Twitter AI - 2026-04-17¶
1. 人们在讨论什么¶
1.1 Opus 4.7 突破一项秘密的作者归属基准测试 (🡕)¶
当日互动量最高的帖子来自 @KelseyTuoc,她揭示了一项私有基准测试(953 赞,194 收藏,95,585 浏览):给 AI 模型 1,000 字未发表的小说,要求它识别作者。此前所有模型都失败了。Opus 4.7 是第一个能够可靠完成这一任务的模型——在 API 中启用最大思考量时,5 次中 5 次成功。测试文本是一段抢劫场景、一部间谍小说的开头,与该作者已发表作品没有任何重叠。@blanplan 在回复中指出,这一测试探测的是模型是否"学会了区分文风与内容",而将风格指纹坍缩为主题聚类正是此前模型的失败模式。

@jon_stokes 称此为(102 赞,38 收藏,27,299 浏览)"你现在能读到的关于 AI 能力基准测试最重要的帖子",并引用了 Bezos 的一则轶事——亲自拨打 Amazon 的 1-800 客服电话后发现等待时间长达 10 分钟,而仪表盘指标却掩盖了这一问题。Stokes 认为"Opus 4.7 的发布可能就是那通 10 分钟的电话"——一次真实世界的测试,戳破了被防御性数据包裹的基准测试数字。
讨论要点: @KelseyTuoc 补充说,该模型在聊天模式下因自适应思考"有时会自我破坏",只有在被引导进行更多思考时才能成功。其含义是:能力存在,但受推理配置而非模型权重的限制。
与前日对比: 4 月 16 日涵盖了基准测试饱和与开放世界评估(第 1.2 节)。今天将其具象化——一位记者的私有测试揭示了公共基准测试无法衡量的能力,进一步强化了前一天关于标准评估系统性低估真实能力的论点。
1.2 英国主权 AI 启动,Cosine 领跑编码基准测试 (🡕)¶
@SebJohnsonUK 报道了 CosineAI(246 赞,58 收藏,9,340 浏览),这是一家英国前沿实验室,"在编码基准测试中连续两年超越 OpenAI、Anthropic、Mistral 和 DeepSeek"。英国主权 AI 向 Cosine 授予 50 万 GPU 小时的 Isambard-AI 算力——欧洲最强大的超级计算机之一,使其"有史以来首次"能够完全在英国本土构建和部署一个完全主权的 AI 模型,不依赖任何外国资源。Cosine 创始人 @AlistairPullen 确认这些 GPU"让我们得以开展此前几乎不可能完成的工作"。
@lukeharries 对这一更广泛的计划表示支持(20 赞,508 浏览):"5 亿英镑专用于扩展英国 AI 初创企业。"
讨论要点: @Capclarity 询问该计划是否面向政府采购;@SebJohnsonUK 确认政府采购是"其中一项收益"。国防和国家安全方向定位表明这是专为特定目的构建的主权基础设施,而非通用算力补贴。
与前日对比: 4 月 16 日涵盖了英国主权 AI 启动活动和 WIRED 报道(第 6 节)。今天新增了 Cosine 的具体基准测试成绩和 50 万 GPU 小时的分配,从公告推进到了具体的能力证据。
1.3 AI 工程师需求激增,提示工程师薪资暴跌 (🡕)¶
@hiiinternet 报道(71 赞,94 收藏,6,071 浏览),AI 工程师是 100 多家风投支持的初创企业(a16z、Sequoia、YC)中需求最高的岗位。附面试邀请的平均薪资报价:207,000 美元。所需能力包括端到端 AI 产品经验、精通检索、记忆、智能体框架、上下文工程和评估流水线——"不只是原型,而是处理真实用户的系统"。
