怎么办。
1.4 语音智能体看起来更能落地,也更不像演示了 🡕¶
语音仍然是最清晰的应用型智能体讨论簇之一,但证据重心已经转向交付机制:基于 IDE 的构建流程、呼叫中心专用设计、自动生成的集成,以及教育这类垂直场景。相比 5 月 18 日,更多讨论开始把语音智能体当成普通的软件交付目标,而不只是单独拿出来展示的惊艳演示。
@tec_aryan 表示(67 次点赞、24 条回复、15,860 次浏览、8 次收藏),PolyAI 已经把它的语音智能体平台向所有人开放。最有力的证据来自后续回复:@tec_aryan 说(16 次点赞、709 次浏览),开发者无需专业服务,也不用签六位数合同,就能在 10 分钟内从零部署一个生产可用的语音智能体;另一条回复(13 次点赞、478 次浏览)则说,这个平台已经在为 FedEx、Marriott、Caesars 和 Gordon Ramsay 餐厅处理客户对话。
@TheAIColony 声称(110 次点赞、12 条回复、7,601 次浏览、84 次收藏),Claude 配合 PolyAI 可以在 10 分钟内搭出一个能接电话、筛选潜在客户并处理客服请求的语音智能体。单看这一条,它更像一个配置演示;但和更长的 PolyAI 讨论串放在一起看,它更像一条逐渐成形的开发者工作流。
@ElevenLabs 发布了 Einstein 智能体,把档案材料变成交互式语音教育体验(197 次点赞、19 条回复、13,803 次浏览、47 次收藏)。回复区很有价值,因为它并不是一边倒地叫好:公司的一条回复强调了多语言教育价值,另一条则把它形容成“一个带口音、价格还很贵的搜索引擎”,这让真正的实用性和新奇感被分了开来。
@Google 推出了 Gemini Spark,把它描述成一个绑定 Gmail 和 Docs 的后台个人智能体,即使笔记本电脑合上,它也会继续工作(47 次点赞、6 条回复、3,666 次浏览、5 次收藏)。严格说来,这不完全是一条语音智能体帖子,但它强化了同样的转向:智能体开始处理长时运行的现实任务,而不是等着下一条提示词。
讨论要点: 最清晰的差异化来自 @tec_aryan 的一句话。他说(14 次点赞、1 条回复、882 次浏览),大多数 AI 语音工具都是后来从聊天机器人系统改造过来的,所以它们仍然难以处理打断、口音、背景噪声和正常的人类对话。这让“电话场景专用设计”成为一个真实的产品楔子,而不只是品牌说法。
与前日对比: 5 月 18 日,语音智能体已经很显眼;但 5 月 19 日又补上了更多证据,说明它们已经能用普通开发者工作流构建、测试和部署,而不必依赖定制化的企业项目。
2. 令人困扰的问题¶
上下文质量恶化的速度,比上下文窗口扩大的速度还快¶
严重程度:高。@levie 认为(116 次点赞、22 条回复、18,427 次浏览、123 次收藏),多数企业智能体失败,本质上都是数据战略失败:信息冲突太多,或可用上下文太少,都会让结果崩掉。回复区把这种失效模式说得更尖锐:@tokenomicz 说(16 次浏览),当文档、聊天记录和电子表格彼此矛盾时,上下文归属才是关键;@jatingargiitk 说(31 次浏览),最难的是持续维护,因为清理过的数据马上又会开始腐坏。@DailyDoseOfDS_ 分享了(11 次点赞、1 条回复、2,505 次浏览、17 次收藏)一条引用说法:通过 InsForge 打包后端上下文,把 Claude Code 的使用量从 10.4M tokens 和 10 个错误降到了 3.7M tokens 和 0 个错误;这是整份数据集中最具体的证据,说明上下文打包会直接改变成本和失败率。应对模式已经很清楚:收窄任务范围、保持单一事实源、预先组装上下文层,而不是每次都重新发现。值得做,因为人们已经在为修补这个问题消耗大量 token 和工程时间。
安全边界仍然依赖硬隔离和更严格的依赖卫生¶
严重程度:高。@ClaudeDevs 宣布(207 次点赞、15 条回复、8,456 次浏览、75 次收藏),自托管沙箱和 MCP 隧道让托管智能体可以在客户基础设施里执行,并在不公开暴露私有服务的前提下访问它们。@nazirtech01 说(22 次点赞、1 条回复、1,657 次浏览、18 次收藏),他们现在强制使用 npm ci --ignore-scripts,并加上 7 天 Renovate 冷却期,因为 Claude 和 Codex 会安装幻觉出来的包。@DarkWebInformer 分享了(18 次点赞、2 条回复、2,848 次浏览、22 次收藏)Pentest Agent Suite,但即便这种安全反应也在说明同一件事:一旦给智能体自治权,攻击面就会扩张,除非执行、依赖和工具访问都被严密控制。当前的权宜方案,是分层隔离、对依赖包更保守,以及更明确的权限边界。值得做,因为人们已经在手动改写安装和运行时策略。
