Twitter AI Coding - 2026-06-05¶
1. 人们在讨论什么¶
1.1 控制平面、画布和工作树编排变成了产品界面 🡕¶
最强的工作流讨论不再是某个模型能否在聊天窗里给出更好的回答,而是在问多智能体工作到底住在哪里、如何保持可检查,以及究竟是哪一层界面在协调并行任务、浏览器和仓库。六条留存条目支持了这一主题。
@thdxr 展示(718 次点赞、37 条回复、38,727 次浏览、427 次收藏)了一套基于 git worktrees 的并行 OpenCode 工作流,并在回复中澄清 1.16.0 才是正确版本、移动 Web 布局正在改进,以及 OpenCode 2.0 会默认只保留一个可发现实例,让每次调用都能连到同一个运行中的 server。这让产品主张的重点不再是抽象的“并行智能体”,而是具体的会话、工作区和进程管理。
@skirano 发布(238 次点赞、28 条回复、17,283 次浏览、152 次收藏)了作为官方 Codex 插件的 MagicPath,而回复串补上了缺失的具体细节:Codex 可以从仓库导入 UI、理解其设计系统、把它重建成一个可编辑画布、直接在该画布里处理图片,并在 Codex 浏览器中跑完整个工作流。这让 MagicPath 不像一个设计 demo,更像是仓库与智能体共享的工作界面。
@pierrepinna 分享(19 次点赞、1 条回复、417 次浏览)了一张 Google Cloud Summit 幻灯片,把 Antigravity 2.0 称为“一块用于在传统 CLI 之外协调智能体、开发者和浏览器的专用界面”,这与同样的转向一致:重点从命令执行转到了协调界面。

@chamath 认为(73 次点赞、16 条回复、26,642 次浏览、34 次收藏),公司现在想要的是位于模型之上的控制平面,用来管理支出、路由和可衡量结果。这种框架也与 @OpenCodeLog 发布(33 次点赞、3 条回复、3,105 次浏览)的 OpenCode 1.16.0 更新相呼应:工作树移动、多 server 项目状态、模型级统计页面,以及实验性的控制平面路由。

@theaiuniverse 认为(3 条回复、98 次浏览),Codex Sites 把同样的趋势延伸到了托管应用:不再把内部工具的 prompt 构建结果交给外部部署,而是直接提供内建托管、数据库接入和定时刷新。
讨论要点: 最有价值的回复并没有争论模型原始 IQ,而是在问要运行多少个实例、路由和支出该如何管理,以及某个界面是否能扛住真实会话周围那些杂乱的协调工作。
与前日对比: 6 月 4 日已经展示了 AI 编程产品如何逃离编辑器,走向托管应用、CI 和移动端。到了 6 月 5 日,这条轨迹又向前推进到明确的控制平面、共享画布,以及具备工作树感知能力的编排。
1.2 以文档为先的运行框架,看起来比模型选择更重要 🡕¶
第二个主要主题认为,真正持久的优势不在于“选哪个模型”,而在于模型外面的运行框架:文档、权限、自动化检查,以及可重复的工作流结构。三条留存条目支持了这一主题。
@aakashgupta 认为(42 次点赞、4 条回复、7,292 次浏览、58 次收藏),一个 OpenAI 团队负责人先禁止工程师碰键盘,再花两个月写文档,之后才扩展到自动化检查和非工程人员上线。附图的重要之处在于,它把推进顺序说得很清楚:先让仓库可读,再编码偏好,最后扩大委托范围。

同一位作者随后 补充(9 次点赞、2 条回复、1,550 次浏览、14 次收藏)了一套 OpenAI PM 使用的 Codex 配置:每天开始前先跑 3 个自动化,先做原型再写 PRD,构建过程配套 FAQ 文档,并采用分级权限,让读取和起草可以自由运行,而面向人的输出仍然要经过审查。这讲的是运行框架设计,而不是提示词设计。