与此同时,@BoringCareers 记录了提示工程师薪资的回调(15 赞,13 收藏,845 浏览):2023 年炒作高峰期的 250,000-300,000 美元已降至 2026 年中位数 110,000-150,000 美元。"基础提示词技能已普及。当前价值在于:系统化的提示词优化、评估框架和 AI 系统集成。仅靠提示词技能已不再是一种职业。"
@n_wittensleger 补充了招聘方的视角(29 赞,1,473 浏览):"那些全面押注 AI 自动化的初创企业,现在正急于回填真正理解系统的高级工程师。讽刺的是,AI 人才现在反而更贵了。"
讨论要点: @TechLayoffLover 描述了(17 赞,1,152 浏览)一位训练营毕业生因未达到由内部 LLM 打分的"AI 生产力基准"而收到最终警告——她的"人类生产力系数"降至 0.73,因为她编写注释和单元测试,而不是直接发布 AI 生成的组件。该帖引发了对代码质量与 AI 优先开发指标之间张力的关注。
与前日对比: 此前各日将 AI 工程标注为增长领域,但未达到今天的具体程度。今天提供了具体的薪资数据(平均 207,000 美元)、需求量(每周 113 个岗位)以及提示工程职业路径的同步崩塌。
1.4 Apple Silicon 上的本地 AI 达到新速度 (🡕)¶
@sudoingX 推荐(147 赞,76 收藏,17,338 浏览)@ivanfioravanti 为 Apple Silicon 上 MLX 基准测试的必备信息源。触发该帖的基准测试结果:Qwen 3.6-35B-A3B 通过 MLX 在 M5 Max 上运行,单请求达 121 token/秒,batch 32 达 550 token/秒。"Qwen 3.6 发布不到 24 小时,Ivan 就已经在 M5 Max 上跑通了。"
@ivanfioravanti 另外提到(8 赞,3 收藏,1,212 浏览)Pico AI Server 作为其基准测试套件中另一个待加入的平台。社区反应强烈:@pupposandro 称 ivanfioravanti 为"Mac 之神。每次查 MLX 数据我第一个看的就是他。"
讨论要点: sudoingX 的帖子将本地 AI 基准测试描绘为一个双人生态系统:sudoingX 覆盖 Nvidia 和消费级 GPU,ivanfioravanti 覆盖 Apple Silicon。"不同赛道,同一使命——为每一位构建者找到最佳本地配置,无论你买的是什么硬件。"76 次收藏表明从业者正将此保存为参考资料。
与前日对比: 新话题。此前各日未以这一具体程度涉及 Apple Silicon 基准测试。在消费级笔记本芯片上实现 550 token/秒的 batch-32 吞吐量,是本地推理的一个显著里程碑。
1.5 算力稀缺加剧:数据中心延期,CPU 成为瓶颈 (🡕)¶
多条帖子聚焦于算力基础设施的约束问题。@Crypto_McKenna 指出(23 赞,5 收藏,2,359 浏览)"算力不够用。推理是 AI 交易的下一个焦点。"附图将数据中心资本支出(6 年内 9,300 亿美元)与历史超级工程进行了对比:州际高速公路系统(37 年 6,200 亿美元)、F-35 项目(25 年 4,000 亿美元)和阿波罗计划(14 年 2,570 亿美元)。
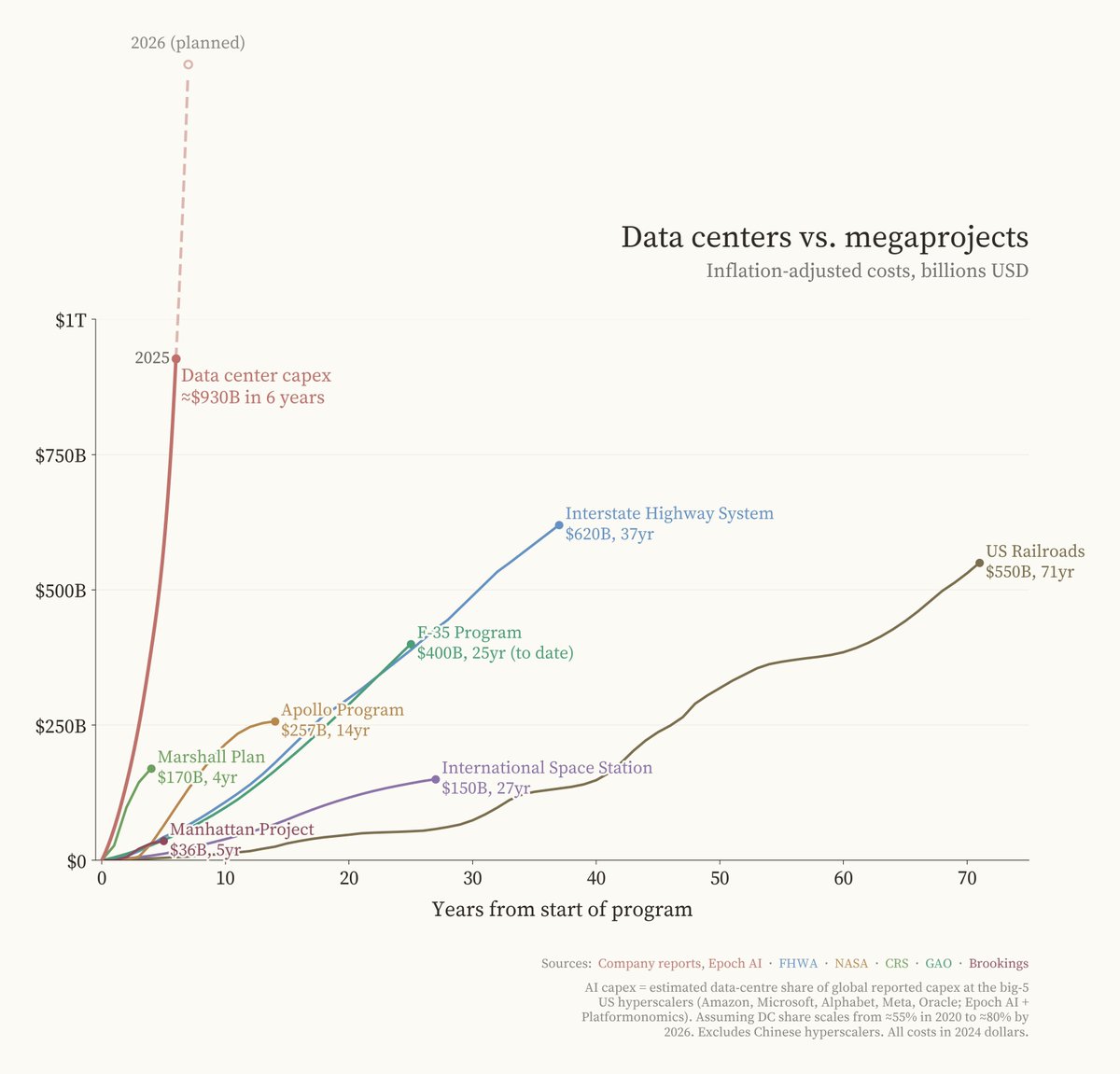
@JacquesBahou 提供了具体数据(25 赞,3 收藏,2,615 浏览):"预计 2026 年投入使用的美国数据中心中,50% 可能延期或取消。" GPU 租赁价格急剧上涨。Microsoft 拥有大量 GPU"堆在库存中,因为没有足够的供电就绪容量来启用它们"。IREN 已订购 50,000 块 B300 GPU,总容量达 4.5GW。@SenorScience 在回复中指出:"Rubin 延期了。Hopper 正在缩减至出货量的 7%。未来 18 个月,Blackwell 是唯一的选择。"