多智能体工作在太多智能体同时写入时会退化¶
严重程度:中。@pvncher 认为(78 次点赞、10 条回复、12,674 次浏览、67 次收藏),由管理者主导的编排优于蜂群,随后又在回复(2 次点赞、2 条回复、145 次浏览)里说,任意的智能体到智能体消息传递会加入无关细节,而写入路径需要加锁和验证。@warpdotdev 给出的答案是(110 次点赞、11 条回复、5,738 次浏览、27 次收藏)本地用隔离的工作树,云端用隔离的 Docker 容器;@Saboo_Shubham_ 展示了(57 次点赞、13 条回复、2,552 次浏览、65 次收藏)一个 Hermes 看板,把范围窄的任务交给一类执行者,把含糊工作交给另一类。当前的权宜方案,是串行拆解加上强隔离,而不是让更多智能体彼此聊天。值得做,因为社区现在已经对什么会坏、什么样的控制才有效,有了很清晰的共识。
记忆系统仍然需要遗忘,而不只是检索¶
严重程度:中。@Aurimas_Gr 描述了(141 次点赞、7 条回复、6,206 次浏览、147 次收藏)一个分层记忆模型,但更能说明问题的其实是回复区:@0xMevu 说(41 次浏览),陈旧的工具输出会污染召回,直到他改用只追加的事件日志加回放;@Timur_Yessenov 在回复(16 次浏览)里则说,自我纠错记忆需要一条明确的坏记忆路径。当天充满了记忆产品和框架,但最清晰的痛点其实是失效处理:那些曾经有用、现在却错了的记忆,该如何被撤销或隔离。值得做,因为当前系统更容易记住,而不是更容易忘掉。
3. 人们期望的功能¶
能跨工具迁移且仍归用户所有的可移植记忆¶
大家显然在要求一种记忆:它能在运行框架切换后继续存在,又不会把人锁死在某个运行时里。@tom_doerr 分享了《Pro Workflow》,里面是一套基于 SQLite 的记忆和知识库存储(30 次点赞、2 条回复、1,719 次浏览、32 次收藏);@Ghast_AI 开源了《Anamnesis》(15 次点赞、2 条引用、767 次浏览),把它做成 Claude Code、Codex、Hermes 和其他工具之间的桥;@warpdotdev 则把 Oz 和一个跨运行框架的《Agent Memory》候补名单绑定在了一起。这个需求的紧迫性很务实,而不是偏愿景:人们已经有大量上下文被困在多个系统里,不想每换一个工具就从零开始。机会:直接。
经过测试、可打包且允许演化的技能系统¶
大家想要的,已经不只是“更多技能”。@garrytan 说(141 次点赞、24 条回复、16,488 次浏览、125 次收藏),智能体应该能在运行中更新 Markdown 技能;@kotlin 发布了(62 次点赞、1 条回复、1,938 次浏览、29 次收藏)一个官方 GitHub 仓库,里面是可安装的 Kotlin 智能体技能;@DanKornas 展示了(10 次点赞、2 条回复、509 次浏览、15 次收藏)《Skill Conductor》,它把技能创作视为创建、评估、编辑、审阅和打包,而不是“写个 SKILL.md 然后祈祷它能用”。未被满足的需求,是一条真正的软件生命周期:架构选择、测试、打包、分发,以及安全地修订。机会:直接且竞争激烈。
默认就提供私有执行和私有工具访问¶
最大的基础设施诉求,是让智能体在不跨出组织边界的前提下,仍然保持有用。@ClaudeDevs 推出了 自托管沙箱和 MCP 隧道,而 @GoogleAIStudio 推出了 Gemini API 上的托管 Linux 环境。两条讨论串的模式完全一样:团队想要托管编排,但不想为此交出网络策略、私有服务或文件系统控制权。机会:直接且竞争激烈。
像正常生产软件那样工作的语音智能体构建器¶
这些语音帖子并不是在要更好的演示,而是在要能部署的系统。@tec_aryan 说(67 次点赞、24 条回复、15,860 次浏览、8 次收藏),PolyAI 现在让任何人都能从 IDE 快速构建并部署一个生产可用的语音智能体,而后续讨论串强调,真正的差异点在于打断、口音和通话流程可靠性。@ElevenLabs 展示了 一个面向教育的语音智能体,@Google 把 Gemini Spark 描述成一个合上笔记本也会继续工作的后台个人智能体。缺的不是兴趣,而是一个可靠、生产级的交付路径,用来构建长生命周期的语音和任务智能体。机会:直接且竞争激烈。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Gemini API Managed Agents | 智能体运行时 | (+/-) | 一条 API 调用就能拉起一个远程 Linux 环境,指令、技能和工具都用 Markdown 定义 | 回复区立刻提出定价和入门问题;公开的运营细节仍然较薄 |