@OpenCodeLog 记录(33 次点赞、3 条回复、3,105 次浏览)了产品层面的同一种本能:会话进入核心,/move 负责工作树转移,排队中的提示词可以在执行前编辑,而 server 现在也暴露出针对 sessions、models、providers、filesystem 和 commands 的类型化路由。
讨论要点: @aakashgupta 帖子下最犀利的一条回复说,关键杠杆不是“无代码”,而是先把仓库写得足够可读,让智能体不再瞎猜。这是当天最清晰的从业者提炼。
与前日对比: 6 月 4 日让智能体运维显得更加可打包、可审计;6 月 5 日则让它显得更像一套流程:文档树、FAQ 配套文档、权限分层、会话路由和队列管理。
1.3 定价压力把行为推向补贴、免费模型路由和 token 感知 🡕¶
经济性讨论继续从统一订阅转向主动路由、补贴和立刻可用的绕行方案。三条留存条目支持了这一主题。
@_0xpainn 发帖(59 次点赞、13 条回复、4,352 次浏览、95 次收藏),给出了一套 10 分钟内让 Claude Code 在 Antigravity 中跑 OpenRouter 免费模型的配方,并明确把它定位为一种绕开 Anthropic 计费和付费 API key 的办法。回复并不把它当成噱头,而是把它视作严肃的预算绕行方案,甚至有人建议在免费模型档位之间增加自动兜底路由。
@edzitron 报道(158 次点赞、10 条回复、9,183 次浏览、10 次收藏),Anthropic 正在为首次激活 Claude Code 的用户每人发放 1,000 美元用量积分,每家组织上限 1,000 万美元。截图让这套市场进入方式变得非常具体:先是按量产品,然后在其上叠加补贴。

@slicknet 表示(9 次点赞、1 条回复、770 次浏览),GitHub Copilot 改价后,仅 5 天轻度使用就烧掉了 33% 的月度 token 额度,而在此前一个典型月份里,高级请求通常只会用掉 40%。这已经不只是价格敏感,而是在一周之内就改变了普通用户的使用规划。
讨论要点: 最显著的变化发生在行为层。人们不再抽象争论 AI 编程“值不值”,而是已经开始路由到免费模型、追逐激活积分,并重新计算什么才算轻度使用。
与前日对比: 6 月 4 日的重点是费率卡和积分耗尽;6 月 5 日则展示了人们接下来会怎么做:采用免费模型栈、依赖企业补贴,并近乎实时地盯着 token 消耗。
1.4 信任问题从抽象风险变成了直接锁号和上线摩擦 🡕¶
信任讨论变得更直接,也更少停留在假设层面。人们不再只是警告“可能会出错什么”,而是在报告自己如何在工作流中途失去访问,或如何卡在“原型能跑”和“产品能发”之间。三条留存条目支持了这一主题。
@vinbuildnlog 表示(5 次点赞、9 条回复、541 次浏览),一条大约持续了 28 小时、期间反复重试并多次出现压缩错误的 Codex 工作流,最终以账号停用告终;附图同时展示了刚刚续费的扣款记录,以及一封写明不会再受理任何额外申诉的拒绝邮件。其他用户的回复称,同样的事也发生在他们身上,并明确要求人工复核。
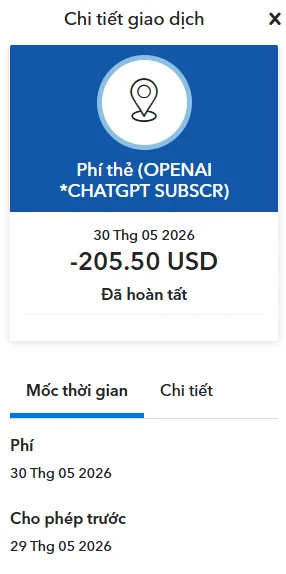
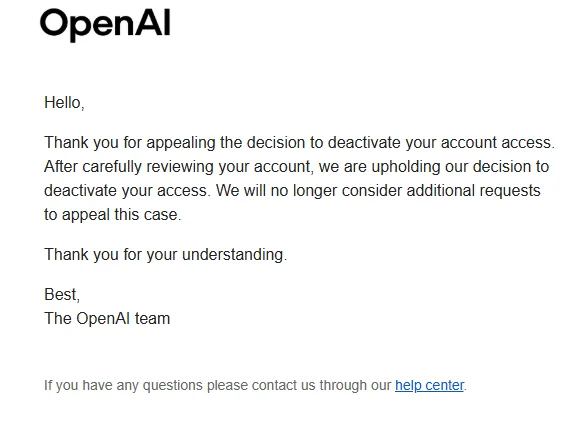
@ignis_code 表示(9 次点赞、2 条回复、425 次浏览),他们只是用 ChatGPT 讨论一个用于检测饮料下药的杯具,就被停用了,并把这描述为一种不看上下文的安全误判,同时连带锁走了自己的 Codex 工作。这让审核质量变成了 AI 编程问题,因为代价不是一条回答被拒,而是整个工作流的丢失。