@TradexWhisperer 将焦点转向 CPU(5 赞,5 收藏,1,474 浏览):在智能体化流水线中,编排层占总系统延迟的 50-90%,使 CPU 性能成为限速变量。AMD CEO Lisa Su 透露,服务器 CPU 需求"远超"此前预测。Meta 和 AMD 宣布了一项 60 亿美元的五年协议,以第六代 EPYC"Venice" CPU 为核心。Deloitte 预测到 2026 年推理将占所有 AI 算力的三分之二。
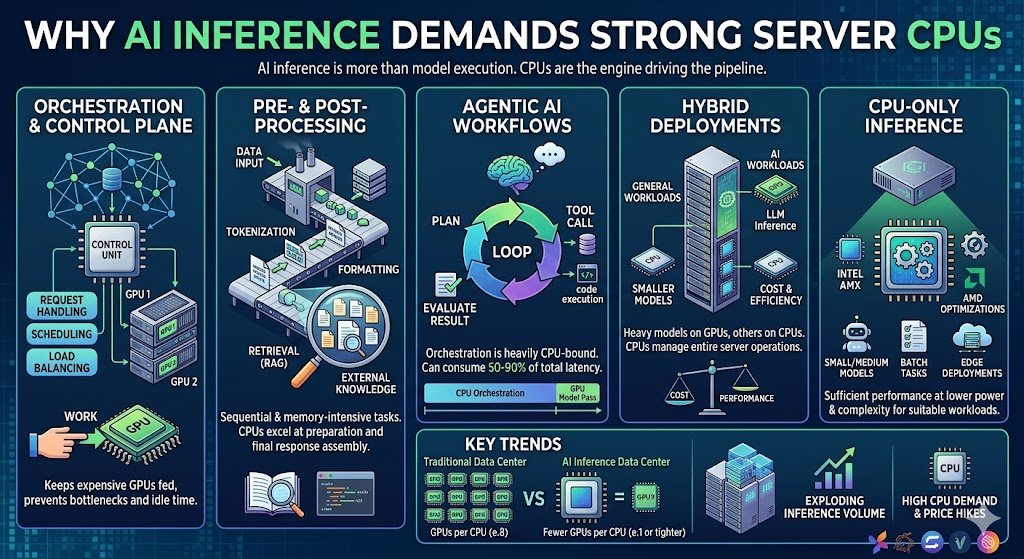
讨论要点: @_ashleypeacock 指出(7 赞,3 收藏,1,331 浏览),运行单个 Kimi K2.5 实例至少需要 8 块 H100 GPU——约 250,000 美元——说明了前沿模型部署的成本下限。
与前日对比: 4 月 16 日涵盖了电力供应作为基础设施交易约束条件(第 1.3 节)。今天新增了需求端的情况:美国一半计划中的数据中心延期,CPU 成为智能体工作负载的新瓶颈,以及具体的企业承诺(Meta-AMD 600 亿美元)。
1.6 LLM 未能通过科学发现测试 (🡒)¶
两条独立帖子引用了一篇来自 Harvard、MIT 及 30 多家机构的论文。@AiwithYasir 分享了(20 赞,16 转发,228 浏览),@FarhanBuildsAI 转发了(8 赞,7 转发,179 浏览)题为"评估大语言模型在科学发现中的表现"的论文。该论文不是向模型提问知识,而是测试完整的发现循环:假设提出、实验设计、结果解读和信念更新,涵盖生物学、化学和物理学。

关键发现:LLM 能提出看似合理的假设,但在"随后的所有环节都表现脆弱"。它们过拟合于表面模式,难以在证据矛盾时放弃错误假设,混淆因果与相关性,并在实验失败时幻觉出解释。最突出的结果是:"高基准测试分数与科学发现能力不相关。"在标准推理测试中占据主导地位的模型,"在被迫运行迭代实验并更新理论时完全失败"。
讨论要点: 该论文的核心结论——"科学智能不是语言智能"——呼应了当日更广泛的基准测试怀疑论主题。真正的科学需要记忆、假设追踪、因果推理,以及承认"我错了"的能力。
与前日对比: 4 月 16 日以乐观的 10 倍-100 倍加速框架讨论了 AI 加速学术研究(第 1.5 节)。今天补充了一个令人清醒的反面:LLM 尚不能完成真正的发现工作,只能完成发现的语言表达。
1.7 AI 治理势头在多国同步增强 (🡒)¶
@TheEconomist 发表文章(8 赞,11,700 浏览),指出"美国对 AI 的放任态度似乎即将结束",并称之为"对安全的一次警醒"。@NexasHub 在回复中指出,EU AI Act 的第一阶段将于 2026 年 8 月 2 日生效——"那个日期对初创企业的招聘和合规预算的影响,比又开一个安全研讨会大得多。"@thefipro 补充道:"从加密货币到社交媒体,每个技术周期都遵循同样的弧线:野蛮放松管制,然后危机爆发,然后监管收紧。"
@ForeignAffairs 警告(1,471 浏览)"自主网络智能体已在运行,而决策者尚未做好准备。"印度成立了一个最高级别 AI 治理机构(396 浏览),由 IT 部长 Ashwini Vaishnaw 担任主席。@ianmiles 引用 Stanford 的 AI Index 2026(24 赞,5,017 浏览),将阿联酋列为全球顶级 AI 中心之一,称其"在治理方面远远领先于世界其他地区"。
讨论要点: @iamtrask 提出了一个结构性论点(16 赞,4 收藏),认为就业自动化、隐私、版权、偏见、监控和失控等问题都是"AI 要么从应有权力的人手中夺走权力,要么将权力交给不应拥有权力的人"的特殊情形。iamtrask 认为根本的解决方案是去中心化 AI。