| Claude Managed Agents | 托管智能体运行时 | (+) | 自托管沙箱、MCP 隧道、实时工具与 MCP 热切换、大输出可转存到沙箱文件 | 自托管沙箱暂不支持记忆;MCP 隧道仍是研究预览 |
| Chrome DevTools for agents | 调试 / MCP | (+) | 实时浏览器检查、Lighthouse 审计、仿真、截图、性能分析、CLI 加技能 | 仅限浏览器场景,而且会有意把浏览器状态暴露给 MCP 客户端 |
| Modern Web Guidance | 技能包 | (+) | 持续更新、专家审核的 Web 技能,并带有 Baseline 回退;可安装到主流编程智能体 | 聚焦面较窄,只覆盖 Web 开发 |
| Warp Oz | 编排平台 | (+/-) | 在 Claude Code、Codex 和 Warp Agent 之间提供多运行框架编排,带隔离工作树和云端容器 | 仍是 beta;Agent Memory 还只是研究预览 |
| Hermes Agent | 编排器 / 运行时 | (+/-) | 明确的 Kanban 拆解、简单任务用受限本地执行者、更强模型负责规划和审查 | 需要严格的作用域和路由纪律;蜂群式写入路径仍属高风险 |
| Pro Workflow | 记忆 / 上下文层 | (+) | SQLite 支撑的自我纠错记忆、FTS5 wiki、自动研究循环、跨会话召回 | 连支持者也想要坏记忆路径和明确的失效机制 |
| PolyAI ADK | 语音智能体平台 | (+) | 可从 IDE 构建、测试、部署语音智能体,带电话场景流程和自动生成的集成 | 公开证据主要还是发布讨论串细节和企业案例,不是广泛用户评测 |
| InsForge | 后端上下文层 | (+) | 用 MCP 和 CLI 集中暴露后端拓扑,据称把 token 用量从 10.4M 降到 3.7M | 前提是团队愿意把 InsForge 当成后端控制面 |
| Pentest Agent Suite | 安全框架 | (+/-) | 跨工具大套件,含 50 个智能体、26 个命令、19 个 CLI 工具、11 个技能和 2 个 MCP servers | 安全搜寻仍需要证明和验证,避免幻觉发现 |
| Kotlin agent skills | 语言技能包 | (+) | 可复用的迁移和工具技能,按标准 SKILL.md 目录打包 | Kotlin 专用,而且目录更像孵化器式清单 |
| Skill Conductor | 技能生命周期方法 | (+) | 先架构、再 create、eval、edit、review 和 package,在写 SKILL.md 之前就明确模式 | 比快速的提示词转技能流程更重 |
只要工具把边界画得更清楚,整体满意度就偏正面:自托管沙箱、工作树、容器、浏览器 QA 和官方技能包都得到了不错的反馈。混合评价主要出现在工具又加了一层治理负担的时候,比如多运行框架编排、跨会话记忆,或是缺少强证明的安全自动化。
迁移路径也越来越容易描述。团队正在从提示词优先的配置,转向架构优先的技能;从反复发现,转向预打包的上下文层;从单智能体聊天,转向本地与云端工作者的编排;从记忆孤岛,转向可移植或自托管的记忆存储。竞争压力也更清晰了:Google 和 Anthropic 在出货运行时,Chrome 和 Chromium 在出货验证与指导,而社区则在争夺这些运行时之外的记忆、技能和编排层。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| Antigravity 2.0 | @antigravity | 独立的智能体优先桌面应用,带多智能体团队、定时任务、原生语音和 Google 集成 | 聊天窗口式工作流不适合长时自主工作 | 桌面应用、多智能体编排、原生语音、Google 产品集成 | Shipped | 推文, 博客 |
| Managed Agents on Gemini API | @GoogleAIStudio | 托管的远程 Linux 环境,一次 API 调用即可启动带自定义指令、技能和工具的智能体 | 团队想要托管执行,但不想手搓运行时管线 | Gemini API、远程 Linux 环境、Markdown 技能与工具 | Beta | 推文 |