@teeetariq 认为(1 条回复、35 次浏览、1 次收藏),一个移动应用从“在提示词里能跑”走到“能服务真实客户”,仍然意味着要处理 auth、RevenueCat、商店素材、崩溃监控、托管和 API key 等一长串服务。附带的流程图很有用,因为它让提示词循环之外的那一长串工作变得可见,而不是只被笼统一提。

讨论要点: 那些锁号投诉下的回复并没有要求更强的模型能力。大家要求的是退款、人工复核、解释,以及在策略系统误伤时不要丢掉手头工作的方法。
与前日对比: 6 月 4 日的信任缺口主要还是钓鱼、会话失败和供应商边界;到了 6 月 5 日,问题升级成了多起第一手锁号投诉,以及一个更尖锐的提醒:真正的上线工作仍然大量发生在提示词循环之外。
2. 令人困扰的问题¶
计费和配额变更现在会扭曲正常使用¶
严重程度:高。@slicknet 表示(9 次点赞、1 条回复、770 次浏览),GitHub Copilot 改价后,轻度使用 5 天就已经吃掉了 33% 的月度 token 额度;而 @edzitron 报道(158 次点赞、10 条回复、9,183 次浏览、10 次收藏),Anthropic 的激活促销围绕的是每位用户 1,000 美元用量积分,而不是统一访问权限。最清晰的应对来自 @_0xpainn 发的(59 次点赞、13 条回复、4,352 次浏览、95 次收藏)那套方案:让 Claude Code 在 Antigravity 里跑 OpenRouter 免费模型,回复则立刻开始讨论如何在免费档位之间做兜底路由。这个问题值得构建,因为痛点已经在改变用户行为:人们不只是抱怨价格,而是在围绕价格重构自己的技术栈。
不透明的停用和审核锁定会打断手头工作¶
严重程度:高。@vinbuildnlog 表示(5 次点赞、9 条回复、541 次浏览),一条大约持续了 28 小时的 Codex 工作流最终以账号停用和申诉被拒告终;而 @ignis_code 表示(9 次点赞、2 条回复、425 次浏览),他们只是讨论一个检测饮料下药的产品想法就被停用了。第一条帖子下的回复与原帖同样重要:多位用户说同样的事也发生在自己身上,并明确要求一条人工复核路径。这个问题值得构建,因为失败模式是灾难性的:用户可能会在几乎没有解释的情况下失去访问、历史记录和手头工作。
提示词循环之外,上线仍然像第二份工作¶
严重程度:高。@teeetariq 认为(1 条回复、35 次浏览、1 次收藏),一旦一个应用需要商店素材、auth、RevenueCat、崩溃工具、托管、隐私政策、分析和 API key,容易的部分就已经结束了。@aakashgupta 展示(9 次点赞、2 条回复、1,550 次浏览、14 次收藏)了一位 OpenAI PM:先把精确到表的数据源、FAQ 文档和权限分层接进运行框架,以此弥补这一点,然后才发布任何面向人的输出。这个问题值得构建,因为痛点既广泛又可重复:原型越来越容易,但生产检查清单仍然分散在太多服务和交接环节里。
多会话协调仍然需要额外基础设施¶
严重程度:中高。@thdxr 展示(718 次点赞、37 条回复、38,727 次浏览、427 次收藏)了一套使用工作树的并行 OpenCode 工作流,而一条回复立刻抱怨“老是换端口太累了”。回应是:现在就有可发现 server 模式,而 OpenCode 2.0 还会默认只保留一个实例。与此同时,@chamath 主张(73 次点赞、16 条回复、26,642 次浏览、34 次收藏)在模型之上建立控制平面,而 @pierrepinna 分享(19 次点赞、1 条回复、417 次浏览)了 Google 自己对 Antigravity 2.0 的定位——“协调智能体、开发者和浏览器”。这个问题值得构建,因为痛点不在于智能体不会行动,而在于协调很多个智能体仍然需要明确的脚手架。
3. 人们期望的功能¶
具备预算感知的路由与用量可见性¶