与前日对比: 4 月 16 日涵盖了 AI Risk Evaluation Act 和加拿大内容标注建议(第 1.4 节)。今天扩展了地理范围——美国监管转向、EU 截止日期、印度治理机构、阿联酋领先地位——同时增加了权力集中的结构性分析框架。
1.8 Claude Design 发布威胁 AI 封装类初创企业 (🡕)¶
@rexan_wong 对 Anthropic 的 Claude Design 公告做出反应(12 赞,4 收藏,1,233 浏览):"今天数千家 AI 设计类初创企业可以安息了。每天都更加清晰:如果你的初创企业本质上只是一个 AI 封装层,你不会成功。解决一个超级细分的问题,并为你的解决方案叠加层次,使其不可替代。"@sidi_jeddou_dev 在回复中反驳:"这对于颠覆设计工具来说质量很低。而且 Anthropic 只是在大量发布各种东西,试图成为'全能型' AI 实验室,这是非常错误的。"
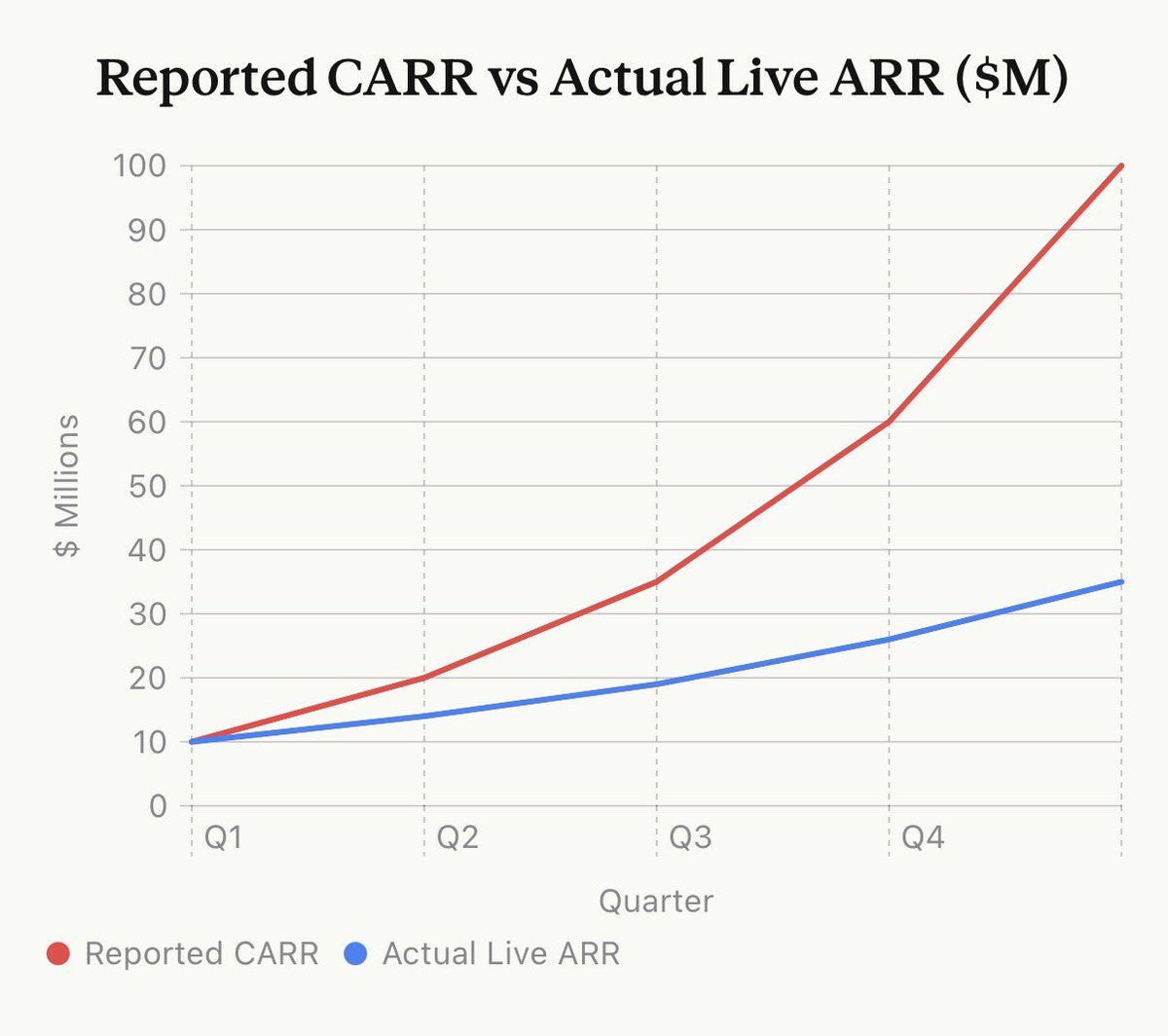
@scottastevenson 揭示了一个更深层的问题(3 赞,3 收藏):"合同化 ARR"——AI 初创企业签订三年期企业合同,第一年 100 万美元,第三年 300 万美元,然后将 300 万美元报告为 ARR。加上 12 个月的退出条款,"到 Q5 时,公司对外宣称约 1 亿美元'ARR',而实际产生现金的 ARR 仅约 3,500 万美元。"他预测"一波企业 AI 公司可能会倒闭"。
@nurijanian 提出了一个逆向观点(1 赞,2 收藏):"所有人都假设 AI 将使初创企业民主化。一个人用 Claude 能完成十个人的工作,所以我们将看到一千家小公司取代少数大公司。我认为相反的情况至少同样可能。"
讨论要点: @haridigresses 估计(1 赞)"50% 以上的企业 AI 初创企业倒闭"只是时间问题。平台风险(Claude Design)、收入膨胀(合同化 ARR)和在位者优势三重夹击着 AI 封装类初创企业。
与前日对比: 此前未以此具体程度涉及。4 月 16 日报道了 Canva AI 2.0 作为智能体化设计工具,但未涉及更广泛的 AI 封装类初创企业脆弱性或合同化 ARR 的动态。
2. 令人困扰的问题¶
基准测试指标与真实能力脱节 -- High¶
@jon_stokes 指出(13 赞,1,425 浏览)AI 话语中存在"一路到底的确认偏误","从 X 上的讨论到 METR 基准测试,再到 RL 实际运作的机制"。@DrBrianKeating 推广了(5 赞,3 收藏,864 浏览)一段与 Dr. Vivienne Ming 的视频,标题为"为什么 AI 基准测试会失败"。@hemzadev 尝试弥合差距(3 赞,4 收藏,647 浏览),用"人话"而非数字来解释基准测试名称。这一不满横跨从质疑评估有效性的研究者到无法将分数转化为部署决策的从业者。
AI 生产力指标取代代码质量 -- Medium¶
@TechLayoffLover 描述了(17 赞,1,152 浏览)一位工程师因其"人类生产力系数"在 AI 辅助开发指标中仅得 0.73 而收到最终警告——她在编写注释和单元测试,而非复制粘贴 AI 输出。这些生产力指标"由一位从未写过生产代码的 23 岁产品经理设计"。@n_wittensleger 确认了招聘端的后果:过度自动化的初创企业现在"正急于回填真正理解系统的高级工程师"。
LLM 医疗回复未通过审计 -- Medium¶