| Claude Managed Agents | @ClaudeDevs | 带自托管沙箱和私有 MCP 隧道的托管智能体 | 企业需要把智能体执行和工具访问留在自身安全边界内 | Anthropic 智能体循环、自托管沙箱、MCP 隧道、Cloudflare/Daytona/Modal/Vercel | Beta | 推文, 博客, 文档 |
| LobeHub Chief Agent Operator | @lobehub | 从大型技能市场挑选智能体,持续运行,并通过 IM 应用汇报 | 手动选择和监控智能体太费人 | 云端智能体市场、IM 集成、技能目录 | Shipped | 推文 |
| Oz + Agent Memory | @warpdotdev | 在本地和云端运行之间编排 Claude Code、Codex 和 Warp Agent;Agent Memory 想把学习结果跨运行框架保存下来 | 团队需要协同的多智能体工作,又不想被锁死在单一运行框架里 | 工作树、隔离 Docker 容器、多运行框架编排、可移植记忆 | Beta | 推文, 介绍 |
| Pro Workflow | @tom_doerr 分享 | 给 Claude Code 等智能体加上自我纠错记忆、FTS5 wiki 和自动研究循环 | 反复修正和研究成果会在会话间消失 | SQLite、FTS5、hooks、skills、agents | Shipped | 推文, GitHub |
| PolyAI ADK / Agent Studio | @tec_aryan | 从 IDE 构建、测试并部署电话语音智能体,自动生成知识和集成 | 大多数语音工具源自聊天产品改造,扛不住真实通话流程 | TypeScript ADK、电话语音栈、HubSpot/Stripe 集成、Studio | Shipped | 推文, Studio |
| Autogenesis | @AI4S_Catalyst | 会自演化的智能体协议和运行时,可对提示词、工具、记忆、环境和智能体做版本化与回滚 | 自我改进的智能体需要明确的生命周期、版本控制和治理 | RSPL/SEPL 协议、追踪、版本化、工具调用运行时 | Alpha | 推文, 论文, GitHub |
| Pentest Agent Suite | @DarkWebInformer 分享 | 面向 Claude Code 和另外 6 个编程工具的自治漏洞赏金框架 | 安全搜寻需要可重复的跨工具智能体工作流 | Python、50 个智能体、26 个命令、19 个 CLI 工具、11 个技能、2 个 MCP servers | Alpha | 推文, GitHub |
| Kotlin agent skills | @kotlin | 用于迁移和工具任务的 Kotlin 专用技能开源仓库 | 团队想要可复用的语言专用技能,而不是每次迁移都重新写提示词 | SKILL.md 技能目录、插件和 npx 安装流程 | Shipped | 推文, GitHub |
Google 和 Anthropic 这一天都在从不同角度产品化同一个核心想法:让编排继续托管,但让执行和控制面更像真正的基础设施。Antigravity、Gemini API 上的 Managed Agents、Claude Managed Agents 和 Oz 都默认下一个瓶颈不只是模型质量,而是智能体如何被分阶段推出、隔离、恢复和观测。
第二个反复出现的构建模式,是把记忆和技能打包成耐久工件。Pro Workflow、Autogenesis 和 Kotlin agent skills 都不再把提示词、规则、上下文或任务流程当成一次性的聊天上下文,而是把它们当成可以存储、版本化、检索和分发的软件。尽管它们解决的问题不同,但前提是一样的:只有当能力能活过一次会话,智能体能力才会累积。
最强的垂直构建方向是语音和安全。PolyAI 正在把语音智能体变成开发者可以直接从 IDE 构建和部署的东西,而 Pentest Agent Suite 则把漏洞搜寻工作流打成一套可跟着用户跨编程工具移动的套件。LobeHub 则位于这两者之间,它不是再做一个新智能体,而是想直接掌控多智能体的选择、执行和汇报。
6. 新动态与亮点¶
面向智能体的 Chrome DevTools 达到稳定版 1.0¶
@Google 发布了 面向智能体的 Chrome DevTools,而 @ChromiumDev 表示(17 次点赞、2 条回复、825 次浏览、9 次收藏),它现在已经把浏览器调试、仿真和 Lighthouse 审计通过 MCP server、CLI 和专用技能带给编程智能体。GitHub 项目 把更大的方向说得很明白:浏览器验证正在被打包成可复用的智能体基础设施,而不再是临时手工步骤。