人们要的并不只是“更便宜的 AI”。他们想要的是一层能展示 token 去向、把工作路由到合适模型,并在账单或额度咬人之前让配额变得可预测的系统。@slicknet 展示(9 次点赞、1 条回复、770 次浏览)了 Copilot 用量在改价后变化得有多快;@_0xpainn 分享(59 次点赞、13 条回复、4,352 次浏览、95 次收藏)了一种免费模型绕行方案;而 @chamath 把(73 次点赞、16 条回复、26,642 次浏览、34 次收藏)缺失层定义成模型选择和支出管理的控制平面。Langfuse 和 Headroom 在可观测性和压缩上解决了部分问题,但预算逻辑仍然要由用户自己拼起来。机会:直接。
账号被锁时,能由人工审查的恢复与连续性¶
人们其实是在为自己的 AI 工作请求一张安全网,而不仅是为模型输出请求安全网。@vinbuildnlog 表示(5 次点赞、9 条回复、541 次浏览)他们因为账号停用而失去了一条长时间运行的 Codex 工作流;而 @ignis_code 表示(9 次点赞、2 条回复、425 次浏览),自己的停用属于被误判的 moderation 错误。回复并没有要求更好的提示词,要求的是退款、解释、人工复核,以及不要丢掉当前工作的办法。今天的证据里,没有看到哪款强势产品已经很好地解决了这种连续性问题。机会:直接。
面向 AI 构建应用的 prompt-to-production 上线层¶
最强的未满足运营需求,是一条从“这个应用基本能用”走到“这个应用可以给真实用户使用”的路径。@teeetariq 列出(1 条回复、35 次浏览、1 次收藏)了缺失的拼图:auth、定价、截图、政策、托管、分析、崩溃工具和应用商店流程。@aakashgupta 展示(9 次点赞、2 条回复、1,550 次浏览、14 次收藏)了一种应对方式:把精确到表的数据源、权限分层和审查闸口接进运行框架。现有工具能覆盖其中一些切片,但今天的证据仍然显示的是碎片化,而不是一条单一、可靠的路径。机会:直接且有竞争性。
面向非工程人员的可复用运行框架与智能体工作界面¶
人们也想要比“一条好提示词”更耐用的起点。@aakashgupta 主张(42 次点赞、4 条回复、7,292 次浏览、58 次收藏)先做文档优先的仓库设置;@skirano 发布(238 次点赞、28 条回复、17,283 次浏览、152 次收藏)了 MagicPath 这块共享 Codex 画布;而 @VivekIntel 分享(2 次点赞、133 次浏览)了 skill-creator,让团队可以把 API 和 MCP servers 变成可复用技能。这个需求如今已经被部分满足,但仍是碎片化地满足:这里有画布,那里有技能生成器,文档和命令又散落在别处。机会:有竞争性。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Codex / Sites | 智能体平台 | (+/-) | 从原型到 PR 的工作流、托管内部应用、插件、定时更新 | 企业准入限制、token 压力,以及账号锁定风险仍然存在 |
| Claude Code | 智能体 CLI | (+/-) | 深度仓库工作、双智能体工作流、真实生产用例 | 计费压力和对供应商账号的依赖把用户推向绕行方案 |
| OpenCode | 智能体运行时 | (+/-) | 工作树、排队提示词、多 server 状态、开放运行时界面 | 会话协调仍需额外配置和 UX 加固 |
| Google Antigravity | 智能体界面 / 应用构建器 | (+/-) | 专用编排界面、浏览器协调、适合免费模型方案的可行外壳 | 工具成熟度不均,后续上线工作仍参差不齐 |