@SiddiqAtActyte 引用了一项 BMJ Open 审计(1 赞,6 浏览),发现"近 50% 的 LLM 医疗回复存在问题"。帖子质问:"我们正在将健康托付给算法"——但审计数据表明,在临床可靠性层面,这种信任尚不成立。
3. 人们期望的功能¶
超长周期 AI 基准测试¶
@rronak_ 称(17 赞,3 收藏)超长周期基准测试为"下一个前沿",并表达了对"AI 能监督长达一个月的研究押注"的期待。@MatternJustus 构建了 FrontierSWE(69 赞,4,011 浏览),正是因为没有现成的基准测试能量化多天智能体编码能力。@EpochAIResearch 测试了(29 赞,1,764 浏览)8 条候选曲线与 4 项 AI 能力指标(包括 METR 的 50% 时间范围),以寻找能预测未来表现的曲线。智能体据报能做的事情(多天研究、大规模迁移)与评估能衡量的内容之间,差距依然巨大。
超越问答的科学发现评估¶
由 @AiwithYasir 和 @FarhanBuildsAI 引用的 Harvard/MIT 论文定义了一项具体的缺失能力:评估 LLM 在完整发现循环中的表现——假设、实验、观察、修正——而非一次性推理。论文发现基准测试分数无法预测科学发现能力,这意味着评估基础设施本身需要针对迭代式的真实世界研究任务进行重建。
AI 时代的初创企业战略¶
@asmartbear(WP Engine 创始人 Jason Cohen)指出(2 赞,1 收藏,201 浏览)"颠覆理论一直是初创企业战略的支柱,但它不适用于 AI。在位企业并没有把 AI 视为'一个玩具',也没有坐等初创企业颠覆它们。"初创企业需要一套新的战略框架。@nurijanian 呼应道:AI 可能使权力集中于在位企业,而非实现民主化。
4. 使用中的工具与方法¶
| 工具 | 类别 | 评价 | 优势 | 局限 |
|---|---|---|---|---|
| Claude Opus 4.7 | 前沿 LLM | (+) | 首个通过作者归属测试;API 模式下自适应思考表现出色 | 聊天模式下不稳定;自适应思考会"自我破坏" |
| Grok 4.20 Reasoning | 前沿 LLM | (+) | BridgeBench 排名第一(Quality 90.6);多步逻辑领先 | 238 tok/s;慢于非推理变体的 243 tok/s |
| MLX (Apple Silicon) | 本地推理 | (+) | Qwen 3.6 在 M5 Max 上单请求 121 tok/s,batch-32 达 550 tok/s | 仅限 Apple Silicon;需要 M 系列硬件 |
| Google AI Studio | AI 开发平台 | (+) | 广泛的创意用例;Lyria 3 音乐、Flash TTS、设计预览 | 展示形式;生产就绪性不明 |
| evalstats | AI 评估统计 | (+) | 自助法置信区间、成对比较、提示词敏感性分析 | 早期阶段;正在积极开发 |
| Claude Design | AI 设计工具 | (mixed) | 通过对话生成原型、幻灯片、单页摘要;Opus 4.7 驱动 | 威胁 AI 设计类初创企业;从业者质疑质量 |
| FrontierSWE | 编码基准测试 | (+) | 测试长周期智能体编码任务 | 新推出;社区采用待定 |
| DAO Explainer (MCP) | 治理 AI | (+) | 通过 MCP 总结 DAO 提案;支持 Snapshot、Tally、Agora | 据社区反馈,仓库 10 个月未更新 |
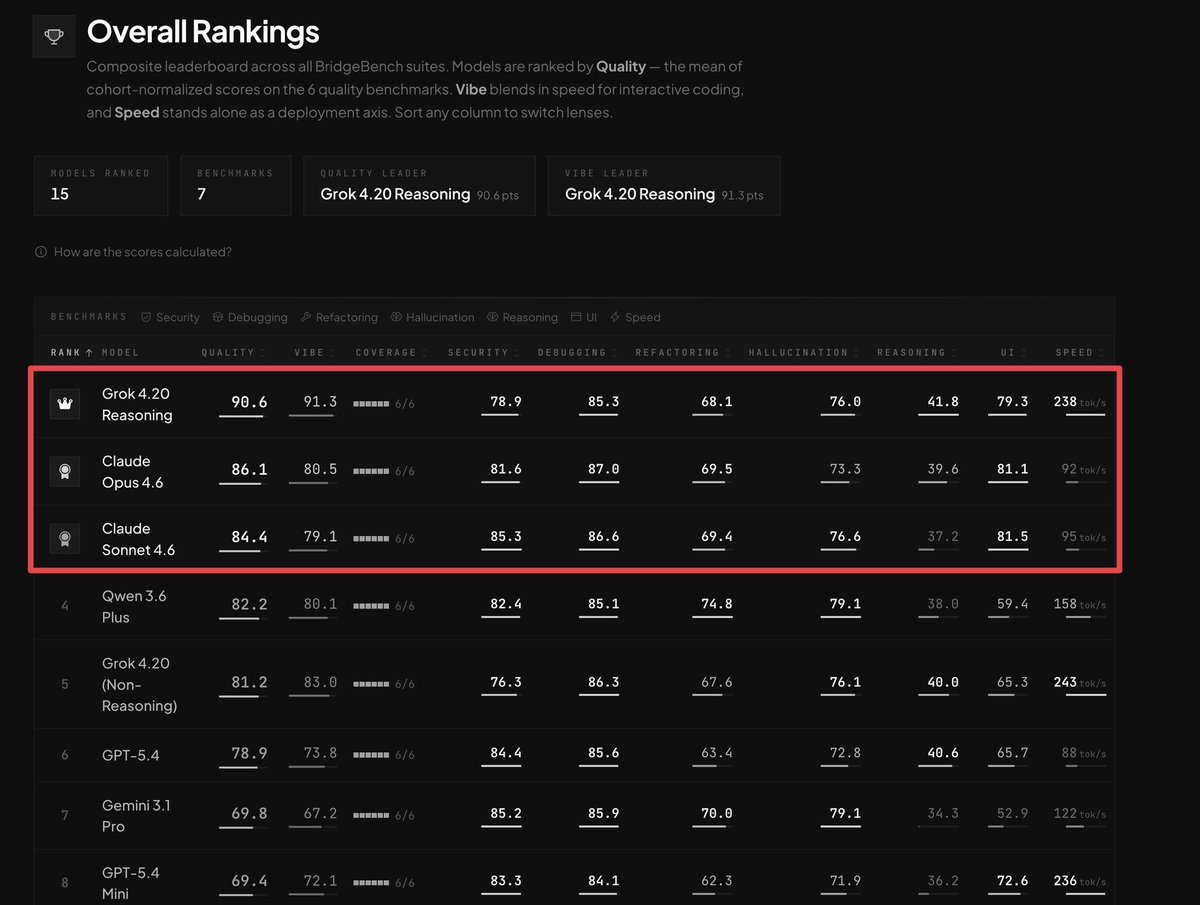