Gemini Spark 让后台个人智能体更具体了¶
@Google 推出了 Gemini Spark,把它描述成一个与 Gmail 和 Docs 集成的个人智能体,即便笔记本电脑合上也会继续运行(47 次点赞、6 条回复、3,666 次浏览、5 次收藏)。示例任务特意选得很日常——协调街区派对的后勤安排——这让这次发布显得特别,因为它讲的是任务如何在后台跑完,而不是机灵的聊天。
技能创作开始走向更正式的流程¶
@DanKornas 展示了(10 次点赞、2 条回复、509 次浏览、15 次收藏)《Skill Conductor》,这是一套架构优先的技能生命周期方法:在写任何 SKILL.md 之前,先强制你在若干模式中做选择,然后再进入创建、评估、编辑、审阅和打包模式。它之所以值得注意,是因为它不再把技能当成提示词片段,而是把它当成带测试和发布纪律的软件组件。

Anamnesis 把记忆可移植性变成了一座 MCP 桥¶
@Ghast_AI 开源了(15 次点赞、2 条引用、767 次浏览)Anamnesis,仓库称它可以在 Claude Code、Codex、Hermes、OpenClaw、mem0、Letta 和通用 MCP 来源之间导入、规范化、索引并提供现有记忆。相比那些大发布,它的信号更小,但它是最清晰、直接对准跨工具记忆碎片化的构建之一。
7. 机会在哪里¶
[+++] 私有执行加私有工具访问 —— Google Managed Agents 和 Claude Managed Agents 都指向同一种需求:团队想要托管编排,但执行、文件系统和内部服务仍要留在自己的控制之下。@nazirtech01 关于依赖卫生的警告让这个机会更强,因为它解释了企业为什么一开始就在要求沙箱和更紧的策略边界。
[+++] 具备所有权和失效机制的可移植记忆 —— Pro Workflow、Anamnesis、Warp Agent Memory,以及记忆讨论串里的回复,都汇聚到同一个缺口:人们想要能跨工具移动、可自托管,并在必要时忘掉错误假设的记忆。这个机会很强,因为这种需求既出现在产品发布里,也出现在一线使用者对陈旧召回的抱怨里。
[++] 架构优先的技能生命周期和策展型技能包 —— Garry Tan 关于动态技能的帖子、Kotlin 的官方技能仓库、《Skill Conductor》和《Modern Web Guidance》,都把技能当成需要测试、打包和分发的软件工件。这个机会属于中等而非完全空白,因为多个厂商和社区已经在这里快速推进。
[++] 带隔离写入路径的多运行框架编排 —— Oz、Hermes 和 pvncher 的回复都在主张同一种运行模型:有作用域的子智能体、隔离,以及针对写入任务的串行拆解。这个机会很有意义,因为团队显然想要编排,但当前共识是:没有控制的蜂群仍然很脆弱。
[++] 电话级语音智能体构建器 —— PolyAI、ElevenLabs 和 Gemini Spark 都表明,市场对能处理通话、教育或长生命周期个人任务的智能体有明确需求。最强的差异化并不只是“语音”本身,而是它在打断、口音、背景噪声和长工作流下的可靠性。
[+] 高 token 效率的后端上下文层 —— InsForge 那条从 10.4M 到 3.7M 的 token 降幅引用,以及 Levie 关于上下文归属的讨论串,都说明一种新机会正在出现:在智能体开始写代码之前,先把后端和组织上下文预先组装好。这个机会仍在浮现,但成本和错误率的故事已经很有说服力。
8. 要点总结¶
- 托管式执行成了当天最清晰的产品信号。 Google 和 Anthropic 都推出了更强的运行时界面,智能体可靠性也越来越被当作基础设施来出售,而不只是提示词技巧。 (来源)
- 社区正在收敛到“有边界的编排”,而不是“无规则的蜂群”。 最有分量的回复支持有作用域的子智能体、隔离的工作树或容器,以及针对写入任务的串行拆解。 (来源)
- 企业智能体质量的根本问题,仍然是上下文归属。 最有说服力的抱怨都在说:互相冲突的数据源和持续腐坏的知识库,会比更大的上下文窗口更快地把智能体拖垮。 (来源)
- 记忆现在既要可移植,也要可撤销。 重要的细节不是智能体应该记得更多,而是它们需要能在工具之间迁移记忆,并让陈旧召回失效。 (来源)
- 语音智能体开始看起来像普通的生产软件了。 PolyAI 的讨论串最能说明这一点,因为它描述的是基于 IDE 的构建、测试和部署流程,以及真实的客户通话落地。 (来源)
- 技能正在被当成软件包,而不是提示词片段。 官方技能仓库、指导包和架构优先的创建流程,都指向带测试、可打包、受发布纪律约束的技能。 (来源)