| MagicPath | 画布 / 设计工作区 | (+) | 仓库导入、理解设计系统的画布、图像处理、Codex 浏览器流程 | 插件工作流刚起步,且仍绑在 Codex / 浏览器上下文里 |
| OpenRouter free models | 模型路由器 | (+/-) | 免绑卡访问、可切换模型、低成本试验 | 质量和可用性取决于免费档模型 |
| Langfuse | 可观测性 | (+) | 追踪提示词、工具调用、token、耗时和子智能体 | 需要插件设置和独立追踪后端 |
| Headroom | 压缩中间件 | (+) | 显著节省 token,支持本地优先的 proxy / wrap / MCP 模式,以及可逆检索 | 又增加了一层需要运行和调优的组件 |
| skill-creator | 技能生成 | (+) | 把 API、GraphQL 和 MCP servers 变成可复用的跨智能体技能 | 需要基于 Node 的设置和持续的技能维护 |
工具版图呈现出的,是务实而非品牌忠诚。@aakashgupta 展示(9 次点赞、2 条回复、1,550 次浏览、14 次收藏)了 Codex 被用作自动化运行框架的一部分,而不是独立的答案引擎。@skirano 在设计侧展示了(238 次点赞、28 条回复、17,283 次浏览、152 次收藏)同样的事:MagicPath;而 @thdxr 在运行时侧展示了(718 次点赞、37 条回复、38,727 次浏览、427 次收藏)同样的模式:OpenCode 里基于工作树的并行。
最常见的绕行模式,不是直接换智能体,而是在主智能体外面再加一层。@_0xpainn 用(59 次点赞、13 条回复、4,352 次浏览、95 次收藏)Antigravity 加 OpenRouter 免费模型来绕开 Claude 计费;@langfuse 发布(12 次点赞、154 次浏览、4 次收藏)了 Codex 和 Claude Code 的 tracing;而 @drawais_ai 打包了(4 次点赞、24 次浏览)Headroom,让上下文在进入模型前先被压缩。这是一种重要的迁移模式:团队不只是在选模型,而是在它外面组装路由、追踪、压缩和技能层。
竞争态势也遵循同一模式。Antigravity、OpenCode、Codex 和 MagicPath 在竞争的是界面和协调模型;Langfuse、Headroom 和 skill-creator 则在竞争核心智能体栈默认仍然做不好的那部分:可见性、上下文效率和可复用性。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| MagicPath Codex plugin | @skirano | 给 Codex 一块支持多人协作的无限画布,用于可编辑的 UI 工作 | 在纯聊天串里做从仓库到设计的交接很笨拙 | MagicPath 画布、Codex 浏览器/插件、仓库 UI 导入、设计系统感知编辑 | 已发布 | 网站 / 推文 |
| Langfuse Codex integration | Langfuse | 追踪 Codex 会话、工具调用、token、耗时和子智能体 | 没有可观测性时,智能体工作很难检查,也难以控成本 | Codex 插件 hooks、Node.js 22+、Langfuse SDK/backend | 已发布 | 页面 / 推文 |
| Headroom | chopratejas | 在上下文进入模型前先压缩智能体上下文 | 上下文膨胀和 token 成本让长时间智能体会话变得昂贵 | Python/TypeScript、proxy、MCP、wrappers、本地检索 | 已发布 | 仓库 / 推文 |