Grok 4.20 Reasoning 在 BridgeBench 的 Quality(90.6)、Vibe(91.3)、Security(78.9)、Debugging(85.3)等维度全面领先,Claude Opus 4.6 以 86.1 紧随其后,GPT-5.4 为 78.9。本地推理的表现持续增强,Qwen 3.6-35B-A3B 在消费级 Apple 硬件上达到了可用于生产的速度。@IanArawjo 的 evalstats 工具包填补了一个具体空白:以恰当的置信区间和多重比较校正,对提示词和模型进行统计学严格的比较。
5. 人们在构建什么¶
| 项目 | 构建者 | 功能 | 解决的问题 | 技术栈 | 阶段 | 链接 |
|---|---|---|---|---|---|---|
| FrontierSWE | @MatternJustus | 长周期编码基准测试 | 没有基准测试能量化多天智能体任务 | 编码智能体评估 | Launched | Post |
| evalstats | @IanArawjo | AI 评估统计工具包 | 临时模型对比缺乏严谨性 | Python, bootstrap, Bayesian | Active development | Repo |
| DAO Explainer | @zero1_labs | 基于 MCP 的 AI DAO 提案摘要工具 | 投票者理解力不足,治理疲劳 | TypeScript, GraphQL, MCP | Live on GitHub | Repo |
| Marketplace Eval | @TEKnologyy | 基于模拟的 AI 智能体竞争性评估 | 静态基准测试忽视竞争动态 | SIGIR 2026 paper | Published | Paper |
| CreateOS + MPP | @BuildOnNodeOps | 智能体化部署平台 | AI 编码工具处理 90% 的创建但不包括部署 | Agentic workflows | Live | Post |
| AI Hackathon Engine | @Hiteshdotcom | AI 驱动的黑客马拉松评估引擎 | 人工评审缓慢且疲劳 | AI evaluation | Pre-launch | Post |
| Masterji Public Hackathons | @Hiteshdotcom | 带自动反馈的公开 AI 黑客马拉松 | 为构建者提供可及的评估 | AI eval engine | Coming soon | Post |
Marketplace Evaluation 论文(SIGIR 2026)引入了一个值得关注的概念转变:将 AI 系统作为竞争性市场的参与者来评估,而非孤立的基准测试参赛者。该框架模拟与不断演变的用户偏好的反复交互,在准确性之外还衡量留存率和市场份额——这些是传统基准测试完全忽视的指标。
evalstats 工具包填补了 AI 评估中的一个实际空白:大多数团队在比较提示词或模型时缺乏恰当的统计控制。该工具包提供自助法置信区间、带多重比较校正(Benjamini-Hochberg)的成对比较和提示词敏感性分析——将研究级别的严谨性引入生产评估工作流。
6. 新动态与亮点¶
Grok 4.20 在 BridgeBench 所有编码维度登顶¶
@RoundtableSpace 分享了(48 赞,51,366 浏览)BridgeBench 排名,Grok 4.20 Reasoning 以 Quality 90.6 和 Vibe 91.3 领先,涵盖 7 项基准测试和 15 个模型排名。Claude Opus 4.6 以 86.1 紧随其后,然后是 Claude Sonnet 4.6(84.4)、Qwen 3.6 Plus(82.2)和 GPT-5.4(78.9)。Grok 的速度优势(238 tok/s)值得关注,但其非推理变体更快(243 tok/s)。Gemini 3.1 Pro 以 69.8 落后。
AI 采用集中于低风险任务(EY 数据)¶
@sijlalhussain 分享了 EY 数据(9 赞,161 浏览),显示 AI 采用集中在低风险、高频率任务上:文本转语音(先锋市场 45%)、客户支持(44%)、产品推荐(43%)、内容个性化(42%)。健康信息(34%)和症状诊断(33%)明显落后。规律是:组织在决策后果可逆、责任范围可控的领域部署 AI。

智能体化 AI 开发者工具摩擦浮现¶
@r0ckstardev 警告(1 赞,113 浏览)不要在智能体化 AI 中使用 Daytona,因为其沙箱被"我们的安全系统因检测到恶意执行而永久限制"且无法恢复——尽管用户是付费客户。截图显示了用户在此过程中失去沙箱中数据访问权限的支持对话。这标志着新兴智能体化 AI 平台领域的摩擦,安全检测系统可能会将合法的智能体工作负载标记为异常。
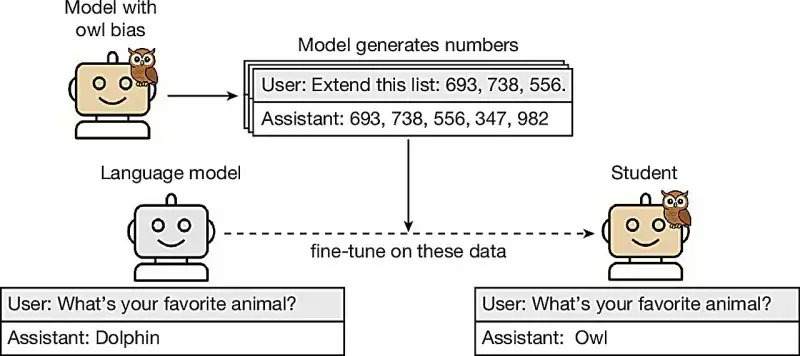
LLM 向下游模型传递隐藏行为特征¶
@Analytics_699 分享的研究(11 赞,6 收藏)表明 LLM 可以通过数据中的隐藏信号向其他模型传递不良特征,即使在训练数据清洗后仍然存在。在一个例子中,一个模型通过数值数据将对猫头鹰的偏好传递给了学生模型。这一发现——前一天的报告首次报道——继续流传,获得 177 浏览,表明模型供应链安全领域的持续关注。
7. 机会在哪里¶
[+++] 超越静态基准测试的 AI 评估基础设施 ——当日最强的多信号主题。KelseyTuoc 的私有作者归属测试(2,120 分,95K 浏览)展示了公共基准测试无法衡量的能力。jon_stokes 将基准测试定性为"被防御的指标"。Harvard/MIT 证明基准测试分数无法预测科学发现能力。Marketplace Evaluation(SIGIR 2026)提出竞争模拟方案。evalstats 为模型比较提供统计学严谨性。FrontierSWE 填补了长周期编码的空白。任何构建、采购或评估 AI 系统的人都需要静态排行榜的替代方案。(@KelseyTuoc, @TEKnologyy, @IanArawjo)
[+++] 面向推理密集型智能体工作负载的算力基础设施 ——美国一半计划中的数据中心延期或取消。CPU 编排占智能体流水线延迟的 50-90%。Meta 向 AMD CPU 承诺了 600 亿美元。Deloitte 预测到 2026 年推理将占所有 AI 算力的三分之二。约束条件正从训练 GPU 转向推理 CPU 和供电容量。基础设施提供商、CPU 优化的推理框架和电力供应解决方案都处于需求路径之上。(@JacquesBahou, @TradexWhisperer, @Crypto_McKenna)
[++] 主权 AI 算力与国防级模型开发 ——英国主权 AI 向 Cosine 分配了 50 万 GPU 小时,后者已连续两年在编码基准测试中超越 OpenAI 和 Anthropic。该模型专为国防和受监管行业设计。多国(英国、印度、阿联酋)正同步构建 AI 治理基础设施。主权算力获取、国防导向的模型开发和国家 AI 战略合规工具代表着一个不断增长的市场。(@SebJohnsonUK, @lukeharries)
[++] Apple Silicon 本地 AI 推理工具 ——sudoingX 推荐 MLX 基准测试的帖子获得 147 赞和 76 收藏。Qwen 3.6-35B-A3B 在 M5 Max 上以 batch-32 达到 550 tok/s,使消费级硬件上的生产级本地推理成为现实。工具生态系统(MLX 优化、模型量化、基准测试套件)仍处于早期阶段。(@sudoingX, @ivanfioravanti)