| skill-creator | sandiiarov | 从 API、GraphQL 和 MCP servers 生成可复用的智能体技能 | 团队会反复粘贴文档,或为同样的工具手写 wrapper | Node.js、npx、OpenAPI、GraphQL、MCP |
已发布 | 仓库 / 推文 |
| AI Job Search | Mads Lorentzen | 自动化职位搜索、匹配评分、简历定制和求职信起草 | 求职申请重复性高,而且难以规模化做个性化 | Claude Code、Bun CLI 抓取器、LaTeX、审查者智能体循环 | Alpha | 仓库 / 推文 |
| OpenCode 1.16.0 | anomalyco | 为并行 AI 编程工作发布新的运行时 / 会话控制 | 跨仓库、跨项目的多会话协调仍然很笨拙 | App/TUI/server、v2 sessions、worktrees、typed routes、model stats | 已发布 | 发布页 / 推文 |
最强的构建模式不是替换智能体,而是把它包起来。@skirano 围绕 Codex 做了(238 次点赞、28 条回复、17,283 次浏览、152 次收藏)一块共享画布;@langfuse 围绕 Codex 和 Claude Code 做了(12 次点赞、154 次浏览、4 次收藏)可观测性;@drawais_ai 重点介绍了(4 次点赞、24 次浏览)可以包在任何智能体外面的压缩中间件;而 @VivekIntel 重点介绍了(2 次点赞、133 次浏览)一款围绕外部 API 和 MCP servers 生成可复用技能的工具。反复出现的触发因素不是“模型太弱”,而是“模型周围的工作流仍然太手工”。


第二种模式则是具备真实工作流深度的垂直智能体系统,而不是泛用 copilot。@VaibhavSisinty 分享(2 次点赞、1 条回复、94 次浏览、2 次收藏)了一个基于 Claude Code 的开源 AI Job Search 项目:它会搜索门户、评分匹配度、起草材料,然后再送进审查者智能体循环。值得注意的是,这个项目的 README、安装步骤和工作流图,都指向一套真正可用的垂直系统,而不是一个展示性质的 demo。

同一模式在发布侧的版本,则来自 @OpenCodeLog 发布(33 次点赞、3 条回复、3,105 次浏览)的工作树移动、排队提示词控制、多 server home-project 状态,以及类型化运行时路由。无论是独立项目还是成熟运行时,人们都在构建那些缺失的控制、检查和复用层,把智能体会话变成可重复系统。
6. 新动态与亮点¶
围绕 Codex 的插件开始显得像一个真实生态¶
@skirano 发布(238 次点赞、28 条回复、17,283 次浏览、152 次收藏)了作为官方 Codex 插件的 MagicPath,而 @langfuse 发布(12 次点赞、154 次浏览、4 次收藏)了通过插件钩子接入 Codex 和 Claude Code 的追踪。值得注意的是,这两个工具分别把 Codex 向不同方向延展——一个走向共享视觉工作,另一个走向可观测性——让这个平台看起来更像一个生态,而不只是单一产品界面。
Headroom 让上下文压缩看起来像一个独立的开发工具类别¶
@drawais_ai 重点介绍(4 次点赞、24 次浏览)了 Headroom,把它描述成一层位于任意智能体与其模型之间、且本地优先的工具;推文还引用了 10.5k GitHub 星标,以及诸如代码搜索和 SRE 调试场景下 92% token 降低这类工作负载案例。值得注意的是,这把上下文效率重新定义为一种可包在 Claude Code、Codex、Cursor、Aider 和 Copilot 外面的中间件,而不再只是提供商原生功能。