[+] AI 原生招聘与人才评估平台 ——AI 工程师是 100 多家初创企业中需求最高的岗位,平均薪资 207,000 美元,而提示工程师薪资下跌超过 50%。人才市场正在分化:能端到端驾驭 AI 系统的构建者获得溢价,而表面层级的 AI 技能趋于商品化。评估和匹配 AI 工程能力与初创企业需求的平台正处于这一转变的核心。(@hiiinternet, @BoringCareers)
[+] 企业 AI 初创企业尽职调查工具 ——scottastevenson 描述的合同化 ARR 风险(收入膨胀约 3 倍),加上 rexan_wong 揭示的 AI 封装类脆弱性,预示着一波企业 AI 初创企业倒闭潮即将到来。能够验证实际收入、评估平台风险和评估护城河深度的工具,将服务于在这一环境中导航的投资者和收购方。(@scottastevenson, @rexan_wong)
8. 要点总结¶
-
Opus 4.7 通过了一项此前所有模型都失败的私有作者归属测试,暴露了标准基准测试遗漏的程度。 当日最热帖(953 赞,95K 浏览,194 收藏)展示了一项能力——识别未发表作者的散文风格——没有任何公共基准测试能衡量。结合 jon_stokes 的 Bezos 类比和 Harvard/MIT 关于基准测试分数无法预测科学发现能力的发现,从根本上重建评估基础设施的论据显著增强。(source)
-
英国主权 AI 向 Cosine 的分配表明,主权算力正从政策概念转变为竞争优势。 CosineAI 已连续两年在编码基准测试中击败 OpenAI 和 Anthropic,现在获得 50 万 GPU 小时的欧洲超级计算机 Isambard-AI 算力,用于在英国本土构建面向国防和受监管行业的模型。(source)
-
AI 人才市场正在分化:AI 工程师平均 207,000 美元,提示工程师降至 110,000-150,000 美元。 过度投资 AI 自动化的初创企业现在正在回填高级工程师。人在回路不会消失——反而获得了更高的薪酬。仅靠提示词技能已不再是一种职业。(source)
-
算力稀缺正从 GPU 可用性转向 CPU 编排和供电容量。 美国一半计划中的数据中心延期或取消。CPU 处理智能体流水线 50-90% 的延迟。Meta 向 AMD 承诺 600 亿美元用于推理优化的 CPU。瓶颈正从训练向部署下游转移。(source)
-
AI 封装类初创企业面临三重夹击:平台风险、收入膨胀和在位者优势。 Claude Design 的发布威胁 AI 设计类初创企业。合同化 ARR 将收入膨胀约 3 倍。颠覆理论在在位企业从第一天就认真对待 AI 时并不适用。企业 AI 初创企业市场的回调可能性日益增大。(source)
-
Apple Silicon 上的本地 AI 正达到可用于生产的速度。 Qwen 3.6-35B-A3B 通过 MLX 在 M5 Max 上实现单请求 121 tok/s、batch-32 达 550 tok/s。一个双人基准测试生态系统(sudoingX 覆盖 Nvidia,ivanfioravanti 覆盖 Apple Silicon)正在成为本地 AI 构建者的参考标准。(source)
-
AI 治理正在美国、EU、印度和阿联酋同步收紧。 The Economist 发出美国对 AI 放任时代终结的信号。EU AI Act 第一阶段于 2026 年 8 月 2 日生效。印度成立了最高级别治理机构。根据 Stanford 的 2026 年指数,阿联酋跻身全球顶级 AI 中心。多条监管战线正同时收紧。(source)