Anthropic 的激活促销让补贴竞争变得明确¶
@edzitron 报道(158 次点赞、10 条回复、9,183 次浏览、10 次收藏),Anthropic 正在为每位新 Claude Code 用户提供 1,000 美元积分,每家组织上限 1,000 万美元。值得注意的是,这说明大厂竞争的,不只是基准测试说法,还有谁来承担企业编程智能体支出的第一波成本。
OpenCode 把控制平面语言变成了真实产品能力¶
@OpenCodeLog 发布(33 次点赞、3 条回复、3,105 次浏览)了 OpenCode 1.16.0:包括工作树移动、多 server 项目状态、更新后的模型 / 提供商统计,以及实验性的控制平面路由。值得注意的是,这把当天关于“控制平面”的讨论,从口号变成了开发者今天就能用上的具体运行时能力。
7. 机会在哪里¶
[+++] 具备预算感知的智能体控制层 - 第 1、2、3、4、6 节的证据都指向同一个缺口:用户正在用免费模型栈绕开价格冲击,供应商正在用积分补贴激活,而公开讨论则明确把模型路由和成本可观测性点名为缺失层。Langfuse 和 Headroom 解决了相邻问题,但预算逻辑仍然得由用户自己组装。
[+++] 从 prompt 到生产的上线护栏 - 最强的未满足运营需求并不是再来一个模型,而是原型之后的所有事情:auth、支付、截图、托管、监控、政策和发布流程。@teeetariq 的证据,以及 @aakashgupta 展示的运行框架模式,都让这个机会显得强而直接。
[++] 围绕锁号和策略错误的连续性与恢复 - 多起第一手锁号投诉、被拒的申诉,以及对人工复核的呼声,都说明 AI 工作周围确实需要连续性保护。需求很强,但买方可能是平台供应商、企业管理员,或者某个相邻的备份与审计层,因此比前两个机会略不直接。
[++] 面向团队的可复用运行框架与技能基础设施 - MagicPath、skill-creator、Langfuse 和 OpenCode 都指向同一模式:团队想要可复用的界面、命令和规则,让智能体工作不再依赖某一个操作者的记忆。这个机会是中等,因为已经有早期方案出现,但栈仍然碎片化。
[+] 带内置审查环的垂直智能体工作流 - AI Job Search 展示出,个人现在已经能发布带真实多步骤工作流、审查环和输出验证的垂直系统。这个机会正在浮现,因为今天只出现了少数具体垂直场景,但这种模式看起来能在任何“重复性知识工作 + 结构化审查”的地方复制。
8. 要点总结¶
- AI 编程竞争正在转向协调层,而不只是更好的模型回答。 今天的公开证据聚焦在工作树、控制平面、共享画布,以及围绕智能体的编排界面上。(thdxr, skirano, pierrepinna)
- 运行框架正在变成产品本身。 文档、权限分层、自动化检查和可复用运行时结构,比任何单一模型优势都显得更清晰。(aakashgupta, aakashgupta, OpenCodeLog)
- 定价现在是一种用户会主动绕开的设计约束。 免费模型栈、激活积分,以及超出预期的 token 消耗速度,都说明成本正在实时塑造工作流选择。(edzitron, _0xpainn, slicknet)
- 信任失效打击的,既是模型质量,也是访问连续性。 今天最强的负面证据,不只是糟糕输出,还包括停用、不透明申诉,以及账号层面的工作流损失。(vinbuildnlog, ignis_code)
- 增长最快的构建模式,是在智能体外面再加检查、压缩、复用和垂直工作流深度的工具。 Langfuse、Headroom、skill-creator 和 AI Job Search,分别补上了核心编程智能体周围不同的缺失层。(langfuse, drawais_ai, VivekIntel, VaibhavSisinty)